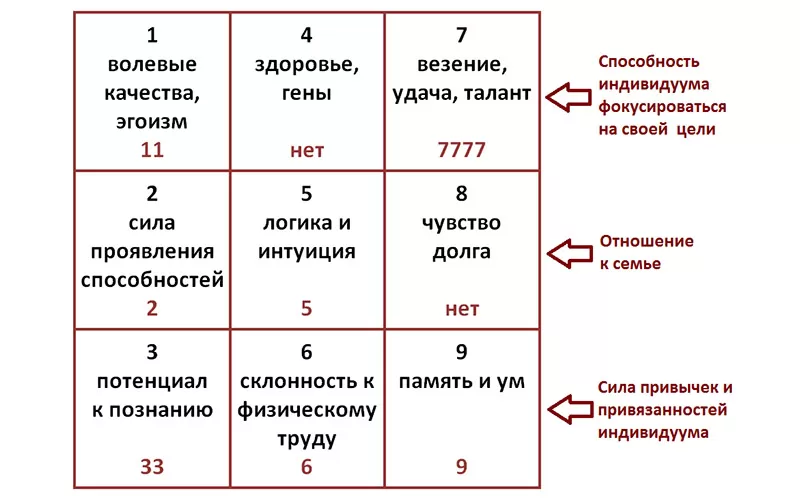
Как пробить человека по базе данных бесплатно
Содержание:
- Виды баз данных и их структура, примеры
- RAWGraphs
- Создание и редактирование модели данных
- Система управления базами данных (СУБД)
- Структура нового фреймворка
- Другие облачные сервисы баз данных для рассмотрения
- Наукометрические базы данных – что это и зачем нужны?
- Защита подключений
- Интерфейс
- Ограничение доступа к данным
- Как все начиналось
- SQLite3 manager LITE
- Сколько стоит бесплатный сыр
Виды баз данных и их структура, примеры
Выделяют несколько видов баз данных. Основными из них являются:
- Фактографическая, с краткой информацией об объектах какой-то системы, формат которой строго фиксирован.
- Документальная, включает документы разного вида, в том числе текстовые, графические, звуковые, мультимедийные.
- Распределенная, является базой данных с разными частями, которые хранятся на различных компьютерах, объединенных в сеть.
- Централизованная, представляет собой базу данных, местом хранения которой является один компьютер.
- Реляционная, имеет табличную организацию данных.
- Неструктурированная (NoSQL), является базой данных, в которой делается попытка решить проблемы масштабируемости и доступности с помощью атомарности и согласованности данных без четкой структуры.
Базы данных разных систем обладают неодинаковой структурой. Для ПЭВМ характерно использование реляционных баз данных с файлами в виде таблиц, в которых столбцы являются полями, а строки – записями. В базе данных находятся данные определенного множества объектов. Для каждой записи характерна информация по одному объекту. Такую базу определяют:
- имя файла;
- список полей;
- ширина полей.
В качестве примера можно привести школьную базу с данными «Ученик», «Класс», «Адрес». Также базой данных является расписание движения поездов или автобусов. В этом случае каждой строке соответствует запись с данными конкретного объекта. Возможные поля: номер рейса, маршрут, время отправления и прибытия. Классической базой данных является телефонный справочник.
Определение
Запрос к базе данных – предписание с указанием на данные, которые необходимы пользователю.
Примечание
В случае некоторых запросов требуется составление сложной программы. К примеру, для выполнения запроса к базе в виде автобусного расписания необходимо вычислить разницу в среднем интервале отправления транспорта из одного города во второй и из второго пункта в третий.
Существует три звена для создания приложения, с помощью которого можно просматривать и редактировать базы данных:
- набор данных;
- источник информации;
- визуальные компоненты управления.
В случае Access роль таких звеньев выполняют:
- Table.
- DataSource.
- DBGrid.
Приложения базы данных является нитью, которая связывает базу и пользователя:
БД => набор данных –=> источник данных => визуальные компоненты => пользователь
Набор данных:
- Table, в виде таблицы, навигационного доступа;
- Query, включая запрос, реляционный доступ.
Визуальными компонентами являются:
- Сетки DBGrid, DBCtrlGrid.
- Навигатор DBNavigator.
- Разные аналоги Lable, Edit.
- Компоненты подстановки.
Access характеризуется наличием следующих типов полей:
- текстовый, в виде текстовой строки с максимальной длиной до 255, заданной параметром «размер»;
- поле МЕМО, является текстом длиной до 65535 символов;
- числовой, в параметре «Размер поля» можно задать поле: байт, целое, действительное и другие;
- дата/время, необходимо для записи данных о времени;
- денежный, является специальным форматом для решения финансовых задач;
- счетчик, в виде автоинкрементного поля, который предназначен для ключевого поля, увеличивается на единицу после добавления новой записи и сохраняется в данное поле новой записи, что гарантирует разные значения для неодинаковых записей;
- логический, в виде «да или нет», «правда или ложь», «включен или выключен»;
- объект OLE, предназначен для хранения документов, картинок, звуков и другой информации, представляет собой частный случай BLOB, то есть полей (Binary Large Object), которые можно встретить в разных базах данных;
- гиперссылка, необходима для хранения ссылок на ресурсы в Интернете, характерна не для всех форматов баз данных, например, отсутствует в dBase и Paradox;
- подстановка.
Благодаря связи с обеспечением целостности таблиц осуществляется контроль удаления и модификации данных. С помощью монопольного доступа к базам данных в них производят фундаментальные изменения.
RAWGraphs
RAWGraphs
Сильные стороны бесплатной версии
- Диаграммы в RAWGraphs очень просто создавать, для работы с системой не нужно даже регистрировать учётную запись.
- Система поддерживает различные форматы входных данных — TSV, CSV, DSV, JSON и Excel-файлы(.xls, .xlsx).
- По сведениям RAWGraphs обработка данных производится исключительно средствами браузера. Платформа не занимается серверной обработкой или хранением данных. Никто из тех, кто не имеет отношения к данным, не сможет их просматривать, модифицировать или копировать.
- RAWGraphs — это система, поддающаяся расширению. Например, добавлять в неё новые диаграммы можно, обладая базовыми знаниями D3.js.
Слабые стороны бесплатной версии
- Диаграммы, создаваемые в RAWGraphs, иногда выглядят слишком простыми. У пользователей системы есть не особенно много механизмов для подстройки их под свои нужды.
- Визуализации данных не являются интерактивными.
Создание и редактирование модели данных
Для добавления модели нажимаем плюсик рядом с заголовком «Models» или выбираем «File → New Model» (Ctrl + N):
На этом экране вводим имя базы данных, выбираем кодировку по умолчанию и, если нужно, заполняем поле комментария. Можно приступать к созданию таблиц.
Добавление и редактирование таблицы
Список баз данных проекта и список таблиц в пределах базы данных будет располагаться во вкладке «Physical Schemas». Чтобы создать таблицу, дважды кликаем на «+Add Table»:
Откроется удобный интерфейс для редактирования списка полей и их свойств. Здесь мы можем задать название поля, тип данных, а так же установить для полей различные атрибуты: назначить поле первичным ключом (PK), пометить его Not Null (NN), бинарным (BIN), уникальным (UQ) и другие, установить для поля авто-инкремирование (AI) и значение по умолчанию (Default).
Управление индексами
Добавлять, удалять и редактировать индексы таблиц можно во вкладке «Indexes» интерфейса управления таблицей:
Вводим название индекса, выбираем его тип, затем галочками помечаем в нужном порядке список полей, участвующих в данном индексе. Порядок полей будет соответствовать порядку, в котором были проставлены галочки. В данном примере я добавил уникальный индекс к полю username.
Связи между таблицами
Установка внешних ключей и связывание таблиц возможно только для таблиц InnoDB (эта система хранения данных выбирается по умолчанию). Для управления связями в каждой таблице находится вкладка «Foreign Keys»:
Для добавления связи открываем вкладку «Foreign Keys»дочерней таблицы, вводим имя внешнего ключа и выбираем таблицу-родителя. Далее в средней части вкладки в графе Column выбираем поле-ключ из дочерней таблицы, а в графе Referenced Column — соответствующее поле из родительской таблицы (тип полей должен совпадать). При создании внешних ключей в дочерней таблице автоматически создаются соответствующие индексы.
В разделе «Foreign Key Options» настраиваем поведение внешнего ключа при изменении соответствующего поля (ON UPDATE) и удалении (ON DELETE) родительской записи:
- RESTRICT — выдавать ошибку при изменении / удалении родительской записи
- CASCADE — обновлять внешний ключ при изменении родительской записи, удалять дочернюю запись при удалении родителя
- SET NULL — устанавливать значение внешнего ключа NULL при изменении / удалении родителя (неприемлемо для полей, у которых установлен флаг NOT NULL!)
- NO ACTION — не делать ничего, однако по факту эффект аналогичен RESTRICT
В приведённом примере я добавил к дочерней таблице UserProfile внешний ключ для связи с родительской таблицей User.
При редактировании поля userId и удалении позиций из таблицы User аналогичные изменения будут автоматически происходить и со связанными записями из таблицы UserProfile.
Наполнение таблицы базовыми данными
При создании проекта в базу данных часто нужно добавлять стартовые данные. Это могут быть корневые категории, пользователи-администраторы и т.д. В управлении таблицами MySQL Workbench для этого существует вкладка «Inserts»:
Как видно из примера, в случае, если перед записью в базу данных к данным нужно применить какую-то функцию MySQL, это делается с помощью синтаксиса \func functionName(‘data’), например, \func md5(‘password’).
После ввода данных необходимо сохранить их в локальную базу данных нажатием на кнопку «Apply Changes».
Система управления базами данных (СУБД)
Система управления базами данных (сокращенно СУБД) – это программное обеспечение для создания и работы с базами данных.
Главная функция СУБД – это управление данными (которые могут быть как во внешней, так и в оперативной памяти). СУБД обязательно поддерживает языки баз данных, а также отвечает за копирование и восстановление информации после каких-либо сбоев.
Реляционные СУБД и язык SQL
Реляционные и объектно-реляционные СУБД являются одними из самых распространенных систем. Они представляют собой таблицы, в которых каждый столбец (он называется «field» или «поле») упорядочен и имеет определенное уникальное название. Последовательность строк (их называют «records» или «записи») определяется последовательностью ввода информации в таблицу. При этом обрабатывание столбцов и строк может происходить в любом порядке. Таблицы с данными связаны между собой специальными отношениями, благодаря чему с данными из разных таблиц можно работать – к примеру, объединять их при помощи одного запроса.
Для управления реляционными базами данных применяется особый язык программирования – SQL. Сокращение расшифровывается как «Structured query language», в переводе на русский – «язык структурированных запросов».
Команды, которые используются в SQL, делятся на:
- манипулирующие данными,
- определяющие данные,
- управляющие данными.
Схема работы с базой данных выглядит следующим образом:
Структура нового фреймворка
Фреймворк заточен на быстрое создание интерфейсов для СУБД. Он состоит из нескольких частей (модулей). Некоторые могут использоваться отдельно, некоторые — только совместно с остальными.
Модуль core содержит механизмы описания моделей, взаимодействия объектов (записей) данных между собой, механизмы описания запросов к базе данных. Модуль core обращается к источникам данных через модуль backend.
Модуль backend — это прослойка между модулем core и базой (источником) данных. В качестве источника данных может выступать как непосредственно сервер баз данных, вроде SQL, так и прослойка для доступа к моделям других фреймворков, таких как Django или Sequelize.
Модуль model-ui отвечает за генерацию интерфейса: он визуализирует данные, предоставляемые модулем core, используя элементы управления, предоставляемые модулем ui.
Модуль ui содержит базовые элементы управления, которые используются модулем model-ui при генерации интерфейса. Эти элементы могут использоваться также и независимо от фреймворка.
Модуль windows-manager управляет контейнерами для отображения пользовательских интерфейсов. В зависимости от типа windows-manager приложения можно разворачивать как на компьютерах, так и на мобильных устройствах.
Другие облачные сервисы баз данных для рассмотрения
В последние годы наблюдается большое количество облачных платформ, предлагаемых большим количеством компаний. Поскольку программное обеспечение на основе баз данных остается нормой, оно остается ключевым для обеспечения того, какую бы облачную платформу вы ни выбрали, чтобы она, вероятно, поддерживала ваши типы и размер базы данных и должным образом интегрировалась с другой ИТ-инфраструктурой, не в последнюю очередь отслеживая безопасность или ошибки
Здесь мы кратко рассмотрим некоторые дополнительные опции облачной базы данных, на которые стоит обратить внимание:
DataStax использует Apache Cassandra для формирования основы своей облачной платформы, поддерживающей нативные, гибридные и мультиоблачные сервисы. Его корпоративный сервис нацелен на предоставление мощной, масштабируемой и постоянно действующей базы данных. DataStax также предоставляет сервисы управления для AWS, Azure и Google Cloud. Компания также собирается запустить свою облачную платформу данных Constellation с интеллектуальными услугами для нулевых операций..
Zoho Creator это что-то немного другое — это не столько платформа управления облачной базой данных, сколько простой способ создать собственную базу данных в облаке. Это особенно полезно для небольших компаний, которые, возможно, захотят создавать свои собственные приложения, но в противном случае найдут громкий пакет управления облачностью излишним. Он работает через простой интерфейс перетаскивания, который позволяет полностью настраивать, и как часть набора приложений Zoho означает, что он легко интегрируется с другими продуктами Zoho.
Couchbase также немного отличается тем, что позволяет создавать собственные базы данных, работающие на N1QL, что обеспечивает гораздо более сложное хранение данных, чем обычно позволяет MySQL. Это означает возможность создавать в облаке базы данных, которые являются многоуровневыми и работают лучше для JSON. Кроме того, он имеет встроенную аналитику, простую репликацию и безопасность корпоративного уровня
Поэтому, если вам требуется более инновационная платформа баз данных с гибкостью NoSQL, возможно, стоит обратить внимание на Couchbase.
MongoDB Atlas Это автоматизированный облачный сервис, который значительно упрощает управление базами данных в облаке, позволяя пользователям сосредоточиться на разработке приложений. Он предлагает глобальную поддержку для более чем 60 облачных регионов и поставляется с распределенной отказоустойчивостью наряду с вариантами резервного копирования для обеспечения непрерывности бизнеса. Масштабирование по требованию, оптимизация ресурсов и полностью автоматизированное обеспечение структуры означает, что MongoDB может быть особенно привлекательным для инновационного предприятия.
Наукометрические базы данных – что это и зачем нужны?
Для оценивания успешности ученых используют качественные и количественные показатели. В основе качественных лежат выводы экспертов из различных областей знаний. Такой метод трудно назвать достоверным, ведь подобные оценки субъективны – мнения ученых по одним и тем же вопросам могут сильно расходиться.
К количественным показателям относят публикуемые материалы – количество публикаций и частота их цитирований, число премий, стипендий, грантов, индекс Хирша, импакт-фактор, участие в составе редколлегии, сотрудничество с иностранными партнерами. Основными показателями успешности ученого считаются:
- Импакт-фактор – параметр определяет число цитирований конкретного научного труда за последние два года.
- Индекс Хирша – характеристика учитывает количество публикаций автора и число их цитирований (например, при наличии 5 статей у исследователя, на каждую из которых ссылаются не менее 5 раз, h-индекс составит 5).
- Индекс цитирования – показатель значимости научной работы одного ученого или целого коллектива, определяемый числом ссылок на эту работу или фамилию автора.
Ключевые данные получают из наукометрических баз данных. Это библиографические и реферативные источники информации, содержащие инструменты для отслеживания цитируемости различных публикаций. Помимо этого, наукометрическая база данных представляет собой собрание научных работ исследователей на любые темы, из которых легко находить интересующие материалы.
Через инструменты баз данных узнают:
- востребованность определенных статей;
- индексы влияния ученых, написавших эти труды;
- частоту размещения публикаций конкретными авторами или научными организациями.
В то же время базы данных помогают систематизировать и хранить различные публикационные материалы, искать литературные источники при написании собственного труда, оценивать себя, коллег и конкурентов, сравнивать журналы, научные организации, грантовые фонды. Наличие публикаций в одной из наукометрических баз данных – обязательное условие для защиты диссертации и успешного развития ученого в научном мире, его продвижения по карьерной лестнице.
Чтобы войти в определенную базу, журнал должен выполнить определенные условия. Это ряд требований, предъявляемых к содержанию, оформлению и количеству публикаций, составу редколлегии, периодичности выпусков, качеству работы сайта и его наполнения, размещению материалов на английском языке. Проверяют наличие изданий в определенных базах на их официальных сайтах.
Защита подключений
- эквивалентен ли один бизнес-пользователь одному пользователю СУБД;
- обеспечивается ли доступ к данным СУБД только через API, который вы контролируете, либо есть доступ к таблицам напрямую;
- выделена ли СУБД в отдельный защищенный сегмент, кто и как с ним взаимодействует;
- используется ли pooling/proxy и промежуточные слои, которые могут изменять информацию о том, как выстроено подключение и кто использует базу данных.
- Используйте решения класса database firewall. Дополнительный слой защиты, как минимум, повысит прозрачность того, что происходит в СУБД, как максимум — вы сможете обеспечить дополнительную защиту данных.
- Используйте парольные политики. Их применение зависит от того, как выстроена ваша архитектура. В любом случае — одного пароля в конфигурационном файле веб-приложения, которое подключается к СУБД, мало для защиты. Есть ряд инструментов СУБД, позволяющих контролировать, что пользователь и пароль требуют актуализации.
Почитать подробнее про функции оценки пользователей можно здесь, так же про MS SQL Vulnerability Assessmen можно узнать тут. - Обогащайте контекст сессии нужной информацией. Если сессия непрозрачная, вы не понимаете, кто в ее рамках работает в СУБД, можно в рамках выполняемой операции дополнить информацию о том, кто, что и зачем делает. Эту информацию можно увидеть в аудите.
- Настраивайте SSL, если у вас нет сетевого разграничения СУБД от конечных пользователей, она не в отдельном VLAN. В таких случаях обязательно защищать канал между потребителем и самой СУБД. Инструменты защиты есть в том числе и среди open source.
Как это повлияет на производительность СУБД?
Тест 1 без SSL и с использованием SSL
vs
Тест 2 без SSL и с использованием SSL
vs
Остальные настройки
Результаты тестирования
| NO SSL | SSL | |
| Устанавливается соединение при каждой транзакции | ||
| latency average | 171.915 ms | 187.695 ms |
| tps including connections establishing | 58.168112 | 53.278062 |
| tps excluding connections establishing | 64.084546 | 58.725846 |
| CPU | 24% | 28% |
| Все транзакции выполняются в одно соединение | ||
| latency average | 6.722 ms | 6.342 ms |
| tps including connections establishing | 1587.657278 | 1576.792883 |
| tps excluding connections establishing | 1588.380574 | 1577.694766 |
| CPU | 17% | 21% |
Интерфейс
Для ускорения разработки приложений фреймворк позволяет использовать встроенный интерфейс на базе модулей model-ui и ui. Это удобно, когда нет потребности в специфическом интерфейсе либо необходимо развернуть приложение максимально быстро. Однако, отказавшись от этих модулей, можно использовать и произвольный интерфейс (написанный, скажем, на базе Bootstrap или Angular Material).
Все элементы управления ввода данных в стандартном интерфейсе сделаны так, чтобы любой из них мог использоваться как в формах, так и в ячейках таблиц. Элементы также наделены свойствами, упрощающими работу с данными. Вот, к примеру, так выглядит текстовое поле.
При нажатии на кнопку расширения открывается увеличенное поле ввода: это удобно, когда ширина поля ввода меньше, чем помещенный в него текст. Такая ситуация может возникнуть при плотном расположении элементов на форме либо при редактировании данных в виде таблицы.
Если рассмотреть поле ввода числа, то в нем, кроме самого числа, можно вводить математические выражения.
Поле выбора другого объекта также имеет несколько способов ввода: оно позволяет выбирать объект как из выпадающего списка по вхождению слов, так и из отдельной всплывающей формы.
Что касается ошибок некорректности ввода, то они отображаются не текстом под элементом управления, а специальным маркером. Такой подход позволяет сохранять плотность элементов формы и не менять их положение при выводе ошибок. Аналогичным образом выводятся ошибки для ячеек таблицы с этим элементом управления.
Ограничение доступа к данным
- Шифрование и обфускация процедур и функций (Wrapping) — то есть отдельные инструменты и утилиты, которые из читаемого кода делают нечитаемый. Правда, потом его нельзя ни поменять, ни зарефакторить обратно. Такой подход иногда требуется как минимум на стороне СУБД — логика лицензионных ограничений или логика авторизации шифруется именно на уровне процедуры и функции.
- Ограничение видимости данных по строкам (RLS) — это когда разные пользователи видят одну таблицу, но разный состав строк в ней, то есть кому-то что-то нельзя показывать на уровне строк.
- Редактирование отображаемых данных (Masking) — это когда пользователи в одной колонке таблицы видят или данные, или только звездочки, то есть для каких-то пользователей информация будет закрыта. Технология определяет, какому пользователю что показывать с учетом уровня доступа.
- Разграничение доступа Security DBA/Application DBA/DBA — это, скорее, про ограничение доступа к самой СУБД, то есть сотрудников ИБ можно отделить от database-администраторов и application-администраторов. В open source таких технологий немного, в коммерческих СУБД их хватает. Они нужны, когда много пользователей с доступом к самим серверам.
- Ограничение доступа к файлам на уровне файловой системы. Можно выдавать права, привилегии доступа к каталогам, чтобы каждый администратор получал доступ только к нужным данным.
- Мандатный доступ и очистка памяти — эти технологии применяют редко.
- End-to-end encryption непосредственно СУБД — это client-side шифрование с управлением ключами на серверной стороне.
- Шифрование данных. Например, колоночное шифрование — когда вы используете механизм, который шифрует отдельную колонку базы.
Как это влияет на производительность СУБД?
Проведем тест c pgcrypto
Выборка из таблицы без функции шифрования
Время: 1,386 мсВыборка из таблицы с функцией шифрования:
Время: 50,203 мсРезультаты тестирования
| Без шифрования | Pgcrypto (decrypt) | |
| Выборка 1000 строк | 1,386 мс | 50,203 мс |
| CPU | 15% | 35% |
| ОЗУ | +5% |
Пример такого шифрования в MongoDB
Как все начиналось
Столь стремительный рост популярности облачных СУБД стал возможен благодаря двум удачно совпавшим по времени обстоятельствам. Исторически базы данных строились исходя из единственно возможного в то время представления о вертикальном масштабировании (scale-up), предполагавшем использование все более и более мощных серверов. В начале 2000-х годов апогеем этой линии развития в этом направления стали несколько мощных СУБД (Oracle, DB2 и др.), работавших на многопроцессорных Unix-серверах. Но с появлением в те же годы тонких серверов (высотой 1-2 U) и особенно серверов-лезвий, вертикальное масштабирование стало постепенно уступать свое место более дешевому горизонтальному масштабированию (scale-out), где серверная мощность наращивается за счет объединения в кластеры относительно маломощных серверов стандартной архитектуры x86. В итоге базы данных «пересели» на кластерные конфигурации, собранные из серверов стандартной архитектуры, или на гиперконвергентные системы.
Еще лет через пять появились облака, заметной частью компьютерного ландшафта они стали к 2010 г. И тут выяснилось, что версии СУБД, изначально рассчитанные на кластеры, оказались заранее подготовленными к портированию на инфраструктуры, предоставляемые провайдерами в виде облачных сервисов.
А далее помноженные на неограниченный потенциал масштабирования серверных ресурсов и объемов систем хранения, предоставляемых облачными провайдерами, эти два фактора создали синергетический эффект, ставший источником успеха облачных СУБД. Первыми на путь миграции в облака вступили реляционные базы данных, вскоре, после преодоления некоторых технических сложностей, к ним присоединились и нереляционные.
И сейчас все ведущие разработчики СУБД имеют облачную версию своих систем. Если посмотреть на последнюю Forrester Wave, посвященную рынку облачных СУБД, среди «лидеров» и их «сильных преследователей» — знакомые все лица: Oracle, Microsoft, IBM, SAP. С которыми, не без успеха, соперничают и чисто облачные вендоры. Находится в облаках место и бесплатным СУБД (хотя, конечно, их «бесплатность» еще более условна, чем при размещении в корпоративном ЦОДе) — MongoDB, которая смогла даже выйти в лидеры по версии Gartner, Redis («преследователь») популярная в России PostreSQL и некоторые другие.
Лидеры рынка облачных СУБД, 2 кв., 2019
Размер кружка на диаграмме означает коммерческий успех продуктов вендора в данной области.
SQLite3 manager LITE
Сайт производителя: http://www.pool-magic.net/sqlite-manager.htm
Цена: .
| Критерий | Оценка (от 0 до 2) | |
| Функциональность | 2 | |
| Цена | 2 | |
| Работа с UTF-8 | ||
| Русский интерфейс | ||
| Удобство | 1 | |
| Итог | 5 |
По сравнению с предыдущей программой “SQLite3 manager LITE” выглядит более функциональным. Кроме того, что можно просто просматривать данные в таблицах, также можно просматривать и создавать триггеры, индексы, представления и т.д. Дополнительно можно экспортировать все мета-данные базы данных. При этом можно создавать файлы с данными для экспорта таблиц в Paradox и Interbase.
Также в программе была предпринята попытка зделать, что-то вроде визуального мастера создания запросов наподобие MS Access, но, на мой взгляд, попытка успехом не увенчалась.
У бесплатной версии есть один недостаток – не понимает данные в кодировке UTF-8. Есть, конечно, возможность указать кодировку базы данных при открытии файла, но в списке кодировок UTF-8 отсутствует. Как работает Full-версия программы я так и не увидел, т.к. на сайте производителя чёрт ногу сломит. Висит какой-то непонятный javascript, выводящий непонятную инфу. В общем, сложилось впечатление, что проект успешно заглох.
Сколько стоит бесплатный сыр
Стоимость владения
Для баз данных, как и для любого софта, существует понятие полной стоимости владения (Total Cost of Ownership, TCO).
Приобретая программный продукт, мы вкладываем деньги не только в лицензии — для того чтобы получить какой-то эффект от приобретения и заставить ПО реально работать, необходимо затратить деньги и на множество сопутствующих вещей.
Вообще говоря, ТСО — это схема для вычисления всех затрат, связанных с ПО. Таких схем существует несколько, и компании-производители программного обеспечения постоянно соревнуются в снижении этого показателя (причем обычно выигрывает тот, кто измеряет).
Традиционно считается, что ТСО состоит из трех частей:
стоимость аппаратного обеспечения;
стоимость программного обеспечения;
стоимость персонала, необходимого для обслуживания ПО.
Посчитали — прослезились…
Прежде всего, конечно, стоит обратиться к стоимости персонала. Хорошо известно, что для нормального функционирования системы на той же Oracle нужен профессиональный администратор базы данных. Конечно, пока система внедряется, эту работу обычно выполняют разработчики, но потом без администратора не обойтись. Сколько нужно платить толковому администратору, можете выяснить сами.
Затем — hardware. 1 Гбайт оперативной памяти для системы, основанной, скажем, на Firebird и обслуживающей 30–50 пользователей, вполне достаточно, тогда как для Oracle потребуется куда больше.
И несколько слов о стоимости программного обеспечения. Да, сама СУБД бесплатна, но стоит посмотреть, есть ли для нее все необходимые драйверы, инструменты администратора и разработчика, и главное, сколько они стоят!
И рос он не по годам, а по часам
С ограничением размера базы данных, прямо скажем, загвоздка. Сейчас часто нужно хранить в базах данных фотографии и видеоматериалы, а для данных такого рода 4 Гбайт недостаточно. Поэтому, если в вашем проекте предусмотрено хранение мультимедии, нужна СУБД без ограничений на размер базы данных.
Вход бесплатно, выход — нет
Все новые «коммерческие бесплатные» базы данных рассчитаны на то, чтобы через «попробовать» молодые разработчики и целые компании становились адептами этих СУБД или просто клиентами, покупая и используя в своей работе их базы данных.
Немаловажен и другой вопрос — как долго будут поддерживаться бесплатные версии СУБД? Например, компания Borland, выпустив в 2000 году InterBase 6 Open Edition, которую стали использовать миллионы разработчиков, выпустила только два небольших апдейта, после чего вернулась к коммерческой модели, прекратив поддержку Open Edition. И если бы не появление Firebird, то выбравшие Inter-Base 6 Open Source разработчики должны были бы либо купить лицензии новых версий InterBase, либо переходить на другие СУБД.
Обратите внимание, что многие «бесплатные» СУБД не открывают своих кодов, поэтому ситуация очень напоминает мышеловку: бегите сюда, мыши, кушайте сыр, мышеловка скоро захлопнется!