Руководство: как закрыть сайт от индексации в поисковых системах? работа с файлом robots.txt
Содержание:
- Как закрыть внешние ссылки от индексации
- Когда следует использовать режим обслуживания WordPress
- Внутренние ссылки
- Блокировка сайта на компьютере при помощи изменений DNS — серверов — блокируем вредоносные и сайты для взрослых
- Использование спецсимволов в командах robots.txt
- Разрешить индексацию robots.txt — Allow
- Подробности
- Директива Clean-param в robots.txt
- Закрыть доступ к сайту через Брандмауэр
- Способ 1. Создать файл Site Closed
- Главное зеркало сайта в robots.txt — Host
- Что такое индексация сайта
- Как закрыть страницу в ВК
- Использование метатега robots для блокирования доступа к сайту
- Принцип работы файла robots
- Как закрыть страницу от индексации?
- Карта сайта в robots.txt — Sitemap.xml
- Причины использования
- Заключение
Как закрыть внешние ссылки от индексации
Для того чтобы запретить к индексации текстовые фрагменты, на сайте нужно использовать тег noindex
Важно знать, что этот тег способен закрывать только текстовые блоки. Картинки, баннеры, и другие элементы запретить к индексации с помощью этого тега нельзя
Многие люди совершают большую ошибку, когда заключают в этот тег ссылку. Поисковая система без проблем считывает и индексирует ссылку. В этом случае запрещён к индексации только анкор ссылки, так как это текст. Будьте внимательны.
Тег noindex прописывается в исходный код сайта. Имеет открывающий и закрывающий тег. Текст помещается между этими тегами.
Теперь подробнее:
Этот текст поисковые системы не отдадут на индексацию. А также тег noindex может выступать в роли метатега, который расположен в начале страницы и он отличается в корне. Если на странице расположен метатег noindex, в этом случае он запрещает индексирование всей страницы. При этом не только тексты, но и все что на ней находится – ссылки, картинки, баннеры, формы и так далее, всё это будет запрещено к индексации. Лучше всего для запрета индексация целых страниц использовать специальный файл robots.txt.
Как правильно ставить тег noindex
Вначале можно прочитать, что тег noindex создан исключительно для поисковых машин. То есть этот тег не является официальным тегом языка html. Именно поэтому HTML-редакторы могут показывать, что тег написан с ошибкой. Не пугайтесь, это происходит по причине того, что они просто не понимают этот тег и не считают его валидным. Но, так или иначе, его без проблем прочитают поисковые машины.
И ещё важно знать и запомнить, на тег noindex будет реагировать только поисковая система Яндекс, так как он его и создал. Поисковая система Google не реагирует на такой тег вообще.. Многие начинающие SEO-оптимизаторы допускают одну и ту же ошибку, а именно пытаются запретить к индексации ссылку с помощью этого тега
Для того чтобы скрыть ссылку от индексации нужно использовать другой тег – nofollow, об этом ниже
Многие начинающие SEO-оптимизаторы допускают одну и ту же ошибку, а именно пытаются запретить к индексации ссылку с помощью этого тега. Для того чтобы скрыть ссылку от индексации нужно использовать другой тег – nofollow, об этом ниже.
Владельцам сайта не запрещается манипулировать тегами, можно не смотреть за их вложенностью, noindex будет работать при любом раскладе. Об этом пишет сам Яндекс. Главное, быть внимательным при работе с этими тегами, так как если вы забудете поставить закрывающий тег, схема работать не будет. В этом случае поисковая система Яндекс проиндексирует и отдаст всё что есть на странице в выдачу.
Как скрыть ссылки от индексации
В случае когда в тег ссылки добавить отдельный, дополнительный атрибут rel=”nofollow”, это будет означать, что ссылка не будет проиндексирована поисковым роботом. Вот пример как это выглядит в коде HTML:
Этот параметр очень важен для тех сайтов, которые не хотят делиться весом своего ресурса с другими WEB-проектами
Но также важно запомнить, что он не оставляет этот вес и у себя, по сути, он просто сгорает и не достаётся никому
Если же ссылку использовать без этого тега nofollow, то вес страницы, через эту ссылку уйдёт на другой сайт
Исходя из этого, важно понимать, что если внести этот атрибут во все ссылки, которые уходят на другие сайты, сайт потеряет в весе
Как работает этот атрибут nofollow на примере:
Конечно, если ссылка ссылается на страницу в рамках одного сайта или блога, то проставлять это свойство бесполезно и даже вредно. Это можно использовать только в тех случаях, когда стоит задача не передавать вес отдельным страницам сайта. Например, если есть продающая страница, куда должен поступать весь трафик, имеет ссылку на внутреннюю страницу, например, ответы на вопросы, то, конечно, лучше эту ссылку поместить в атрибут nofollow.
Как использовать тег noindex и nofollow одновременно
Данные теги не конфликтуют между собой, поэтому совершенно спокойно можно использовать их одновременно на одной странице или участке текста. В этом случае и текст и ссылка не будет доступна к индексации
Но важно не забывать, что текст будет скрыт только для поисковой системы Яндекс
На этом сегодня всё, всем удачи и до новых встреч!
Когда следует использовать режим обслуживания WordPress
Каждый разработчик сам решает, в какие моменты лучше закрыть сайт на обслуживание. Несмотря на это, рекомендую все же ознакомиться с возможными причинами, из-за которых стоит переводить сайт в этот режим:
- Ребрендинг. В таких случаях попросту невозможно оставить сайт без профилактического режима.
- Внесение корректировок на популярных страницах. Когда проводятся изменения малопосещаемых страниц, то можно обойтись без их отключения, но когда это касается веб-страниц с большим трафиком, то лучше их обезопасить и отключить на время работы.
- Установка нового плагина. Если это расширение влияет на работу всего сайта, обязательно позаботьтесь о режиме обслуживания.
- Восстановление сайта после DDoS-атаки – вопросов возникнуть не должно.
«Скоро появится» – такую надпись часто можно встретить на тех страницах, которые находятся в стадии разработки. Если вы не планируете размещать новую страницу до ее появления, то уведомлять о профилактических работах не потребуется.
Все вышесказанное можно объединить в один тезис – капитальный ремонт. Проще говоря, если проводятся крупные работы над страницей, первым делом позаботьтесь о ее деактивации.
Внутренние ссылки
Внутренние ссылки закрываются от индексации для перераспределения внутренних весов на основные продвигаемые страницы. Но дело в том, что:
– такое перераспределение может плохо отразиться на общих связях между страницами;
– ссылки из шаблонных сквозных блоков обычно имеют меньший вес или могут вообще не учитываться.
Рассмотрим варианты, которые используются для скрытия ссылок:
Для скрытия ссылок этот тег бесполезен. Он распространяется только на текст.
Атрибут rel=”nofollow”
Сейчас атрибут не позволяет сохранять вес на странице. При использовании rel=”nofollow” вес просто теряется. Само по себе использование тега для внутренних ссылок выглядит не особо логично.
Представители Google рекомендуют отказаться от такой практики.
Рекомендацию Рэнда Фишкина:
Скрытие ссылок с помощью скриптов
Это фактически единственный рабочий метод, с помощью которого можно спрятать ссылки от поисковых систем. Можно использовать Аjax и подгружать блоки ссылок уже после загрузки страницы или добавлять ссылки, подменяя скриптом тег на
При этом важно учитывать, что поисковые алгоритмы умеют распознавать скрипты
Как и в случае с контентом – это «костыль», который иногда может решить проблему. Если вы не уверены, что получите положительный эффект от спрятанного блока ссылок, лучше такие методы не использовать.
Блокировка сайта на компьютере при помощи изменений DNS — серверов — блокируем вредоносные и сайты для взрослых
Domain Name Server (DNS) – это своего рода переводчик для браузеров. Названия, которые мы привыкли видеть в адресной строке, вроде vk.com или mail.ru, ничего не значат для браузера. Браузер ищет сайты по их IP-адресам, а DNS помогает понять ему, какой адрес принадлежит тому или иному сайту.
Мы можем изменить DNS компьютера и заставить его работать по другим адресам. Вот как это сделать:
- Зайдите в “Панель управления”.
- Найдите и откройте раздел под названием под названием “Центр управления сетями и общим доступом”.
- В открывшемся окне нажмите на ссылку подключения (“Беспроводная сеть (название)” или “Подключение по локальной сети”).
- Перед вами появится новое окошко, здесь нажмите на кнопку “Свойства”.
- Затем в появившемся списке найдите строчку “Протокол Интернета версии 4 (TCP/IPv4)” и дважды кликните по ней.
- Внизу нового окна поставьте выбор “Использовать следующие адреса DNS- серверов” и введите адреса “153.192.60” и“198.153.194.60” в соответствующие строки.
- Затем сохраните всё, нажав “OK”.
Адреса, которые мы ввели, это адреса сервиса под название “NORTONDNS”. Теперь прежде чем переправить вас на тот или иной сайт его будут проверять, и если там есть материалы для взрослых или если сайт небезопасен, его будут блокировать.
К сожалению, данный метод может не сработать, если ваш DNS настраивается автоматически.
Использование спецсимволов в командах robots.txt
В командах robots.txt может использоваться два спецсимвола: * и $:
- Звездочка * заменяет собой любую последовательность символов.
- По умолчанию в конце каждой команды добавляется *. Чтобы отменить это, в конце строки необходимо поставить символ $.
Допустим, у нас имеется сайт с адресом site.com, и мы хотим настроить файл robots.txt для нашего проекта. Разберем действие спецсимволов на примерах:
| Команда | Что обозначает |
| Disallow: /basket/ | Запрещает индексацию всех документов в разделе /basket/, например:site.com/basket/ site.com/basket/2/ site.com/basket/3/ site.com/basket/4/ |
| Disallow: /basket/$ | Запрещает индексацию только документа: site.com/basket/Документы: site.com/basket/2/ site.com/basket/3/ site.com/basket/4/остаются открытыми для индексации. |
Разрешить индексацию robots.txt — Allow
Allow — это директива разрешающая поисковому роботу обход страниц. Она является противоположностью директиве Disallow. В ней, как и в Disallow возможно использование спецсимволов * и $.
Давайте рассмотрим пример использования директивы Allow:
User-agent: * Disallow: / Allow: /blog
Данные инструкции разрешают обход раздела /blog, при этом весь остальной сайт остается недоступен для индексирования.
Пустой «Disallow: » = «Allow: /». Обе директивы разрешают полный обход сайтаПустой «Allow: » = «Disallow: /». Обе директивы полностью запрещают обход сайта.
Эта информация дана для справки. Широкого практического применения она не получает.
Подробности
Самый удобный вариант для ограничения доступа к интернет-ресурсам в данном интернет-обозревателе заключается в использовании специальных расширений. В этой статье мы разберем три очень удобных решения.
Website Blocker
Простейший плагин, позволяющий блокировать сайты в браузере. Загрузить и настроить его выйдет следующим образом:
- Перейдите на страницу https://chrome.google.com/webstore/detail/website-blocker-beta/hclgegipaehbigmbhdpfapmjadbaldib.
- Кликните сначала на кнопку установки, а потом – на подтверждение.
- Далее, перейдите на нежелательный интернет-ресурс.
- Щелкните ЛКМ по новому значку.
- Теперь задайте временной промежуток блокировки.
- А потом нажмите на кнопку Block This.
При желании вы можете в окошке плагина вручную ввести ссылку, не переходя на нежеланную веб-страницу.
Преимущества:
- Быстрая блокировка любого ресурса.
- Очень быстрая работа в любых условиях.
- Возможность выбора времени блокировки.
- Простой процесс добавления сайта в список.
- Блокировка при помощи одной кнопки.
- Предельно простой процесс установки.
- Отличная работа с Яндекс.Браузером.
- Легкость в использовании.
Недостатки:
Нет русского языка в меню.
Block Site
- Перейдите на страницу https://chrome.google.com/webstore/detail/block-site-website-blocke/eiimnmioipafcokbfikbljfdeojpcgbh?hl=ru.
- Далее, кликните ЛКМ на синюю кнопку.
- После этого выберите «Установить расширение».
- На открывшейся странице нажмите «Принимаю».
Затем кликните ПКМ по новой иконке и перейдите в «Настройки».В текстовое поле вставьте ссылку на нежелательный ресурс и нажмите «плюсик». Тогда в браузере не будет к нему доступа. Также можно отключить ресурсы для взрослых, отметив соответствующий пункт.
Особенностью плагина является его возможность синхронизации с мобильной версией Block Site для интернет-обозревателя. То есть, недоступные на компьютере ресурсы будут запрещено и на смартфоне.
Преимущества:
- Быстрая и качественная блокировка любого ресурса.
- Возможность выбора времени запрета.
- Синхронизация с мобильной версией плагина.
- Превосходно оформленный интерфейс.
- Простая настройка.
- Очень простой процесс инсталляции.
- Отличная работа в Яндекс.Браузере.
- Плагин совершенно бесплатен.
Явных недостатков не замечено.
Adult Blocker
- Откройте страницу https://chrome.google.com/webstore/detail/adult-block/deapbojkkighpdmmjgmankndcjafppck?hl=ru.
- Нажмите на кнопку инсталляции.
- Подтвердите выполнение процедуры.
После инсталляции на панели инструментов появится соответствующая иконка. Нужно кликнуть на нее и потом нажать «Регистрация».Затем – ввести требуемые данные и нажать «Запуск».
Установленный пароль необходим для доступа к меню управления Adult Blocker.
После следует посетить сайт, который нужно заблокировать, снова нажать на значок дополнения, ввести ранее указанный пароль и кликнуть по красной кнопке.После этого придется ввести пароль, который вы недавно придумали.
Конечно, блокировать сайты при помощи этого плагина немного сложнее, но зато надежнее. К тому же, в плагине имеется превосходно оформленное меню и даже русский язык. Последний факт точно обрадует отечественных пользователей.
Adult Blocker с успехом используют миллионы юзеров. Особенно хорошо то, что дополнение требует очень мало оперативной памяти. Это делает возможным его использование даже на относительно слабых машинах.
Преимущества:
- Быстрая и качественная блокировка любого ресурса.
- Простейший процесс инсталляции.
- Плагин отлично работает с Яндекс.Браузером.
- Защита паролем настроек расширения.
- Предельно простой и понятный интерфейс.
- Весьма приятное оформление.
- Есть русский язык в интерфейсе.
- Возможность настройки блокировки по часам.
- Очень простой управление.
- Потребляет мало оперативной памяти.
- Можно использовать на слабых машинах.
Недостатки:
Замечено не было.
Директива Clean-param в robots.txt
Чтобы поисковые роботы не обходили данные страницы, и лишний раз не нагружали ваш сервер, используйте директиву Clean-param, которая позволит оставить в выдаче только исходный документ.
https://naked-seo.ru/books/get_book.pl?userID=1&source=site_1&book_id=3 https://naked-seo.ru/books/get_book.pl?userID=2&source=site_2&book_id=3 https://naked-seo.ru/books/get_book.pl?userID=3&source=site_3&book_id=3
Параметр userID, который содержится в каждом url-адресе показывает персональный идентификатор пользователя, а параметр source показывает источник, из которого посетитель попал к нам на сайт. По трем разным url-адресам пользователи видят один и тот же контент book_id=3. В данном случае нам необходимо использовать директиву Clean-param следующим образом:
User-agent: Yandex Clean-param: userID /books/get_book.pl Clean-param: source /books/get_book.pl
Данные директивы помогут поисковому роботу Яндекса свести все динамические параметры в единую страницу:
https://naked-seo.ru/books/get_book.pl?&book_id=3
Если на сайте доступна такая страница, то именно она будет индексироваться и участвовать в выдаче.
Закрыть доступ к сайту через Брандмауэр
Прежде чем приступать к блокировке сайтов брандмауэром вам потребуется узнать их IP- адреса. Сделать это можно при помощи специальных сервисов, например через сервис “2ip”. Здесь вам нужно просто ввести адрес интересующего вас сайта и нажать “Проверить”, после чего вы получите всю нужную информацию о нём.
Заполучив IP сайта, сделайте с ним следующее:
- Для начала запустите панель управления и найдите раздел “Брандмауэр Защитника Windows”.
- В данном разделе, на панели слева выберите пункт “Дополнительные параметры”.
- Затем в списке в левой части экрана выберите раздел “Правила для исходящего подключения”.
- Теперь в списке справа выберите пункт “Создать правило…”.
- Появится новое окно, выберите пункт “Настраиваемые” и нажмите “Далее”.
- Затем выбираем пункт “Все программы” и вновь жмём “Далее”.
- На следующей странице просто нажмите “Далее”.
- На новой странице в разделе “Укажите удалённый IP-адрес” активируйте пункт “УказанныеIP-адреса”.
- Затем нажмите “Добавить…”, в появившемся окошке введите IP блокируемого сайта и нажмите “OK”.
- Если вы хотите добавить в чёрный список несколько сайтов, то повторяйте предыдущий пункт столько раз сколько нужно, затем, когда все сайты будут добавлены, нажмите “Далее”.
- На следующей странице выберите действие “Блокировать подключение” и нажмите “Далее”.
- Затем укажите имя созданного вами правила (придумайте сами) и сохраните его.
После этого добавленные сайты будут автоматически блокироваться.
Способ 1. Создать файл Site Closed
Способ подразумевает кастомизацию стандартной заглушки, которая включается в главном модуле, кнопкой “Закрыть публичную часть сайта”.
Стандартная заглушка заменяется посредством создания файла site_closed.php в «/bitrix/php_interface/include» или «/local/php_interface/include».
Такая заглушка — обычная страница, поэтому размещенные на ней компоненты тоже будут работать. В то же время страница может быть собрана в
и никак не связана с дизайном сайта.
А такую заглушку мы используем на наших проектах. Если вам понравилась эта заглушка, то не пропустите — в конце статьи будет ссылка на скачивание.
Главное зеркало сайта в robots.txt — Host
С марта 2018 года Яндекс отказался от директивы Host. Ее функции полностью перешли на раздел «Переезд сайта в Вебмастере» и 301-редирект.
Директива Host указывала поисковому роботу Яндекса на главное зеркало сайта. Если ваш сайт был доступен по нескольким разным адресам, например, с www и без www, вам необходимо было настроить 301 редирект на главный адрес и указать его в директиве Host.
Данная директива была полезна при установке SSL-сертификата и переезде сайта с http на https. В директиве Host адрес сайта при наличии SSL-сертификата указывался с https.
User-agent: Yandex Host: https://naked-seo.ru
В данном примере указано, что главным зеркалом сайта Naked SEO является ни www.naked-seo.ru, ни http://naked-seo.ru, а https://naked-seo.ru.
Для указания главного зеркала сайта в Google используются инструменты вебмастера в Google Search Console.
Что такое индексация сайта
Опубликованный на страницах сайтов контент собирается заранее и хранится в базе данных поисковой системы.
Называется эта база данных Индексом (Index), а собственно процесс сбора информации в сети с занесением в базу ПС называется «индексацией».
Продвинутые пользователи мгновенно сообразят, получается, что если текст на странице сайта не занесен в Индекс поисковика, так эта информация не может быть найдена и контент не станет доступен людям?
Так оно и есть. Каждый день тысячи веб-мастеров публикуют на своих площадках новые статьи. Однако доступными для поиска эти новые публикации становятся далеко не сразу.
В плане индексации Google работает несколько быстрее нашего Яндекса.
- Публикация на сайте станет доступна в поиске Гугл через несколько часов. Иногда индексация происходит буквально в считанные минуты.
- В Яндексе процесс сбора информации относительно нового контента в интернете происходит значительно медленнее. Иногда новая публикация на сайте или блоге появляется в Яндексе через две недели.
Чтобы ускорить появление вновь опубликованного контента, администраторы сайтов могут вручную добавить URL новых страниц в инструментах Яндекса для веб-мастеров. Однако и это не гарантирует, что новая статья немедленно появится в интернете.
С другой стороны, бывают ситуации, когда веб-страница или отдельная часть контента уже опубликованы на сайте, но вот показывать этот контент пользователям нежелательно по каким-либо причинам.
- Страница еще не полностью доработана, и владелец сайта не хочет показывать людям недоделанный продукт, поскольку это производит негативное впечатление на потенциальных клиентов.
- Существует разновидностей технического контента, который не предназначен для широкой публики. Определенная информация обязательно должна быть на сайте, но вот видеть ее обычным людям пользователям не нужно.
- В статьях размещаются ссылки и цитаты, которые необходимы с информационной точки зрения, но вот находиться в базе данных поисковой системы они не должны. Например, эти ссылки выглядят как неестественные и за их публикацию в проект может быть подвергнут штрафным санкциям.
В общем, причин, почему веб-мастеру не хотелось бы, чтобы целые веб-страницы или отдельные блоки контента, ссылки не были занесены в базы поисковиков, может существовать много.
Давайте разберемся, как задачу управления индексацией решить практически.
Как закрыть страницу в ВК
Чтобы ограничить доступ к своему аккаунту от посторонних, необходимо выполнить несколько простых манипуляций. Закрыть страницу в Vkontakte могут владельцы смартфонов, компьютеров и планшетов.
С компьютера
Эта пошаговая инструкция подходит для тех, кто предпочитает находиться за компьютером. Чтобы ограничить доступ к аккаунту потребуется выполнить следующие действия:
- Следует открыть свою страничку в социальной сети ВК.
- Нужно указать свой пароль или логин, чтобы выполнить вход в свой аккаунт.
- В верхней правой части у мини аватарки будет отображаться стрелка вниз. Следует нажать на данную стрелочку.
- В окне появится опция «Настройки».
- Затем нужно выбрать в правой колонке пункт «Приватность» и спуститься вниз страницы, чтобы перейти в раздел «Прочее».
- В этом же пункте нужно выбрать вкладку «Тип профиля» и указать «Закрытый».
- После выполнения данных манипуляций, пользователь получит уведомление «Точно ли вы хотите закрыть профиль»? В этом случае нужно нажать на опцию «Да, закрыть».
Этот способ наиболее легкий и простой. Ограничить доступ к профилю можно за 2 минуты. А теперь можно рассмотреть более сложный метод. Данный вариант пригодится в том случае, если пользователь хочет ограничить доступ к своему аккаунту частично. Пошаговая инструкция позволит правильно выполнить все действия:
- Следует перейти в «Настройки».
- Потом нужно выбрать вкладку «Приватность».
- На экране появится окно со списком опций. В этом варианте придется подобрать наиболее подходящий вариант «Только я» или «Никто».
- После выбора соответствующей опции, необходимо нажать на кнопку «Ок».
- Система автоматически сохранит информацию, указанную в графе.
С телефона
Пользователи Вконтакте могут поставить ограничения на свой аккаунт в социальной сети при помощи мобильного устройства. Этот вариант подойдет для смартфонов, которые поддерживают операционную систему Андроид и iOS. Пошаговая инструкция для данного способа выглядит следующим образом:
- Необходимо перейти в раздел «Профиль», нажав по силуэту человека в нижней части панели.
- Далее потребуется найти черточки, которые располагаются в верхней части экрана.
- Затем следует открыть вкладку «Настройки».
- Выберите пункт меню «Приватность»
- Придется спуститься вниз странички и выбрать опцию «Закрытый профиль». Ползунок необходимо перевести в правую сторону.
- После выполнения данных действий, потребуется подтвердить изменения, выбрав режим «Включено».
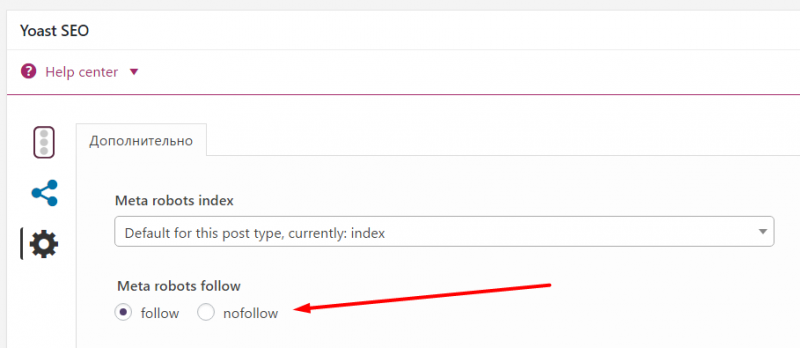
Использование метатега robots для блокирования доступа к сайту
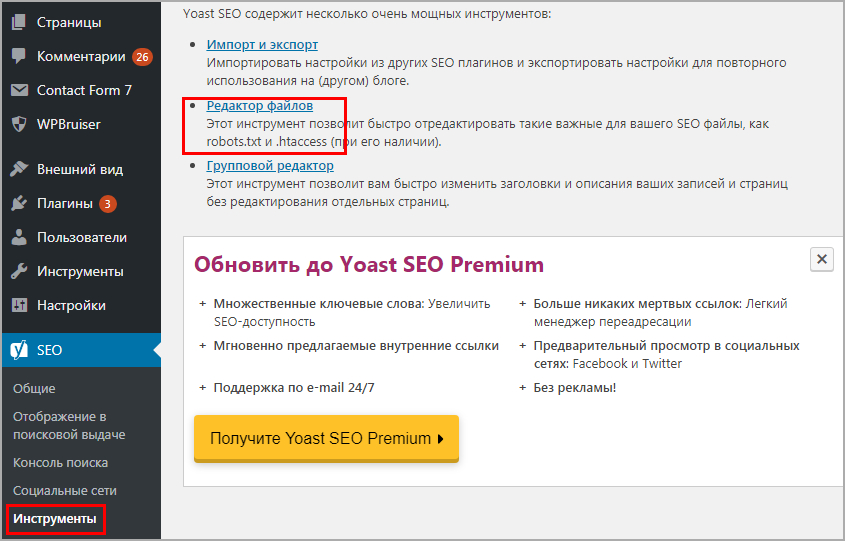
Данный метод запрета индексации страниц сайта встречается гораздо реже в повседневной жизни. Как следствие происходит это из-за что разработчики большинства CMS просто не обращают на это внимания/забывают/забивают. И тогда ответственность за поведение роботов на сайте полностью ложится на плечи вебмастеров, которые в свою очередь обходятся простейшим вариантом – robots.txt.
Но продвинутые вебмастера, которые в теме особенностей индексации сайтов и поведения роботов, используют метатег robots.
И снова небольшая выдержка из руководства от Google:
Внушает оптимизм, не правда ли? И еще:
Следовательно, все страницы, которые мы хотим запретить к индексации, а так же исключить их из индекса, если они уже проиндексированы (насколько я понял, это касается и доп. индекса Гугла), необходимо на всех таких страницах поместить метатег
Что еще более важно, эти самые страницы не должны быть закрыты через robots.txt!
Немного побуду кэпом и расскажу, какие еще значения (content=»…») может принимать мататег robots:
- noindex – запрещает индексацию страницы
- nofollow – запрещает роботу следовать по ссылкам на странице
- index, follow – разрешает роботу индексацию страницы и переход по ссылкам на этой странице
- all – аналогично предыдущему пункту. По большому счету, бесполезная директива, эквивалентна отсутствию самого метатега robots
- none – запрет на индексацию и следование по ссылкам, эквивалентно сочетанию noindex,nofollow
- noarchive – запрет поисковику выводить ссылку на кеш страницы (для Яндекса это «копия», для Google это «сохраненная копия»)
Так как в справке Яндекса нижеследующие параметры не описаны, то они, скорее всего, там и не сработают. Так что эти параметры только для Google:
- noimageindex – запрет на индексацию изображений на странице
- nosnippet – запрет на вывод сниппета в результатах поиска (при этом так же удаляется и сохраненная копия!)
- noodp – запрет для Google на вывод в качестве сниппета описания из каталога DMOZ
Вроде все, осталось только сказать, что количество пробелов, положение запятой и регистр внутри content=»…» здесь не играет никакой роли, но все же для красоты лучше писать как положено (с маленькой буквы, без пробелов и разделяя атрибуты запятой).
Короче говоря, чтобы полностью запретить индексацию ненужных страниц и появление их в поиске необходимо на всех этих страницах разместить метатег .
Так что если вам известны все страницы (наборы страниц, категории и т.д.), которые не должны попасть в индекс и есть доступ к редактированию их содержания (конкретно, содержания внутри тега ), то можно обойтись без запрещающих директив в файле robots.txt, но разместив на страницах метатег robots. Данный вариант, как вы понимаете, является эффективным и предпочтительным.
Рекомендую к прочтению:
- Мануал Google «Блокировка индексирования при помощи атрибута noindex»
- Мануал Яндекса «Как удалить страницы из поиска»
Итак, у нас остался последний нераскрытый вопрос, и он о внутренних ссылках.
Принцип работы файла robots
Работа файла строится всего на 3-х элементах:
- Выбор поискового робота
- Запрет на индексацию разделов
- Разрешение индексации разделов
1. Как указать поискового робота
С помощью директивы User-agent прописывается имя робота, для которого будут действовать следующие за ней правила. Она используется вот в таком формате:
User-agent: * # для всех роботов
User-agent: имя робота # для конкретного робота
После символа «#» пишутся комментарии, в обработке они не участвуют.
Таким образом, для разных поисковых систем и роботов могут быть заданы разные правила.
Основные роботы, на которые стоит ориентироваться – это yandex и googlebot, они представляют соответствующие поисковики.
2. Как запретить индексацию в Robots.txt
Запрет индексации осуществляется в помощью директивы Disallow. После нее прописывается раздел или элемент сайта, который не должен попадать в поиск. Указывать можно как конкретные папки и документы, так и разделы с определенными признаками.
Если после этой директивы не указать ничего, то робот посчитает, что запретов нет.
Disallow: #запретов нет
Для запрета файлов указываем путь относительного домена.
Disallow: /zapretniy.php #запрет к индексации файла zapretniy.php
Запрет разделов осуществляется аналогичным образом.
Disallow: /razdel-sajta #запрет к индексации всех страниц, начинающихся с /razdel-sajta
Если нам нужно запретить разные разделы и страницы, содержащие одинаковые признаки, то используем символ «*». Звездочка означает, что на ее месте могут быть любые символы (любые разделы, любой степени вложенности).
Disallow: */*test #будут закрыты все страницы, в адресе которых содержится test
Обратите внимание, что на конце правила звездочка не ставится, считается, что она там есть всегда. Отменить ее можно с помощью знака «$»
Disallow: */*test$ #запрет к индексации всех страниц, оканчивающихся на test
Выражения можно комбинировать, например:
Disallow: /test/*.pdf$ #закрывает все pdf файлы в разделе /test/ и его подразделах.
3. Как разрешить индексацию в Robots.txt
По-умолчанию, все разделы сайта открыты для поисковых роботов. Директива, разрешающая индексацию нужна в тех случаях, когда вам необходимо открыть какой-либо кусочек из блока закрытого директивой disallow.
Для открытия служит директива Allow. К ней применяются те же самые атрибуты. Пример работы может выглядеть вот так:
User-agent: * # для всех роботов Disallow: /razdel-sajta #запрет к индексации всех страниц, начинающихся с /razdel-sajta Allow: *.pdf$ #разрешает индексировать pdf файлы, даже в разделе /razdel-sajta
Теорию мы изучили, переходим к практике.
Как закрыть страницу от индексации?
Если нужно скрыть только одну страницу, то в файле robots нужно будет прописать другой код:
User-agent: *
Disallow: /category/kak-nachat-zarabatyvat
Во второй строчке вам нужно указать адрес страницы, но без названия домена. Как вариант, вы можете закрыть страницу от индексации, если пропишите в её коде:
<META NAME=»ROBOTS» CONTENT=»NOINDEX»>
Это более сложный вариант, но если нет желания добавлять строчки в robots.txt, то это отличный выход. Если вы попали на эту страницу в поисках способа закрытия от индексации дублей, то проще всего добавить все ссылки в robots.
Как закрыть от индексации ссылку или текст?
Здесь тоже нет ничего сложного, нужно лишь добавить специальные теги в код ссылки или окружить её ими:
<noindex>
<a rel=»nofollow» href=»http://Workion.ru/»>Анкор</a>
</noindex>
Используя эти же теги noindex, вы можете скрывать от поисковых систем разный текст. Для этого нужно в редакторе статьи прописать этот тег.
К сожалению, у Google такого тега нет, поэтому скрыть от него часть текста не получится. Самый простой вариант сделать это – добавить изображение с текстом.
Скрывайте от поисковых роботов всё, что не уникально или каким-то образом может нарушать их правила. А если вы решили полностью переделать сайт, то обязательно закрывайте его от индексации, чтобы боты не индексировали внесенные изменения до того, как вы над ними поработаете и всё протестируете.
Вам также будет интересно: — Скорость сайта – важный фактор — Почему Яндекс не индексирует сайт? — Оригинальные тексты для защиты от Yandex
Карта сайта в robots.txt — Sitemap.xml
Директива Sitemap указывает поисковым роботам путь на xml карту сайта. Этот файл невероятно важен для поисковых систем, так как при обходе сайта они, в первую очередь, обращаются к нему. В данном файле представлена структура сайта со всем внутренними ссылками, датами создания страниц, приоритетами индексирования.
Пример robots.txt с указанием адреса карты сайта на нашем сайте:
User-agent: * Sitemap: https://naked-seo.ru/sitemal.xml
Наличии xml карты сайта улучшает представление вашего сайта в поисковой выдаче. Карта сайта является стандартом, который должен быть внедрен на каждом сайте. Частота обновления и актуальность поддержания sitemap.xml может серьезно ускорить индексирование страниц, особенно у молодого сайта.
Причины использования
Такая заглушка используется на время технических работ, чтобы оповестить приходящих посетителей, что над сайтом ведутся работы и он скоро откроется.
С другой стороны сайт может некорректно работать во время тяжелых обновлений, внедрения новых функций и изменения дизайна, что может повлечь за собой потерю репутации.
Еще один вариант использования заглушки сайта — потребность разрекламировать проект прежде чем тот будет запущен.
В этом случае на заглушке размещают:
-
информацию о проекте;
-
ознакомительный контент (фотографии ассортимента, видео и т.п.);
-
таймер обратного отсчёта до полноценного открытия;
-
форму обратной связи;
-
ссылки на соцсети;
-
промокод на первую покупку.
Заключение
Как видите, способов закрытия проекта от ПС очень много. Я рассмотрел наиболее популярные и действенные варианты. Надеюсь, что этот материал поможет вам в решении ваших проблем. Все на самом деле очень просто, особенно если вы используете WordPress или аналогичную платформу. Достаточно просто активировать настройку, и проект будет закрыт.
Также можно воспользоваться универсальным способом и закрыть ресурс через robots.txt. Таким вариантом пользуется абсолютное большинство вебмастеров, и никаких нареканий у них не возникает. В любой удобный момент можно просто изменить содержимое файла и отправить сайт на переиндексацию.