Как выполнить поиск файлов и папок в linux
Содержание:
- Use Grep to Find Files Based on Content
- Сравнение файлов Linux с помощью GUI
- Основное регулярное выражение
- Найти файлы по дате изменения
- Поиск по размеру файла
- grep — что это и зачем может быть нужно
- Работа с найденными файлами
- Команда grep и регулярные выражения
- Options and Optimizations for Finding Files in Linux Using the Command Line
- How To Manage Files Using Plesk?
- Разница между locate и find Линукс
- Найти файлы по типу
- Выполнение и объединение команд
- Команда sed в Linux
- Примеры использования sed
- Основные опции команды Linux find
- Найти и удалить файлы
- Как с awk или sed выбрать строки между двумя шаблонами, которые могут встречаться несколько раз
- Поиск полных слов
- Найти файлы по разрешениям
- Найти и удалить файлы
- Итоги
Use Grep to Find Files Based on Content
The find command in Linux is great but it can only filter the directory tree according to filename and meta data. To search files based on what they contain you’ll need a tool like grep. Take a look:
This goes through every object in the current directory tree (.) that’s a file (-type f) and then runs grep ” forinstance ” for every file that matches, then prints them on the screen (-print). The curly braces ({}) are a placeholder for those results matched by the Linux find command. The {} go inside single quotes (‘) so that grep isn’t given a misshapen file name. The -exec command is ended with a semicolon (;), which also needs an escape (\;) so that it doesn’t end up being interpreted by the shell.
Before -exec was implemented, xargs would have been used to create the same kind of output:
Сравнение файлов Linux с помощью GUI
Существует несколько отличных инструментов для сравнения файлов в linux в графическом интерфейсе. Вы без труда разберетесь как их использовать. Давайте рассмотрим несколько из них:
1. Kompare

Kompare — это графическая утилита для работы с diff, которая позволяет находить отличия в файлах, а также объединять их. Написана на Qt и рассчитана в первую очередь на KDE. Кроме сравнения файлов утилита поддерживает сравнение каталогов и позволяет создавать и применять патчи к файлам.
2. Meld

Это легкий инструмент для сравнения и объединения файлов. Он позволяет сравнивать файлы, каталоги, а также выполнять функции системы контроля версий. Программа создана для разработчиков и позволяет сравнивать до трёх файлов. Можно сравнивать каталоги и автоматически объединять сравниваемые файлы. Кроме того поддерживаются такие системы контроля версий, как Git.
3. Diffuse

Diffuse — еще один популярный и достаточно простой инструмент для сравнения и слияния файлов. Он написан на Python 2. Поэтому в современных версиях Ubuntu программу будет сложно установить. Поддерживается две основные возможности — сравнение файлов и управление версиями. Вы можете редактировать файлы прямо во время просмотра.
4. KDiff3

KDiff3 — еще один отличный, свободный инструмент для сравнения файлов в окружении рабочего стола KDE. Он входит в набор программ KDevelop и работает на всех платформах, включая Windows и MacOS. Можно выполнить сравнение до трех файлов Linux или даже сравнить каталоги. Кроме того, есть поддержка слияния и ручного выравнивания.
5. TkDiff

Это очень простая утилита для сравнения файлов написанная на основе библиотеки tk. Она позволяет сравнивать только два файла, поддерживает поиск и редактирование сравниваемых файлов.
Основное регулярное выражение
GNU Grep имеет три набора функций регулярных выражений : базовый, расширенный и Perl-совместимый.
По умолчанию шаблон интерпретируется как базовое регулярное выражение, где все символы, кроме метасимволов, на самом деле являются регулярными выражениями, которые соответствуют друг другу.
Ниже приведен список наиболее часто используемых метасимволов:
-
Используйте символ (каретка), чтобы соответствовать выражению в начале строки. В следующем примере строка будет соответствовать только в том случае, если она встречается в самом начале строки.
-
Используйте символ (доллар), чтобы соответствовать выражению в конце строки. В следующем примере строка будет соответствовать только в том случае, если она встречается в самом конце строки.
-
Используйте символ (точка), чтобы соответствовать любому отдельному символу. Например, для сопоставления всего, что начинается с двух символов и заканчивается строкой , вы можете использовать следующий шаблон:
-
Используйте (скобки) для соответствия любому отдельному символу, заключенному в скобки. Например, найдите строки, содержащие или « , вы можете использовать следующий шаблон:
-
Используется для соответствия любому отдельному символу, не заключенному в скобки. Следующий шаблон будет соответствовать любой комбинации строк, содержащих , например , и так далее, но не будет совпадать со строками, содержащими ,
Чтобы избежать специального значения следующего символа, используйте символ (обратный слеш).
Найти файлы по дате изменения
Команда также может искать файлы на основе их последнего изменения, доступа или времени изменения.
То же, что и при поиске по размеру, используйте символы плюс и минус для «больше чем» или «меньше чем».
Допустим, несколько дней назад вы изменили один из файлов конфигурации dovecot, но забыли, какой именно. Вы можете легко отфильтровать все файлы в который заканчивается на и был изменен за последние пять дней:
Вот еще один пример фильтрации файлов по дате модификации с использованием опции . Приведенная ниже команда перечислит все файлы в каталоге которые были изменены или более дней назад:
Поиск по размеру файла
df -h /boot
Filesystem Size Used Avail Use% Mounted on
/dev/sda1 1014M 194M 821M 20% /boot
Найти обычные файлы определённого размера
Чтобы найти обычные файлы нужно использовать
-type f
find /boot -size +20000k -type f
find: ‘/boot/efi/EFI/centos’: Permission denied
find: ‘/boot/grub2’: Permission denied
/boot/initramfs-0-rescue-389ee10be1b38d4281b9720fabd80a37.img
/boot/initramfs-3.10.0-1160.el7.x86_64.img
/boot/initramfs-3.10.0-1160.2.2.el7.x86_64.img
Файлы бывают следующих типов:
— : regular file
d : directory
c : character device file
b : block device file
s : local socket file
p : named pipe
l : symbolic link
Подробности в статье —
«Файлы в Linux»
find /boot -size +10000k -type f
find: ‘/boot/efi/EFI/centos’: Permission denied
find: ‘/boot/grub2’: Permission denied
/boot/initramfs-0-rescue-389ee10be1b38d4281b9720fabd80a37.img
/boot/initramfs-3.10.0-1160.el7.x86_64.img
/boot/initramfs-3.10.0-1160.el7.x86_64kdump.img
/boot/initramfs-3.10.0-1160.2.2.el7.x86_64.img
/boot/initramfs-3.10.0-1160.2.2.el7.x86_64kdump.img
То же самое плюс показать размер файлов
find /boot -size +10000k -type f -exec du -h {} \;
find: ‘/boot/efi/EFI/centos’: Permission denied
find: ‘/boot/grub2’: Permission denied
60M /boot/initramfs-0-rescue-389ee10be1b38d4281b9720fabd80a37.img
21M /boot/initramfs-3.10.0-1160.el7.x86_64.img
13M /boot/initramfs-3.10.0-1160.el7.x86_64kdump.img
21M /boot/initramfs-3.10.0-1160.2.2.el7.x86_64.img
14M /boot/initramfs-3.10.0-1160.2.2.el7.x86_64kdump.img
grep — что это и зачем может быть нужно
Про «репку» (как я её называю) почему-то в курсе не многие, что печалит. «Унылая» (не в обиду) формулировка из Википедии звучит примерно так:
grep — утилита командной строки, которая находит на вводе строки, отвечающие заданному регулярному выражению, и выводит их, если вывод не отменён специальным ключом.
Не сильно легче, но доступнее, можно сформулировать так:
grep — утилита командной строки, используется для поиска и фильтрации текста в файлах, на основе шаблона, который (шаблон) может быть регулярным выражением.
Если всё еще ничего не понятно, то условно говоря это удобный поиск текста везде и всюду, в особенности в файлах, директория в и тп. Удобно распарсивать логи и их содержимое, не прибегая к софту, как это бывает в Windows.
Справку можно вычленить так же как по find, т.е методом pgrep, fgrep, egrep и черт знает что еще:
Или:
Расписывать все ключи и даже основные тут (вы еще помните, что это блоговая часть сайта?) не буду, так как в отличии от find’а, последних тут вообще страшное подмножество, особенно учитывая, что существуют pgrep, fgrep, egrep и черт знает что еще, которые, в некотором смысле тоже самое, но для определенных целей.
Потрясающе удобная штука, которая жизненно необходима, особенно, если Вы что-то когда-то где-то зачем-то администрировали. Взглянем на примеры.
Работа с найденными файлами
Для того чтобы выполнять действия над найденными документами применяется find exec Linux. Чтобы получить подробную информацию по каждому результату, выполняют «$find . -exec ls -ld {} \;». Для удаления все текстовых типов во временную папку прописывают «$find /tmp -type f -name «*.txt» -exec rm -f {} \;». А для того чтобы, к примеру, удалить все данные, больше 50 мегабайт в объеме, выполняют «$ find /home/bob/dir -type f -name *.log -size +5M -exec rm -f {} \;».
Применение опции exec
Теперь стало ясно, как найти файл или директорию в Линукс. Все крайне просто, ведь процедура основана на использовании команды find, которая выводит все содержимое результатов по определенным критериям. В сторонних справочниках к различным дистрибутивам можно почитать более подробное описание опций find, помогающей найти любую папку в Linux.
Команда grep и регулярные выражения
Регулярные выражения (Regular Expressions) это система синтаксического разбора текстовых фрагментов по формализованному шаблону, основанная на системе записи ОБРАЗЦОВ для поиска. Проще говоря, регулярное выражение — тот же, уже привычный нам ОБРАЗЕЦ для поиска, только составленный по определенным правилам. Как математические формулы составляются при помощи набора операторов (плюс, минус, степень, корень и прочее), так и регулярные выражения конструируются при помощи различных операторов (?, *, +, {n} и прочие).
Тема регулярных выражений настолько обширна, что требует для своего освещения отдельной статьи; в данной статье мы не будем ее подробно разбирать. Скажу лишь, что существует несколько версий синтаксиса регулярных выражений: Базовый (basic) BRE, Расширенный (extended) ERE и регулярные выражения языка Perl.
—basic-regexp
Рассматривает ОБРАЗЕЦ как базовое регулярное выражение. Эта опция используется по умолчанию.
—extended-regexp
Рассматривает ОБРАЗЕЦ как расширенное регулярное выражение.
—perl-regexp
Рассматривает ОБРАЗЕЦ как регулярное выражение языка Perl.
Опция -F
—fixed-strings
Рассматривает ОБРАЗЕЦ как список «фиксированных выражений» (fixed strings — термин из области регулярных выражений), разделенных символами новой строки. Будет искать соответствия любому из них.
Кроме того, существуют две альтернативные команды EGREP и FGREP. Обе они соответствуют опциям -E и -F соответственно.
Опции —help и —version (-V) общеизвестны, и я не буду на них останавливаться.
Options and Optimizations for Finding Files in Linux Using the Command Line
The default configuration for ignores
. If you want to follow and return symbolic links, add the option to the command, as shown below:
This command enables the maximum optimization level () and allows to follow symbolic links (). searches the entire directory tree beneath for files that end with .
optimizes its filtering strategy to increase performance. Three user-selectable optimization levels are specified as , , and . The optimization is the default and forces to filter based on filename before running all other tests.
Optimization at the level prioritizes filename filters, as in , and then runs all file-type filtering before proceeding with other more resource-intensive conditions. Level optimization allows to perform the most severe optimization and reorders all tests based on their relative expense and the likelihood of their success.
| Command | Description |
|---|---|
| Filter based on filename first (default). | |
| File name first, then file-type. | |
| Allow to automatically re-order the search based on efficient use of resources and likelihood. of success | |
| Search current directory as well as all sub-directories X levels deep. | |
| Search without regard for text case. | |
| Return only results that do not match the test case. | |
| Search for files. | |
| Search for directories. |
How To Manage Files Using Plesk?
Let’s say you have a website that’s all ready to go on your laptop/desktop and you’d like to use File Manager to upload it to the Plesk on Linux server:
- On your machine, you’ll need to take the folder with all of your website’s files on it and add it to a compressed archive in one of the usual formats (ZIP, RAR, TAR, TGZ, or TAR.GZ).
- In Plesk, go to Files, click the httpdocs folder to open it, click Upload, choose the archive file, and then click Open.
- As soon as you’ve uploaded it, click in the checkbox you see alongside and then on Extract Files.
How to Edit Files in File Manager
File Manager lets you edit your website pages by default. To do this you can use:
- An HTML editor or a “what-you-see-is-what-you-get” style of editor, which is a nice option because it adds the HTML tags for you. If you aren’t all that confident with HTML then this can be a helpful option.
- Code editor. When you open HTML files with this one you’ll be presented with text where the HTML syntax is highlighted. If you’re comfortable with adding HTML tags yourself then code editor is for you.
- Text editor. HTML files are opened as ordinary text with this one.
Your Plesk administrator may have already et up the Rich Editor extension, in which case you can use it for HTML file editing. Rich Editor works in a what-you-see-is-what-you-get fashion, just like Code Editor, although it’s better specced with features like a spellchecker for instance.
Here’s how to use File Manager to edit a file:
- Put the cursor over the file and the line that corresponds with it will show a highlight.
- Open the context menu for the file by clicking on it.
- Click Edit in … Editor (this will vary depending on your chosen editor).
How to Change Permissions with File Manager
There are some web pages and files that you don’t necessarily want to share with the world, and that’s where altering their permissions settings can come in handy.
To achieve this, find the item you want to restrict Internet access for like this:
- Place your cursor over it and wait for the highlight to appear as in the previous example.
- Click on the file to open its context menu and do the same again on Change Permissions.
- Make your change and then hit OK. If you’d like to find out more about how to look at and alter permissions in Setting File and Directory Access Permissions.
File Manager’s default approach is to change permissions in a non-recursive manner, so consequently, sub-files and directories don’t aren’t affected by the changed permissions of the higher-level directories they belong to. With Plesk for Linux, you can make File Manager modify permissions in a recursive manner, assuming that your Plesk administrator set up the Permissions Recursive extension and that you understand the octal notation of file permissions.
To enable recursive editing of access permissions:
- Place the cursor over the directory and wait for the highlight.
- Click to open its context menu and then again on Set Permissions Recursive.
- Now you can edit them. “Folder Permissions” is talking about the higher-level directory and any of its associated sub-directories. “File Permissions” applies to sub-files in this instance.
- When you’ve completed your permission amendments, click OK.
Разница между locate и find Линукс
Многие новички часто спрашивают, почему в операционной системе Линукс есть две одинаковые команды: locate и find, ведь выполняют они одни и те же действия. Зачем использовать одну, если есть другая, и наоборот.
На самом деле, различия есть, и они весьма существенные. Цель команд одна – найти файл по заданным характеристикам или имени, а вот работают они по-разному. В случае с find поиск выполняется в реально существующей системе. Он более медленный, но его результаты всегда актуальны. К тому же, у find больше опций.
Команда locate делает все то же самое, но использует для поиска базу данных, которая была создана ранее (командой updatebd). Процедура нахождения файла или папки выполняется быстрее, но системе приходится пользоваться «старой» базой данных и искать имена или их части.
Для поиска по имени в Linux используют find name
Найти файлы по типу
Иногда вам может потребоваться поиск определенных типов файлов, таких как обычные файлы, каталоги или символические ссылки. В Linux все является файлом.
Для поиска файлов по их типу используйте параметр и один из следующих дескрипторов, чтобы указать тип файла:
- : обычный файл
- : каталог
- : символическая ссылка
- : символьные устройства
- : блочные устройства
- : именованный канал (FIFO)
- : сокет
Например, чтобы найти все каталоги в текущем рабочем каталоге , вы должны использовать:
Типичным примером может быть рекурсивное изменение разрешений файлов веб-сайтов на и разрешений каталогов на с помощью команды :
Выполнение и объединение команд
Утилита find позволяет выполнять любую вспомогательную команду на все найденные файлы; для этого используется параметр –exec. Базовый синтаксис выглядит так:
find параметры_поиска -exec команда_и_параметры {} \;
Символы {} используются в качестве заполнителя для найденных файлов. Символы \; используются для того, чтобы find могла определить, где заканчивается команда.
Для примера можно найти файлы с привилегиями 644 (как в предыдущем разделе) и изменить их привилегии на 664:
cd ~/test
find . -perm 644 -exec chmod 664 {} \;
Затем можно сменить привилегии каталога:
find . -perm 755 -exec chmod 700 {} \;
Чтобы связать несколько результатов, используйте команды -and или -or. Команда –and предполагается, если она опущена.
find . -name file1 -or -name file9
Команда sed в Linux
Сначала рассмотрим синтаксис команды:
$ sed опции -e команды файл
А вот её основные опции:
- -n, —quiet — не выводить содержимое буфера шаблона в конце каждой итерации;
- -e — команды, которые надо выполнить для редактирования;
- -f — прочитать команды редактирования из файла;
- -i — сделать резервную копию файла перед редактированием;
- -l — указать свою длину строки;
- -r — включить поддержку расширенного синтаксиса регулярных выражений;
- -s — если передано несколько файлов, рассматривать их как отдельные потоки, а не как один длинный.
Я понимаю, что сейчас всё очень сложно, но к концу статьи всё прояснится.
1. Как работает sed
Теперь нужно понять как работает команда sed. У утилиты есть два буфера, это активный буфер шаблона и дополнительный буфер. Оба изначально пусты. Программа выполняет заданные условия для каждой строки в переданном ей файле.
sed читает одну строку, удаляет из неё все завершающие символы и символы новой строки и помещает её в буфер шаблона. Затем выполняются переданные в параметрах команды, с каждой командой может быть связан адрес, это своего рода условие и команда выполняется только если подходит условие.
Когда всё команды будут выполнены и не указана опция -n, содержимое буфера шаблона выводится в стандартный поток вывода перед этим добавляется обратно символ перевода строки. если он был удален. Затем запускается новая итерация цикла для следующей строки.
Если не используются специальные команды, например, D, то после завершения одной итерации цикла содержимое буфера шаблона удаляется. Однако содержимое предыдущей строки хранится в дополнительном буфере и его можно использовать.
2. Адреса sed
Каждой команде можно передать адрес, который будет указывать на строки, для которых она будет выполнена:
- номер — позволяет указать номер строки, в которой надо выполнять команду;
- первая~шаг — команда будет выполняется для указанной в первой части сроки, а затем для всех с указанным шагом;
- $ — последняя строка в файле;
- /регулярное_выражение/ — любая строка, которая подходит по регулярному выражению. Модификатор l указывает, что регулярное выражение должно быть не чувствительным к регистру;
- номер, номер — начиная от строки из первой части и заканчивая строкой из второй части;
- номер, /регулярное_выражение/ — начиная от сроки из первой части и до сроки, которая будет соответствовать регулярному выражению;
- номер, +количество — начиная от номера строки указанного в первой части и еще плюс количество строк после него;
- номер, ~число — начиная от строки номер и до строки номер которой будет кратный числу.
Если для команды не был задан адрес, то она будет выполнена для всех строк. Если передан один адрес, команда будет выполнена только для строки по этому адресу. Также можно передать диапазон адресов. Тогда адреса разделяются запятой и команда будет выполнена для всех адресов диапазона.
3. Синтаксис регулярных выражений
Вы можете использовать такие же регулярные выражения, как и для Bash и популярных языков программирования. Вот основные операторы, которые поддерживают регулярные выражения sed Linux:
- * — любой символ, любое количество;
- \+ — как звездочка, только один символ или больше;
- \? — нет или один символ;
- \{i\} — любой символ в количестве i;
- \{i,j\} — любой символ в количестве от i до j;
- \{i,\} — любой символ в количестве от i и больше.
4. Команды sed
Если вы хотите пользоваться sed, вам нужно знать команды редактирования. Рассмотрим самые часто применяемые из них:
- # — комментарий, не выполняется;
- q — завершает работу сценария;
- d — удаляет буфер шаблона и запускает следующую итерацию цикла;
- p — вывести содержимое буфера шаблона;
- n — вывести содержимое буфера шаблона и прочитать в него следующую строку;
- s/что_заменять/на_что_заменять/опции — замена символов, поддерживаются регулярные выражения;
- y/символы/символы — позволяет заменить символы из первой части на соответствующие символы из второй части;
- w — записать содержимое буфера шаблона в файл;
- N — добавить перевод строки к буферу шаблона;
- D — если буфер шаблона не содержит новую строку, удалить его содержимое и начать новую итерацию цикла, иначе удалить содержимое буфера до символа перевода строки и начать новую итерацию цикла с тем, что останется;
- g — заменить содержимое буфера шаблона, содержимым дополнительного буфера;
- G — добавить новую строку к содержимому буфера шаблона, затем добавить туда же содержимое дополнительного буфера.
Утилите можно передать несколько команд, для этого их надо разделить точкой с запятой или использовать две опции -e. Теперь вы знаете всё необходимое и можно переходить к примерам.
Примеры использования sed
Теперь рассмотрим примеры sed Linux, чтобы у вас сложилась целостная картина об этой утилите. Давайте сначала выведем из файла стройки с пятой по десятую. Для этого воспользуемся командой -p. Мы используем опцию -n чтобы не выводить содержимое буфера шаблона на каждой итерации, а выводим только то, что нам надо. Если команда одна, то опцию -e можно опустить и писать без неё:
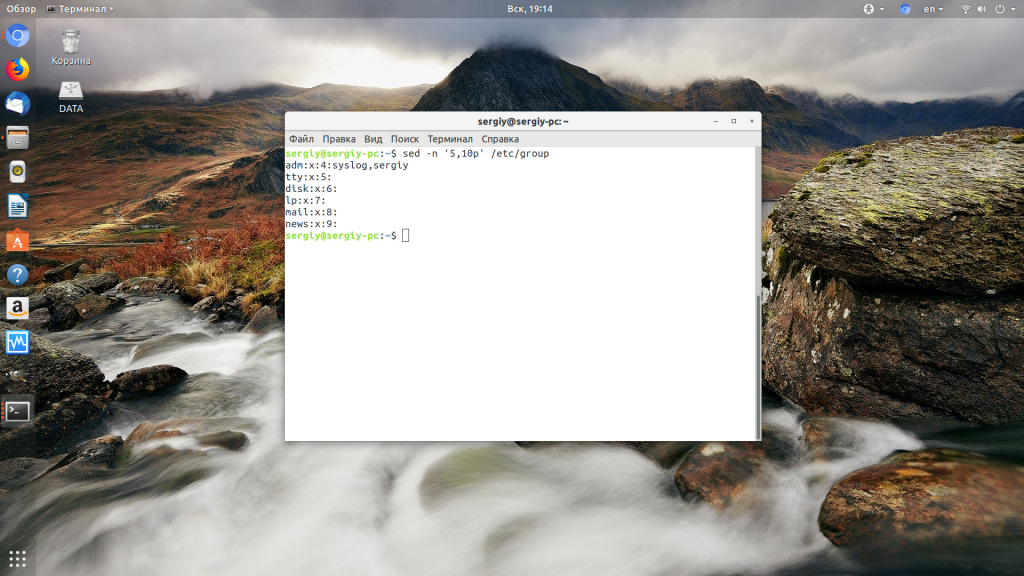
Или можно вывести весь файл, кроме строк с первой по двадцатую:

Здесь наоборот, опцию -n не указываем, чтобы выводилось всё, а с помощью команды d очищаем ненужное. Дальше рассмотрим замену в sed. Это самая частая функция, которая применяется вместе с этой утилитой. Заменим вхождения слова root на losst в том же файле и выведем всё в стандартный вывод:

Флаг g заменяет все вхождения, также можно использовать флаг i, чтобы сделать регулярное выражение sed не зависимым от регистра. Для команд можно задавать адреса. Например, давайте выполним замену 0 на 1000, но только в строках с первой по десятую:

Переходим ещё ближе к регулярным выражением, удалим все пустые строки или строи с комментариями из конфига Apache:

Под это регулярное выражение (адрес) подпадают все строки, которые начинаются с #, пустые, или начинаются с пробела, а за ним идет решетка. Регулярные выражения можно использовать и при замене. Например, заменим все вхождения p в начале строки на losst_p:

Если вам надо записать результат замены в обратно в файл можно использовать стандартный оператор перенаправления вывода > или утилиту tee. Например:
Также можно использовать опцию -i, тогда утилита не будет выполнять изменения в переданном ей файле:

Если надо сохранить оригинальный файл, достаточно передать опции -i в параметре расширение для файла резервной копии.
Основные опции команды Linux find
Очень часто в процессе работы появляется необходимость найти тот или иной файл (папку). Часто даже название файла забываются, поэтому приходиться выполнять поиск по другим критериям: правам доступа, размеру, типа файла и его расширению. Специально для этих целей и придумана команда find. Она позволяет выполнять поиск файла или папки в Linux по имени, а также создавать различные запросы для файловой системы и жесткого диска для нахождения нужных данных. Преимуществом использования данной команды становится возможность не только выполнять поиск по всем каталогам, созданным в операционной системе, но в отдельных указанных папках.
Пример использования
Важно! Возможности команды достаточно обширны, как и список предлагаемых к использованию опций. В этом материале будут описаны лишь наиболее важные и популярные из них, так как для рассмотрения всех атрибутов и параметров, доступных к применению, потребует много времени
Помимо поиска на внутренних носителях, find может спокойно искать данные по заданным параметрам на дисках типа NFS, но только в том случае, если пользователь обладает соответствующими разрешениями. В таких случаях обычно все выполняется на фоне, так как раскрытие дерева каталога занимает существенное количество времени.
Найти и удалить файлы
Чтобы удалить все совпадающие файлы, добавьте параметр в конец выражения соответствия.
Убедитесь, что вы используете эту опцию, только если уверены, что результат соответствует файлам, которые вы хотите удалить. Перед использованием опции всегда рекомендуется распечатать совпадающие файлы.
Например, чтобы удалить все файлы, заканчивающиеся на из , вы должны использовать:
Используйте параметр с особой осторожностью. Команда оценивается как выражение, и если вы сначала добавите опцию , команда удалит все, что находится ниже указанных вами начальных точек.. Когда дело доходит до каталогов, может удалять только пустые каталоги, как и
Когда дело доходит до каталогов, может удалять только пустые каталоги, как и .
Как с awk или sed выбрать строки между двумя шаблонами, которые могут встречаться несколько раз
Могу ли я используя awk или sed выбрать строки, которые встречаются между двумя различными шаблонами маркеров? Может быть несколько секций, отмеченных этими шаблонами.
Например, допустим есть файл, содержащий:
abc def1 ghi1 jkl1 mno abc def2 ghi2 jkl2 mno pqr stu
Начальным паттерном является abc, а конечным паттерном является mno, мне нужно, чтобы вывод был таким:
def1 ghi1 jkl1 def2 ghi2 jkl2
Есть ли способ в sed или awk сделать так, чтобы находилось не единичное совпадение, а чтобы поиск повторялся пока не будет достигнут конец файла?
Решение:
Нужно использовать awk с флагом, который будет запускать вывод когда необходимо:
awk '/abc/{flag=1;next}/mno/{flag=0}flag' ФАЙЛ
def1
ghi1
jkl1
def2
ghi2
jkl2
Как это работает?
- /abc/ совпадает со строками, имеющими этот текст, также делает /mno/.
- /abc/{flag=1;next} устанавливает flag, когда найден текст abc. Затем эта строка пропускается.
- /mno/{flag=0} убирает flag, когда найдено mno.
- Конечный flag — это шаблон с дефолтным действием, которым является print $0: если флаг равен 1, то печатается строка. Таким образом, он напечатает все строки, появившиеся с момента появления abc и до следующего mno. Это также напечатает строки от последнего совпадения abc до конца файла.
Более детальное описание и примеры, вместе со случаями, когда паттерны показываются или нет, будут ниже.
Если вы хотите, чтобы печаталось всё между, а также сами паттерны, тогда вы можете использовать:
awk '/abc/{a=1}/mno/{print;a=0}a' ФАЙЛ
Или так:
awk '/abc/{a=1} a; /mno/{a=0}' ФАЙЛ
Или даже так:
awk '/abc/,/mno/' ФАЙЛ
Используя sed:
sed -n -e '/^abc$/,/^mno$/{ /^abc$/d; /^mno$/d; p; }'
Опция -n означает не печатать по умолчанию (эта опция разъяснена выше).
Шаблон ищет строки, содержащие только с abc до только mno, затем выполняет действия в { … }.
Первое действие удаляет строку abc, второе удаляет строку mno, а p печатает оставшиеся строки. Вы можете расслабить регулярные выражения по мере необходимости. Любые строки за пределами abc..mno просто не печатаются.
Поиск полных слов
При поиске строки будут отображаться все строки, в которых строка встроена в более крупные строки.
Например, если вы ищете «gnu», все строки, где «gnu» встроен в более крупные слова, такие как «cygnus» или «magnum», будут совпадать:
Чтобы вернуть только те строки, в которых указанная строка представляет собой целое слово (заключенное не в словах), используйте параметр (или ).
Символов слова включают в себя буквенно — цифровые символы ( , и ) и подчеркивание ( ). Все остальные символы рассматриваются как несловесные символы.
Если вы выполните ту же команду, что и выше, включая опцию, команда вернет только те строки, которые включены в качестве отдельного слова.
Найти файлы по разрешениям
Параметр позволяет вам искать файлы на основе прав доступа к файлам.
Например, чтобы найти все файлы с разрешениями ровно внутри каталога , вы должны использовать:
Вы можете поставить перед числовым режимом знак минус или косую черту .
Когда в качестве префикса используется косая черта , то по крайней мере одна категория (пользователь, группа или другие) должна иметь по крайней мере соответствующие биты, установленные для соответствия файлу.
Рассмотрим следующий пример команды:
Приведенная выше команда будет соответствовать всем файлам с разрешениями на чтение, установленными для пользователя, группы или других.
Если в качестве префикса используется минус , то для соответствия файла необходимо установить хотя бы указанные биты. Следующая команда будет искать файлы, которые имеют права на чтение и запись для владельца и группы и доступны для чтения другим пользователям:
Найти и удалить файлы
Чтобы удалить все соответствующие файлы, добавьте опцию в конец выражения соответствия.
Убедитесь, что вы используете эту опцию, только если вы уверены, что результат соответствует файлам, которые вы хотите удалить. Рекомендуется распечатать соответствующие файлы перед использованием параметра.
Например, чтобы удалить все файлы, заканчивающиеся на из, вы должны использовать:
Используйте опцию с особой осторожностью. Командная строка find оценивается как выражение, и если вы сначала добавите параметр, команда удалит все, что находится ниже указанных вами начальных точек.. Когда дело доходит до каталогов, можно удалить только пустые каталоги так же, как .
Когда дело доходит до каталогов, можно удалить только пустые каталоги так же, как .
Итоги
Команды find и locate – отличные инструменты для поиска файлов в UNIX‐подобных операционных системах. Каждая из этих утилит имеет свои преимущества.
Несмотря на то, что команды find и locate сами по себе очень мощны, их действие можно расширить, комбинируя их с другими командами. Научившись работать с find и locate, попробуйте фильтровать их результаты при помощи команд wc, sort и grep.
Вероятно, Вам знакома такая проблема: Есть файл, и Вы не помните, куда его положили.
В этом случае удобна команда find . Как ее использовать? Конечно, к этой утилите поставляется большая man-страница, но мы рассмотрим некоторые типичные случаи. Просмотреть дерево каталогов, начиная с текущего, и найти файл lostfile.txt:
Если Вы ищете в большом дереве каталогов, команда find может работать довольно медленно. Иногда удобнее использовать команду locate . Она не ищет файл непосредственно в файловой системе, а просматривает свою базу данных. Такой метод намного быстрее, но база данных может устареть. В некоторых дистрибутивах эта база модифицируется каждую ночь. Вы можете время от времени вручную выполнять команду updatedb , чтобы ее модифицировать. locate ищет подстроки:
Допустимое количество орфографических ошибок зависит от длины имени файла, но может быть установлено с помощью опции -t. Чтобы разрешить максимум 2 ошибки и использовать служебный символ просто наберите: