Популярные веб-архивы и их применение
Содержание:
- Проекты
- Проекты
- «Послужной список» АЗАПИ
- Где можно найти сторис в мобильной версии ВК?
- Блокировка Архива Интернета
- Методы сбора
- archive.md
- Поиск сайтов в Wayback Machine
- Качаем сайт с web.archive.org
- Что такое веб-архив?
- Качаем сайт с web.archive.org
- Основная цель проекта
- Уникальный контент из «мертвых» сайтов
- Качаем сайт с web-arhive.ru
- Мнения в Сторис
- Всемирный Веб архив сайтов интернета
- Борьба с добром и российской судебной практикой
- Возможности использования веб-архивов
Проекты
Wayback Machine
Логотип Wayback Machine
The Wayback Machine — веб-сервис Архива. Содержание веб-страниц время от времени фиксируется c помощью бота или при ручном указании посетителем сайта адреса страницы для фиксации. Таким образом, можно посмотреть, как выглядела та или иная страница раньше, даже если она больше не существует.
Легальность
На сервис не раз подавались судебные иски в связи с тем, что публикация контента может быть нелегальной. Поэтому сервис удаляет материалы из публичного доступа по требованию их правообладателей или, если доступ к страницам сайтов не разрешён в файле robots.txt владельцами этих сайтов.
Книга, изготовленная в течение 20 минут в рамках проекта Book-on-demand, на основе электронной книги из Архива
В 2002 году часть архивных копий веб-страниц, содержащих критику саентологии, была удалена из архива с пояснением, что это было сделано по «просьбе владельцев сайта». В дальнейшем выяснилось, что этого потребовали юристы Церкви саентологии, тогда как настоящие владельцы сайта не желали удаления своих материалов. Некоторые пользователи сочли это проявлением интернет-цензуры.
Сервис веб-архива может использоваться в качестве меры борьбы с блокировками доступа к Интернет-сайтам: как и сервис кэшированных копий страниц от поисковых систем, архив Интернета позволяет ознакомиться с более ранними копиями популярных страниц. Однако использование архива и кэшей в таких целях требует специальных усилий от пользователя и позволяет получить доступ не ко всем сайтам.
Open Library
Книжный сканер Архива
Open Library — общественный проект по сканированию всех книг в мире, к которому приступила Internet Archive в октябре 2005 года. На февраль 2010 года библиотека содержит в открытом доступе 1 миллион 165 тысяч книг, в каталог библиотеки занесено больше 22 млн изданий. По данным на 2008 год, Архиву принадлежат 13 центров оцифровки в крупных библиотеках. По оценке Internet Archive на ноябрь 2008 года, коллекция составила более 0,5 петабайта, включая изображения и документы в формате PDF. Коллекция постоянно растёт, так как библиотека сканирует около 1000 книг в день.
Scan-on-demand — бесплатная оцифровка желаемых публикаций из фондов Бостонской общественной библиотеки, относится к проекту «Открытая библиотека».
Собрание фильмов, аудио, текстов и программного обеспечения, которые являются общественным достоянием или распространяются под лицензией Creative Commons.
Проекты
Wayback Machine
Логотип Wayback Machine
The Wayback Machine — веб-сервис Архива. Содержание веб-страниц время от времени фиксируется c помощью бота или при ручном указании посетителем сайта адреса страницы для фиксации. Таким образом, можно посмотреть, как выглядела та или иная страница раньше, даже если она больше не существует.
Легальность
На сервис не раз подавались судебные иски в связи с тем, что публикация контента может быть нелегальной. По этой причине сервис удаляет материалы из публичного доступа по требованию их правообладателей или, если доступ к страницам сайтов не разрешён в файле robots.txt владельцами этих сайтов.
Книга, изготовленная в течение 20 минут в рамках проекта Book-on-demand, на основе электронной книги из Архива
В 2002 году часть архивных копий веб-страниц, содержащих критику саентологии, была удалена из архива с пояснением, что это было сделано по «просьбе владельцев сайта». В дальнейшем выяснилось, что этого потребовали юристы Церкви саентологии, тогда как настоящие владельцы сайта не желали удаления своих материалов. Некоторые пользователи сочли это проявлением интернет-цензуры.
Сервис веб-архива может использоваться в качестве меры борьбы с блокировками доступа к сайтам: как и сервис кэшированных копий страниц от поисковых систем, Архив Интернета позволяет ознакомиться с более ранними копиями популярных страниц. Однако использование Архива и кэшей в таких целях требует специальных усилий от пользователя и позволяет получить доступ не ко всем сайтам.
Open Library
Основная статья: Open Library
Книжный сканер Архива
Open Library — общественный проект по сканированию всех книг в мире, к которому приступила Internet Archive в октябре 2005 года. На февраль 2010 года библиотека содержит в открытом доступе 1 миллион 165 тысяч книг, в каталог библиотеки занесено больше 22 млн изданий. По данным на 2008 год, Архиву принадлежат 13 центров оцифровки в крупных библиотеках. По оценке Internet Archive на ноябрь 2008 года, коллекция составила более 0,5 петабайта, включая изображения и документы в формате PDF. Коллекция постоянно растёт, так как библиотека сканирует около 1000 книг в день.
Scan-on-demand — бесплатная оцифровка желаемых публикаций из фондов Бостонской общественной библиотеки, относится к проекту «Открытая библиотека».
Собрание фильмов, аудио, текстов и программного обеспечения, которые являются общественным достоянием или распространяются под лицензией Creative Commons.
«Послужной список» АЗАПИ
АЗАПИ была основана в мае 2013 г. издательствами АСТ и «Эксмо», которые на тот момент были ее единственными учредителями. Через общего владельца АЗАПИ родственна книжному онлайн-магазину «Литрес».
«Архив интернета» — не первая цель АЗАПИ в борьбе за интеллектуальную собственность. К примеру, в сентябре 2013 г. была заблокирована популярная в России электронная библиотека «Флибуста». Бывший глава Ассоциации защиты авторских прав в интернете Олег Колесников в разговоре с CNews признал, что «нынешняя неработоспособность «Флибусты» случилась благодаря его ассоциации». К слову, в тот же день «Флибуста» сумела прорвать блокировку и вновь стала доступной всем пользователям. На 23 августа 2019 г. эта библиотека была включена в список запрещенных в России ресурсов, и доступ в нее без спецсредств был закрыт окончательно.
В январе 2014 г. АЗАПИ пошла войной на торрент-трекер «Рутрекер» (навечно заблокирован в России с ноября 2015 г.) и начала готовить против него иск. Причиной стали поддерживаемые трекером раздачи архивов электронных библиотек «Флибуста» и «Либрусек», затрагивающие интересы основателей АЗАПИ, издательств «Эксмо» и АСТ. В августе 2016 г. «Эксмо» при содействии АЗАПИ попыталось через Мосгорсуд заблокировать доступ к «Яндексу» из-за ссылок в поисковой выдачи на скачивание книг из Rutracker. Однако Мосгорсуд отклонил это требование, поскольку доступ к Rutracker и так заблокирован.
Несмотря на подозрения в совершении преступления, Максим Рябыко остается главой АЗАПИ
Сам Максим Рябыко, общаясь с прессой, свое задержание категорически опроверг. «Меня никто не задерживал, я не знаю, откуда появилась такая информация», — заявил он, пояснив, что «узнал о своем задержании из СМИ». На 23 августа 2019 г. Рябыко по-прежнему находился на должности генерального директора АЗАПИ.
- Короткая ссылка
- Распечатать
Где можно найти сторис в мобильной версии ВК?
После того как разработчики приложения внесли опцию сохранения сторис, публикации не удаляются в автоматическом режиме безвозвратно. Сохраняются видеоролики в специальном разделе – архив. Все ваши публикации будут находиться именно в архиве.
Инструкция как открыть архив в мобильной версии ВК:
- Открываем главную страницу вашего профиля, затем кликаем на 3 точки верху экрана.
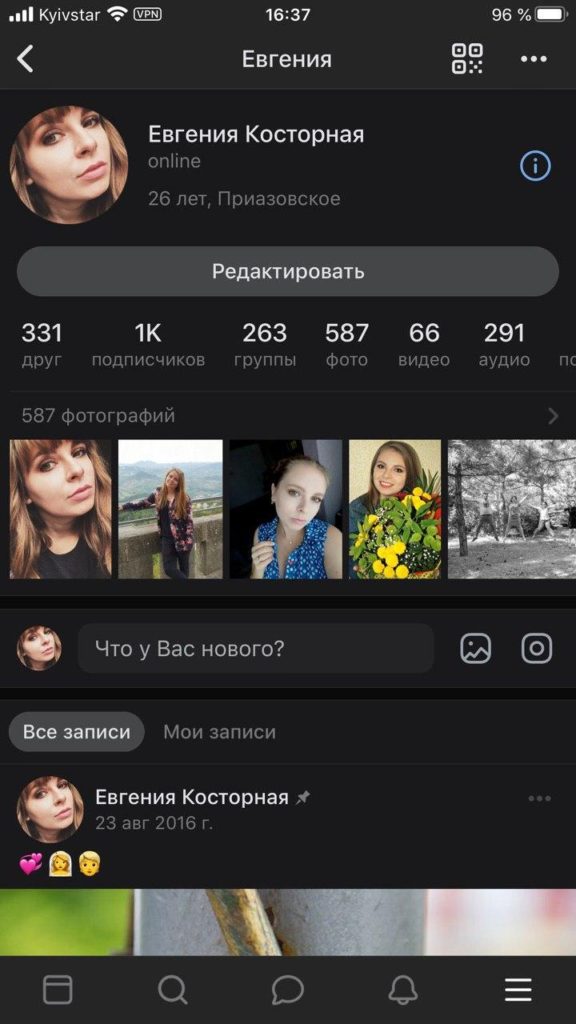
Находим три точки на профиле
- В открытом меню выбираем «Архив историй»;
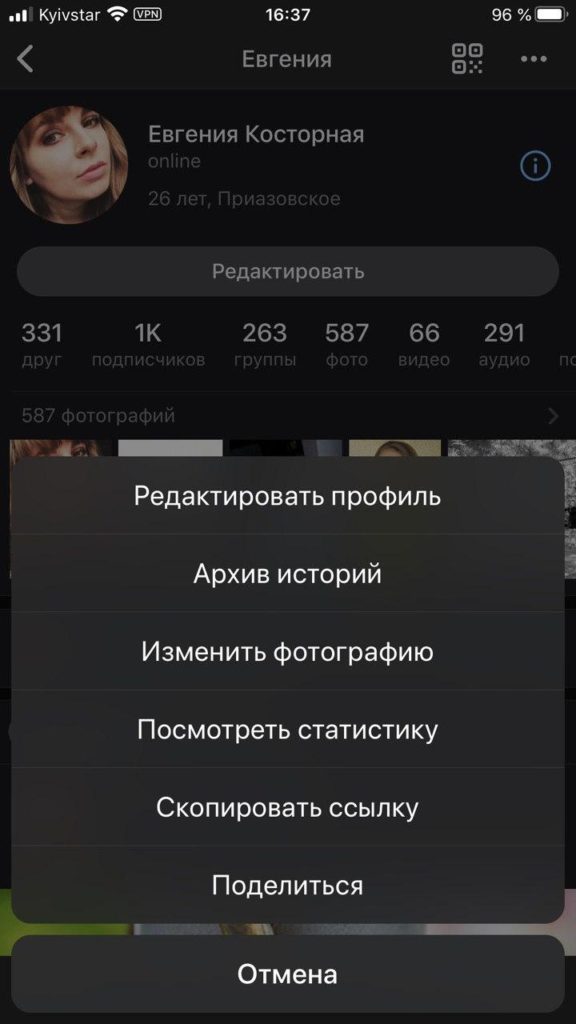
Нажимаем на «Архив историй»
- Загружается список ваших историй за действующий месяц.
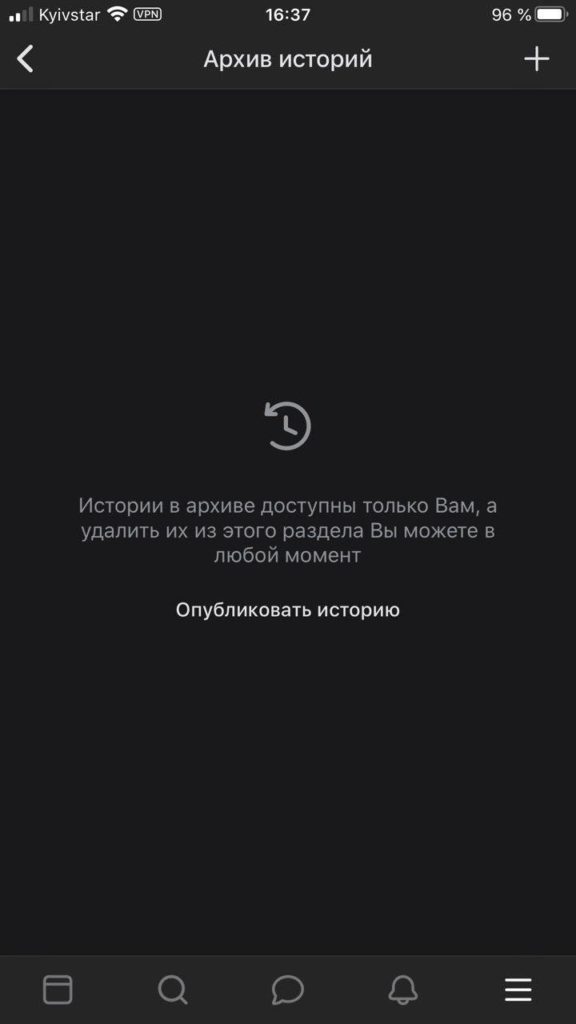
Архив историй
Открывая историю, можно посмотреть, кто видел их, данная информация представлена в качестве иконки в виде глаза. В одном из углов экрана будут размещены 3 точки. Если кликнуть на них появиться меню, как раз из него можно будет и сохранить историю на мобильный телефон.
Блокировка Архива Интернета
В России
| Внешние изображения |
В октябре 2014 года Роскомнадзор заблокировал на территории РФ доступ к некоторым страницам Архива Интернета за видеоролик «Звон мечей» экстремистской группировки «Исламское государство Ирака и Леванта» (нынешнее название — «Исламское государство»). Ранее блокировались только ссылки на отдельные материалы в архиве, однако 24 октября 2014 года в реестр запрещённых сайтов временно был включён сам домен и его IP-адрес.
16 июня 2015 года на основании статьи 15.3 закона «Об информации, информационных технологиях и о защите информации» генпрокуратура РФ приняла решение о блокировке страницы «Одиночный джихад в России», содержащей, по её мнению, «призывы к массовым беспорядкам, осуществлению экстремистской деятельности, участию в массовых мероприятиях, проводимых с нарушением установленного порядка», в действительности на территории России был заблокирован доступ ко всему сайту, кроме .
С апреля 2016 года Роскомнадзор решил убрать сайт из блокировок, и он доступен в России.
В других странах СНГ
Архив блокировался на территории Казахстана в 2015 году.
Также в 2017 году сообщалось о блокировках архива в Кыргызстане.
В Индии
В Индии Архив был частично заблокирован судебным решением в августе 2017 года. Решение Madras High Court перечисляло 2,6 тыс. адресов в сети Интернет, которые способствовали пиратскому распространению ряда фильмов двух местных кинокомпаний. Представители проекта безуспешно пытались связаться с министерствами.
Методы сбора
Существует несколько способов архивирования интернета, ниже описана часть из них.
Удалённый сбор
Метод веб-архивирования отдельных сайтов, автоматизирующий сбор веб-страниц.
Примеры веб-сканеров для персональных компьютеров:
- Heretrix
- HTTrack
- Wget
Онлайн-сервисы веб-сканеров:
- Wayback Machine
- WebCite
Архивирование баз данных
Метод веб-архивирования, который основан на архивированию основного содержания сайта из базы данных.
Таким образом работают системы DeepArc и Xinq, разработанные Национальной библиотекой Франции и Национальной библиотекой Австралии, соответственно. Первая программа позволяет, используя реляционную базу данных, отображать информацию в виде XML-схемы; вторая программа позволяет запомнить оригинальное оформление сайта, соответственно создавая точную копию.
Архивирование транзакциями
Метод архивирования, который сохраняет данные, пересылаемые между веб-сервером и клиентом. Используется, как правило, для доказательств содержания, которое было предоставлено на самом деле в определённую дату. Такое программное обеспечение может потребоваться организациям, которые нуждаются в документировании информации такого типа.
Такое ПО, как правило, просто перехватывает все HTTP-запросы и ответы, фильтруя дубликаты ответов.
archive.md
Адреса данного Архива Интернета:
- http://archive.md
- http://archive.ph/
- http://archive.today/
На главной странице говорящие за себя поля:
- Архивировать страницу, которая сейчас онлайн
- Искать сохранённые страницы
Для поиска по сохранённым страницам можно как указывать конкретный URL, так и домены, например:
- microsoft.com покажет снимки с хоста microsoft.com
- *.microsoft.com покажет снимки с хоста microsoft.com и всех его субдоменов (например, www.microsoft.com)
- покажет архив данного url (поиск чувствителен к регистру)
- поиск архивных url начинающихся с http://twitter.com/burg
Данный сервис сохраняет следующие части страницы:
- Текстовое содержимое веб страницы
- Изображения
- Содержимое фреймов
- Контент и изображения загруженные или сгенерированные с помощью Javascript на сайтах Web 2.0
- Скриншоты размером 1024×768 пикселей.
Не сохраняются следующие части веб-страниц:
- Flash и загружаемый им контент
- Видео и звуки
- RSS и другие XML-страницы сохраняются ненадёжно. Большинство из них не сохраняются, или сохраняются как пустые страницы.
Архивируемая страница и все изображения должны быть менее 50 Мегабайт.
Для каждой архивированной страницы создаётся ссылка вида http://archive.is/XXXXX, где XXXXX это уникальный идентификатор страницы. Также к любой сохранённой странице можно получить доступ следующим образом:
- http://archive.is/2013/http://www.google.de/ — самый новый снимок в 2013 году.
- http://archive.is/201301/http://www.google.de/ — самый новый снимок в январе 2013.
- http://archive.is/20130101/http://www.google.de/ — самый новый снимок в течение дня 1 января 2013.
Дату можно продолжить далее, указав часы, минуты и секунды:
- http://archive.is/2013010103/http://www.google.de/
- http://archive.is/201301010313/http://www.google.de/
- http://archive.is/20130101031355/http://www.google.de/
Для улучшения читаемости, год, месяц, день, часы, минуты и секунды могут быть разделены точками, тире или двоеточиями:
- http://archive.is/2013-04-17/http://blog.bo.lt/
- http://archive.is/2013.04.17-12:08:20/http://blog.bo.lt/
Также возможно обратиться ко всем снимкам указанного URL:
http://archive.is/http://www.google.de/
Все сохранённые страницы домена:
http://archive.is/www.google.de
Все сохранённые страницы всех субдоменов
http://archive.is/*.google.de
Чтобы обратиться к самой последней версии страницы в архиве или к самой старой, поддерживаются адреса вида:
- http://archive.is/newest/http://reddit.com/
- http://archive.is/oldest/http://reddit.com/
Чтобы обратиться к определённой части длинной страницы имеется две опции:
- добавить хэштег (#) с позицией прокрутки в качество которого число между 0 (вершина страницы) и 100 (низ страницы). Например,
- выбрать текст на страницы и получить URL с хэштегом, указывающим на этот раздел. Например,
В доменах поддерживаются национальные символы:
- http://archive.is/www.maroñas.com.uy
- http://archive.is/*.测试
Обратите внимание, что при создании архивной копии страницы архивируемому сайту отправляется IP адрес человека, создающего снимок страницы. Это делается через заголовок X-Forwarded-For для правильного определения вашего региона и показа соответствующего содержимого.
Поиск сайтов в Wayback Machine
Wayback Machine
На странице «Internet Archive Wayback Machine» введите в поле поиска URL адрес сайта, а затем нажмите на кнопку «BROWSE HISTORY».
Под полем поиска находится информация об общем количестве созданных архивов для данного сайта за определенный период времени. На шкале времени по годам отображено количество сделанных архивов сайта (снимков сайта может быть много, или, наоборот, мало).
Выделите год, в центральной части страницы находится календарь, в котором выделены голубым цветом даты, когда создавались архивы сайта. Далее нажмите на нужную дату.
Вам также может быть интересно:
- Советские фильмы онлайн в интернете
- Яндекс Дзен — лента персональных рекомендаций
Обратите внимание на то, что при подведении курсора мыши отобразится время создания снимка. Если снимков несколько, вы можете открыть любой из архивов
Сайт будет открыт в том состоянии, которое у него было на момент создания архива.
За время существования моего сайта, у него было только два шаблона (темы оформления). На этом изображении вы можете увидеть, как выглядел мой сайт в первой теме оформления.
На этом изображении вы видите сайт моего знакомого, Алема из Казахстана. Данного сайта уже давно нет в интернете, поисковые системы не обнаруживают этот сайт, но благодаря архиву интернета все желающие могут получить доступ к содержимому удаленного сайта.
Качаем сайт с web.archive.org
Процесс восстановления сайта из веб-архива я покажу на примере сайта 1mds.ru. Я не знаю что это за сайт, я всего лишь знаю что у него в архиве много страниц, а это значит что сайт не только существовал, но с ним работали.
Для того, что бы открыть архив нужного сайта, нам необходимо пройти по такой вот ссылке:
http://web.archive.org/web/*/1mds.ru
На 24 ноября 2018 года, при открытии этой ссылки я обнаружил вот такую картину:
Как видите на главной зафиксировались результаты экспериментов с программной частью. Если мы просто скачаем сайт как есть, то в качестве главной будет именно эта страница. нам необходимо избежать попадания в архив таких страниц. Как это сделать? Довольно просто, но для начала необходимо определить когда последний раз в архив добавлялась главная страница сайта. Для этого нам необходимо воспользоваться навигацией по архиву сайта, которая расположена вверху справа:
Кликаем левую стрелку ибо правая все равно не активна, и кликаем до тех пор, пока не увидим главную страницу сайта. Возможно кликать придется много, бывает домены попадаются с весьма богатым прошлым. Например сайт, на примере которого я демонстрирую работу с архивом, не является исключением.
Вот мы можем видеть что 2 мая 2018-го бот обнаружил сообщение о том, что домен направлен на другой сайт:
Классика жанра, регистрируешь домен и направляешь его на существующий дабы не тратить лимит тарифа на количество сайтов.
А до этого, 30 марта, там был вообще блог про шитье-вязание.
Долистал я до 23 октября 2017-го и вижу уже другое содержимое:
Тут мы видим уже материалы связанные с воспитанием ребенка. Листаем дальше, там вообще попадается период когда на домене была всего одна страница с рекламой:
А вот с 25 апреля 2011 по 10 сентября 2013-го там был сайт связанный с рекламой. В общем нам нужно определиться какой из этих периодов мы хотим восстановить. К примеру я хочу восстановить блог про шитье-вязание. Мне необходимо найти дату его появления и дату когда этот блог был замечен там последний раз.
Я нашел последнюю дату, когда блог был на домене и скопировал ссылку из адресной строки:
http://web.archive.org/web/20180330034350/http://1mds.ru:80/
Мне нужны цифры после web/, я их выделил красным цветом. Это временная метка, когда была сделана копия. Теперь мне нужно найти первую копию блога и также скопировать из URL временную метку. Теперь у нас есть две метки с которой и до которой нам нужна копия сайта. Осталось дело за малым, установить утилиту, которая поможет нам скачать сайт. Для этого потребуется выполнить пару команд.
- sudo apt install ruby
- sudo gem install wayback_machine_downloader
После чего останется запустить скачивание сайта. Делается это вот такой командой:
wayback_machine_downloader -f20171223224600 -t20180330034350 1mds.ru
Таким образом мы скачаем архив с 23/12/2017 по 30/03/2018. Файлы сайта будут сохранены в домашней директории в папке «websites/1mds.ru». Теперь остается закинуть файлы на хостинг и радоваться результату.
Что такое веб-архив?
Для того, чтобы узнать, что такое веб-архив, стоит вспомнить события, произошедшие более 20 лет назад. В 1996 году по инициативе американского программиста, Брюстера Кайла, был создан сайт archiveorg. Благодаря этому ресурсу, любой пользователь может найти сохранённые копии сайтов разных лет.
Со временем библиотека Web archive расширилась и к 2016 году включала в себя 502 миллиарда копий веб-страниц. Это является одним из лучших примеров коллаборации с целью принести обществу пользу. Для того, чтобы посмотреть в реальном времени сайты, которые функционировали некоторое время назад, достаточно зайти в архив и найти его в системе.
Основной целью, которую преследовал Кайл, было сохранение исторические ценности интернет-пространства. Web archive может использовать каждый пользователь, при этом бесплатно. Для работы веб-архива по сохранению интернет-ресурсов может быть только одно препятствие. Если в настройках сайта нет запрета на сохранение информации с ресурса, такой сайт сможет войти в базу веб-архива.
Как происходит пополнение веб-архива? Для этого было создано программное обеспечение, посещающее и сохраняющее сайта с определённой частотой. Так же есть возможность делать сохранения ресурсов вручную. Например, при посещении сайта можно сохранить страницу о курсах СЕО для начинающих или любую другую часть ресурса. Это поможет сохранить информацию с течением времени.
Качаем сайт с web.archive.org
Процесс восстановления сайта из веб-архива я покажу на примере сайта 1mds.ru. Я не знаю что это за сайт, я всего лишь знаю что у него в архиве много страниц, а это значит что сайт не только существовал, но с ним работали.
Для того, что бы открыть архив нужного сайта, нам необходимо пройти по такой вот ссылке:
http://web.archive.org/web/*/1mds.ru
На 24 ноября 2018 года, при открытии этой ссылки я обнаружил вот такую картину:
Как видите на главной зафиксировались результаты экспериментов с программной частью. Если мы просто скачаем сайт как есть, то в качестве главной будет именно эта страница. нам необходимо избежать попадания в архив таких страниц. Как это сделать? Довольно просто, но для начала необходимо определить когда последний раз в архив добавлялась главная страница сайта. Для этого нам необходимо воспользоваться навигацией по архиву сайта, которая расположена вверху справа:
Кликаем левую стрелку ибо правая все равно не активна, и кликаем до тех пор, пока не увидим главную страницу сайта. Возможно кликать придется много, бывает домены попадаются с весьма богатым прошлым. Например сайт, на примере которого я демонстрирую работу с архивом, не является исключением.
Вот мы можем видеть что 2 мая 2018-го бот обнаружил сообщение о том, что домен направлен на другой сайт:
Классика жанра, регистрируешь домен и направляешь его на существующий дабы не тратить лимит тарифа на количество сайтов.
А до этого, 30 марта, там был вообще блог про шитье-вязание.
Долистал я до 23 октября 2017-го и вижу уже другое содержимое:
Тут мы видим уже материалы связанные с воспитанием ребенка. Листаем дальше, там вообще попадается период когда на домене была всего одна страница с рекламой:
А вот с 25 апреля 2011 по 10 сентября 2013-го там был сайт связанный с рекламой. В общем нам нужно определиться какой из этих периодов мы хотим восстановить. К примеру я хочу восстановить блог про шитье-вязание. Мне необходимо найти дату его появления и дату когда этот блог был замечен там последний раз.
Я нашел последнюю дату, когда блог был на домене и скопировал ссылку из адресной строки:
http://web.archive.org/web/20180330034350/http://1mds.ru:80/
Мне нужны цифры после web/, я их выделил красным цветом. Это временная метка, когда была сделана копия. Теперь мне нужно найти первую копию блога и также скопировать из URL временную метку. Теперь у нас есть две метки с которой и до которой нам нужна копия сайта. Осталось дело за малым, установить утилиту, которая поможет нам скачать сайт. Для этого потребуется выполнить пару команд.
- sudo apt install ruby
- sudo gem install wayback_machine_downloader
После чего останется запустить скачивание сайта. Делается это вот такой командой:
wayback_machine_downloader -f20171223224600 -t20180330034350 1mds.ru
Таким образом мы скачаем архив с 23/12/2017 по 30/03/2018. Файлы сайта будут сохранены в домашней директории в папке «websites/1mds.ru». Теперь остается закинуть файлы на хостинг и радоваться результату.
Основная цель проекта
Целью проекта является сохранение информации, которая когда-либо попадала в Интернет. Помимо обычных веб-страниц здесь можно найти: видео, аудио, различный софт, текстовые и графически материалы. Доступ ко всему содержимому полностью свободный.
Начиная с 1996 года архив регулярно пополняется новыми страницами, плюс делается несколько копий уже существующих страниц, которые были обновлены. Здесь можно посмотреть, как выглядел тот или иной сайт день назад или 10 лет назад.
Справляться с таким объёмом информации сервису позволяют специальные роботы (по сути мини-программы), регулярно сканирующие интернет (процесс называется индексация). Однако стоит понимать, что роботы не способны мониторить каждую страницу в сети постоянно, поэтому кое-где могут встречаться «пробелы». Чаще всего такое бывает, когда при последнем посещении робота страница была недоступна, например, при технических работах на сайте. В таком случае информация будет обновлена только во время следующего сканирования. Каждому сайту отводится тот или иной приоритет сканирования, крупные и/или перспективные ресурсы сканируются чаще, чем их более скромные аналоги.
Доступ к информации, хранящейся в архивах, осуществляется при помощи сервиса The Wayback Machine. Работает по аналогично схеме с поисковыми системами – вы вводите название интересующего ресурса и смотрите варианты, выданные системой. Дополнительно здесь можно настраивать определённые фильтры, например, даты, показывающие состояние страниц на тот или иной период.
В Архиве Интернета можно проследить развитие не только сайтов, работающих на данный момент, но и ресурсов, которые по каким-либо причинам уже перестали функционировать или были присоединены к другим проектам.
Вся информация может быть найдена на сайте archive.org. Дополнительно всю информацию можно подразделять на категории.
Использование Интернет-Архива
После перехода на сайт Архива обратите внимание поисковую строку, расположенную в верхней части вкладки (она называется «Wayback Machine»). С её помощью можно найти и проследить историю развития практически любого сайта
После того, как вы вбили в поиск URL искомого ресурса, сервис выдаст на временной шкале копии его главных страниц, которые были сделаны за всё время существования проекта. Для того, чтобы просмотреть, как выглядел сайт в то или иное время, выберите нужную дату. Не стоит забывать, что «слепки» страниц делаются не каждый день, поэтому проследить развитие ресурса по дням, да и по месяцам будет проблематично. Дата, для которой уже сделана копия, подсвечена цветом.
У некоторых доменных имён может быть длинная история. Например, изначально это имя использовало какое-нибудь туристическое агентство, но по какой-то причине оно забросило свой сайт, а спустя несколько лет это же имя использует какой-нибудь блог или сервис.
Проект Internet Archive очень важен как в глобальном понимании для сохранения истории развития интернета и веба, так и для веб-разработчиков и просто любопытных пользователей. Вебмастерам этот сервис даёт возможность просмотреть историю того доменного имени, которое будет использоваться для будущего сайта.
Уникальный контент из «мертвых» сайтов
Каждый день из интернета исчезают десятки и даже сотни разнообразных сайтов. Стоит отметить, что абсолютное большинство не представляет особой ценности, но в каждой реке можно найти много крупинок золота. Главное, чтобы полезные сайты имели хотя бы один работающий слепок в archive.org.
Поскольку информация из умерших сайтов поступенно перестает индексироваться поисковыми системами, такой контент становится уникальным (конечно, если он не был «сплагиачен» до этого). Выставив эту информацию на свой ресурс, вы станете ее правообладателем или первоисточником для поисковых систем. Главное, предварительно проверить ее на уникальность, чтобы не нарушить ничей копирайт. Но как именно отыскать подобные ресурсы среди гор мусора?
К счастью, существует один способ.
После этого нужно всего лишь просматривать информацию Webarchive с каждого ресурса, который вас заинтересовал. Безусловно, такой метод предполагает наличие внимательности, а также терпения, поскольку качество большинства данного контента будет низкопробным.
Качаем сайт с web-arhive.ru
Это самый геморройный вариант ибо у данного сервиса нет возможности скачать сайт как у описанного выше. Соответственно пользоваться этим вариантом есть смысл пользоваться только в случае если нужно скачать сайт, которого нет на web.archive.org. Но я сомневаюсь что такое возможно. Этим вариантом я пользовался по причине того, что не знал других вариантов,а поискать поленился.
В итоге я написал скрипт, который позволяет скачать архив сайта с web-arhive.ru. Но велика вероятность того, что это будет сопровождаться ошибками, поскольку скрипт сыроват и был заточен под скачивание определенного сайта. Но на всякий случай я выложу этот скрипт.
Вот ссылка: https://yadi.sk/d/zoMRxwPoSXh0Jw
Пользоваться им довольно просто. Для запуска скачивания необходимо запустить этот скрипт все в той же командной строке, где в качестве параметра вставить ссылку на копию сайта. Должно получиться что-то типа такого:
php get_archive.php «http://web-arhive.ru/view2?time=20160320163021&url=http%3A%2F%2Fremontistroitelstvo.ru%2F»
Заходим на сайт web-arhive.ru, в строке указываем домен и жмем кнопку «Найти». Ниже должны появится года и месяцы в которых есть копии.
Обратите внимание на то, что слева и справа от годов и месяцев есть стрелки, кликая которые можно листать колонки с годами и месяцами
Остается найти дату с нужной копией, скопировать ссылку из адресной строки и отдать её скрипту. Не забывает помещать ссылку в кавычки во избежание ошибок из-за наличия спецсимволов.
Мало того, что само скачивание сопровождается ошибками, более того, в выбранной копии сайта может не быть каких-то страниц и придется шерстить все копии на предмет наличия той или иной страницы.
Мнения в Сторис
Создатели социальной сети стараются вносить изменения и новые опции ВК, чтобы пользователям было интересно и весело. Теперь каждый может воспользоваться опцией мнения в сторис. Это функция позволяет выразить собственное мнение относительно того или иного вопроса, процесса, новости. Также можно другим юзерам, своим подписчикам. Чтобы воспользоваться такой опцией нужно:
- Открыть новости, где доступны сторис.
- Далее нажимаем на создание новой публикации.
Создаем новую публикацию
- Делаем селфи или же добавляем другое изображение.
- Жмем на кнопку в виде наклейки.
- Кликаем на стикер мнения.
- Из представленного перечня нужно выбрать тот, который вас заинтересовал, и вводим вопрос.
Такая история также будет храниться в архиве социальной сети, и при желании вы сможете ее просмотреть. После того как юзеры выберут ее, появится форма для ввода ответа на вопрос. Отвечающий при желании может указать имя или же остаться анонимом.
Всемирный Веб архив сайтов интернета
Хранилище интернет-архив конечно не содержит всех страниц, которые когда-либо были созданы. Но шанс найти интересующий вас сайт и его архивную копию достаточно велик.
Самый мощный архив веб-сайтов доступен на Archive.org по адресу www.archive.org. Он индексирует веб, виде-, аудио и текстовые материалы, которые доступны в интернете.
Запустите ваш любимый веб-браузер и введите www.archive.org в адресной строке . Через некоторое время вы увидите главную страницу сайта интернет-архива. Она разделена на несколько частей. Каждая часть позволяет искать различный тип контента.
Раздел видео, содержит на момент написания статьи более 830 тысяч фильмов.
Раздел аудио, включает в себя более 2 миллионов записей, при это доступен еще раздел живой музыки, который насчитывает около 200 тысяч прямых трансляций с концертов в Интернет.
Однако наиболее интересным и значимым разделом сайта Archive.org является раздел web-страницы. На сегодняшний день он позволяет получить доступ к более чем 349 миллиардам архивных веб-сайтов. Для данного раздела даже выделен отдельный поддомен web.
Главная страница сайта Archive.org
Борьба с добром и российской судебной практикой
Организация Internet Archive зарегистрирована в Сан-Франциско (Калифорния, США), а одноименный ресурс, согласно законам штата Калифорния, официально считается библиотекой. Организация располагает обширным списком партнеров, в число которых входят многие крупные организации со всего мира. К ним относятся, в частности, Национальный научный фонд США и Библиотека конгресса США
CIO и СTO: как меняется влияние ИТ-руководителей в компаниях?
Новое в СХД
В России «Архив интернета» нередко используется российскими судами как доверенную третью сторону и источники информации, в том числе улик и доказательств расследования.
Возможности использования веб-архивов
Возможности сохраненной истории
Теперь каждый знает, что такое веб-архив, какие сайты предоставляют услуги сохранения копий проектов. Но многие до сих пор не понимают, как использовать представленную информацию. Возможности архивных данных выражаются в следующем:
- Выбор доменного имени. Не секрет, что многие веб-мастера используют уже прокачанные домены. Стоит понимать, что опытные юзеры отслеживают не только целевые параметры, но и историю предыдущего использования. Каждый пользователь сети желает знать, что приобретает: имелись ли ранее запреты или санкции, не попадал ли проект под фильтры.
- Восстановление сайта из архивов. Иногда случается беда, которая ставит под угрозу существование собственного проекта. Отсутствие своевременных бэкапов в профиле хостинга и случайная ошибка может привести к трагедии. Если подобное произошло, не стоит расстраиваться, ведь можно воспользоваться веб-архивом. О процессе восстановления поговорим ниже.
- Поиск уникального контента. Ежедневно на просторах интернета умирают сайты, которые наполнены контентом. Это случается с особым постоянством, из-за чего теряется огромный поток информации. Со временем такие страницы выпадают из индекса, и находчивый веб-мастер может позаимствовать информацию на личный проект. Конечно, существует проблема с поиском, но это вторичная забота.
Мы рассмотрели основные возможности, которые предоставляют веб-архивы, самое время перейти к более подробному изучению отдельных элементов.
Восстанавливаем сайт из веб-архива
Фиксация в веб-архиве за 2011–2016 годы
Никто не застрахован от проблем с сайтами. Большинство их них решается с использованием бэкапов. Но что делать, если сохраненной копии на сервере хостинга нет? Воспользоваться веб-архивом. Для этого следует:
- Зайти на специализированный ресурс, о которых мы говорили ранее.
- Внести собственное доменное имя в строку поиска и открыть проект в новом окне.
- Выбрать наиболее удачный снимок, который располагается ближе к проблемной дате и имеет полноценный вид.
- Исправить внутренние ссылки на прямые. Для этого используем ссылку «http://web.archive.org/web/любой_порядковый_номер_id_/Название сайта».
- Скопировать потерянную информацию или данные дизайна, которые будут применены для восстановления.
Заметим, что процесс несколько утомительный, с учетом скорости работы архива. Поэтому рекомендуем владельцам больших веб-ресурсов чаще выполнять бэкапы, что сохранит время и нервы.
Ищем уникальный контент для собственного сайта
Уникальный контент из веб-архива
Некоторые веб-мастера используют интересный способ получения нового, никому не нужного контента. Ежедневно сотни сайтов уходят в небытие, а вместе с ними теряется информация. Чтобы стать владельцем контента, нужно выполнить следующее:
- Внести URLв строку поиска.
- На сайте аукциона доменных имен скачать файлы с именем ru.
- Открыть полученные файлы с использованием excel и начать отбор по параметру наличия проектной информации.
- Найденные в списке проекты ввести на странице поиска веб-архива.
- Открыть снимок и получить доступ к информационному потоку.
Рекомендуем отслеживать контент на наличие плагиата, это позволит найти действительно достойные тексты. А на этом все! Теперь каждый знает о возможностях и методах использования веб-архива. Используйте знание с умом и выгодой.