9 способов найти удаленный сайт или страницу
Содержание:
- Как посмотреть сайт в прошлом: полная историческая проверка
- Как выглядел сайт раньше
- Сайт студента-программиста
- Механический метод удаления
- Как использовать веб-архив?
- Сайт «Аэрофлота»
- Поисковые системы
- Архивы веб-страниц, постоянные
- Сохранить как HTML-файл
- Как найти уникальный контент для своего сайта
- Кэш браузера
- Разбираем на примере как правильно подойти к оценке первичной информации
- Создание задачи
- Что если сохраненной страницы нет?
- Для чего может понадобиться сохраненная копия сайта?
- Как узнать историю сайта? Пошаговая инструкция
- Как узнать историю сайта? Пошаговая инструкция
Как посмотреть сайт в прошлом: полная историческая проверка
Рад приветствовать вас на блоге. Огромное число сайтов работает на просторах интернета. У каждого есть своя история создания и изменения. Можно ли ее посмотреть и насколько глубоко?
Сегодня покажу, как посмотреть сайт в прошлом при помощи специальных инструментов и сервисов. Сделать это можно при помощи 3 способов. Про них желательно знать каждому вебмастеру еще до оформления домена, так как его история может повлиять на дальнейшее продвижение ресурса.
Сохраненные копии сайта в поисковых системах
Сейчас опишу один из самых простых подходов. Знакомы с поисковыми системами Яндекс и Google. Благодаря их возможностям, можно посмотреть содержание страницы и внешний вид сайта в недалеком прошлом. Как же это сделать?
Опишу порядок действий по пунктам.
- Вводим адрес страницы и выполняем поиск.
- Нажимаем на треугольник и открываем контекстное меню (показано стрелкой на картинке).
- Переходим к сохраненной копии. Сверху указывается дата её сохранения.
Как видите, ничего сложного нет. Однако стоит учесть, что для применения описанного способа искомый url должен находится в индексе поисковика.
Просмотр изменений на сайте в архивах интернета
Я раньше долго искал, где можно посмотреть изменения ресурсов во времени в наглядном виде. Нашел. Сейчас продемонстрирую его работу на примере своего блога. Покажу его состояние в 2014 году, а внешний облик на 2016 год можете наблюдать прямо сейчас.
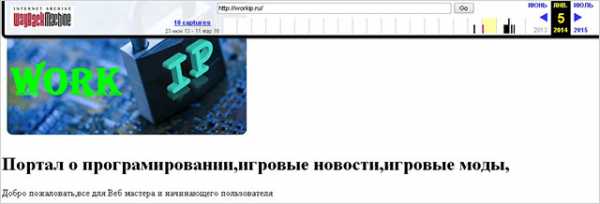
Судя по всему, в 2014 здесь был какой-то портал о программировании и играх. Похоже, он был закрыт, так как домен я приобрел в 2015 году. Вот только заметил я эту особенность после покупки. После обнаружения я провел подробный анализ ситуации и решил, что доменное имя можно оставить, так как с его репутацией было все в порядке.
На заметку — для продвижения новых проектов я рекомендую брать адреса с чистой историей. Можно взять url и с солидным прошлым в случае, когда тематика «предшественников» была близка к текущей, а репутация положительная. Найти такие домены по обычной цене — это редкость.
Возвращаясь к основной теме, покажу, где можете посмотреть содержание электронного ресурса на состояние минувших лет. Распишу пошаговую последовательность действий.
- Открываем http://archive.org/web/.
- Вводим название домена и запускаем поиск.
- Выбираем одну из доступных для просмотра дат и смотрим исторические сведения.
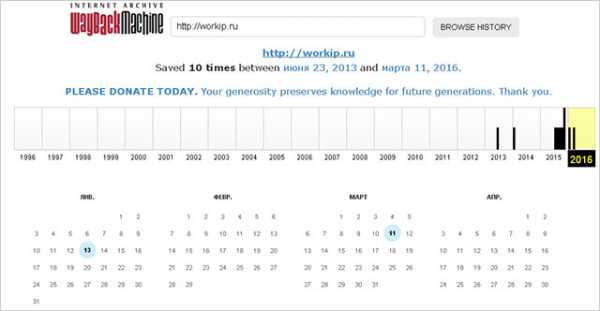
Как видите на скриншоте, конкретно для моего проекта для просмотра доступны данные, начиная с 2013 года.
Дата создания сайта
Как ее узнать? Для просмотра даты регистрации доменного имени можно пользоваться специальным сервисом — http://www.whois-service.ru/. Для поиска я введу свой домен и среди прочих результатов вижу строки, показанные на картинке ниже.
На иллюстрации видно, что регистрация была совершена в 2015 году, а оплата до мая 2017. Если внимательно читали статью, то знаете, что визуально прошлое моего домена можно увидеть с 2013, однако этой даты в результатах нет. В принципе все правильно — отображается актуальная информация о действующей регистрации.
История домена
Как же заглянуть дальше в прошлое? Для этого понадобится история изменения параметров Whois для конкретного адреса. Будет полезен представленный ниже сервис. Чтобы посмотреть всю историю домена сайта, можно сделать в следующем порядке:
- Открываем https://www.nic.ru/whois/.
- Выполняем запрос по доменному имени.
- Под появившейся информацией выбираем соответствующий пункт.
- Смотрим список результатов.
Кстати, благодаря таким возможностям я обнаружил, что прошлое моего url (workip.ru) начинается аж с 2010 года.
История изменения параметров сайта
Еще один важный нюанс — знаете, как проверить изменение ТИЦ? Данная возможность доступна здесь http://www.recipdonor.com/. Нужно будет зарегистрироваться, проверка платная, однако я считаю, что расценки не высокие
После регистрации и изучения проекта следует обратить внимание на инструмент «история параметров»
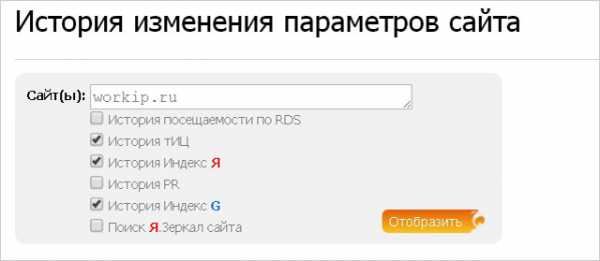
Как можете наблюдать, можно получить данные только по интересующим пунктам.
В заключении отмечу, что для анализа исторических данных могут применяться и другие сервисы. Выбор остается за пользователем.
Теперь вы владеете эффективной информацией о том, как посмотреть любой из сайтов в прошлом времени, узнать дату его создания и изменение параметров. Как вы могли убедиться, узнать исторические сведения не сложно. В идеале, репутацию домена желательно проверять еще на этапе его выбора.
Не прощаюсь. Новые материалы появятся уже скоро. Подписывайтесь на обновления блога Workip. До связи.
Как выглядел сайт раньше
Говорят, прогресс не остановить. Проходят месяцы и годы, технологии становятся всё лучше и совершеннее, уже никого не удивишь с мобильным телефоном со спутниковой навигацией. А сеть Интернет позволяет нам общаться в реальном времени находясь на противоположных концах планеты. Время летит так быстро, что подчас мы не замечаем существенных изменений во многих вещах, с которыми имеем дело. Касается это и сети Интернет, в которой развитие сетевых протоколов, стандартов и технологий просто преобразило внешний вид и функционал имеющихся сайтов. В этом материале я предлагаю вам поднять покров времени и заглянуть в прошлое, посмотреть, как выглядел сайт раньше, каков был внешний вид и функционал ресурсов тех лет, и, возможно, это поможет понять, как далеко мы шагнули вперёд в развитии цифровых технологий наших дней.

Просмотр истории сайтов
История архива Интернета
Итак, как же выглядел сайт в прошлом, и какие инструменты могут нам помочь заглянуть в веб-историю 5-10 летней давности? Более 20 лет назад, в 1996 году энтузиаст Кейл Брюстер основал цифровой архив под названием «Архив Интернета» («The Internet Archive»), слоганом которого был провозглашён «Всеобщий доступ к знаниям». С того времени указанный архив собирает и хранит копии веб-страниц, графики, аудио и видео, различных программ, обеспечивая свободный доступ к накопленной информации для всех желающих.
На состояние октября 2016 года архив уже имел 15 петабайт информации, а веб-архив проекта содержал уже более 150 миллиардов веб-страниц различных сайтов.

Примерно так выглядят серверы архива
Именно благодаря данному архиву сегодня мы имеем возможность посмотреть, как выглядели многие ресурсы 10-15-20 лет тому назад. Историю действий на вашем компьютере можно узнать в статье написанной мной ранее.
Смотрим каким был сайт ранее
Итак, как же посмотреть сохранённые копии сайтов? Воспользуемся возможностями данного проекта и попробуем приоткрыть покровы времени.
Перейдите на данный сервис (он носит название Wayback Machine), введите в поисковой строке адрес интересующего вас сайта (например, www.youtube.com) и нажмите на кнопку «Browse history» (просмотреть историю) справа.
Сервис архив сайтов Wayback Machine
Система обработает запрос и выдаст вам результат. Сверху будет располагаться разбивка по годам, и вы увидите, в каком году впервые была отслежена активность данного сайта и сделан его снимок.
История сайта за 2005 год
Выбираем дату сохранённого скриншота сарвисом
Кликните, к примеру, на самый ранний год (в случае Ютуб это 2005 год), внизу отобразится полный календарь данного года по месяцам. Дни, когда были сделаны «снимки» сайта будут подсвечены голубоватым цветом, в нашем случае первый «снимок» был сделан 28 апреля данного года.
Кликаем на 28 апреля и просматриваем, как выглядел сервис Youtube 28 апреля 2005 года.
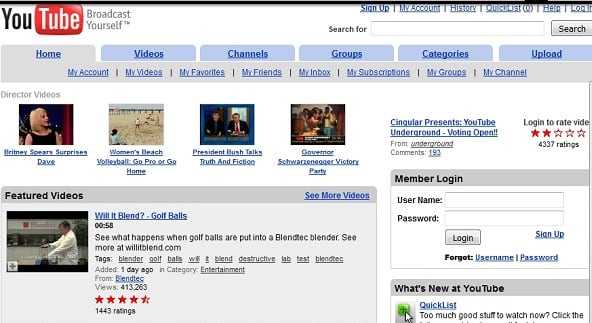
Так выглядел сайт Ютуба ранее
Соответствующим образом вы можете просмотреть любой из интересующих вас сайтов.
Также можно работать с данным сервисом напрямую, введя в адресной строке вашего браузера:
http://web.archive.org/web/*/http://url нужного сайта
Например:
http://web.archive.org/web/*/http://google.com
Соответственно, введя данную строку в адресной строке браузера и нажав на ввод, вы сразу попадёте в отображение снимков нужного вам сайта по годам, месяцам и днём.
Смотрим как выглядели сайты ранее
С помощью ресурса archive.org каждый желающий может получить доступ к миллиардам страниц сохранённого веб-контента, буквально по дням, месяцам и годам наблюдая, как менялся внешний облик множества популярных ресурсов. Воочию видя, как развивалась визуальная составляющая сети, мы можем отчётливо понять, какой скачок сделали интернет технологии за эти годы, и в какое великое время расцвета технического прогресса нам выпала удача жить.
Сайт студента-программиста
Домашние страницы «Я Миша, я живу в Нью-Йорке, у меня есть кот» — основа русскоязычного интернета тех лет. Такие сайты создали эмигранты, которые искали общения с бывшими соотечественниками. До 1997 года личных страниц именно жителей России было еще мало.
Например, 22-летний Юрий Блажевич из МФТИ выкладывал на сайте свое резюме и написанные им программы для создания 3D-графики. Там же он рассказывал о своих интересах и собирал ссылки на полезные интернет-сайты.
Через несколько лет парень смог сделать хорошую карьеру и стал ведущим программистом в популярной игре «Блицкриг 2». Но, к сожалению, ушел из жизни в 2007 году.
Сохраненная страница: 7 октября 1997 года.
Механический метод удаления
Есть два основных типа особых приложений, предуготовленных для удаления программ. К первому типу относятся типовые деинсталляторы Windows, ко второму – деинсталляторы, которые установил сам пользователь. Дабы воспользоваться первым типом приложений, войдите в меню «Пуск», «Все программы», «Internet Explorer» и нажмите удалить либо в некоторых случаях деинсталлировать. Появится окно, жмите «Дальше» вплотную до происхождения прогресс-бара, тот, что свидетельствует о начале процедуры удаления. Примерно такой же алгорифм дозволено применять, если удалять браузер через «Панель управления». Войдите в панель, щелкните по иконке «Программы и компоненты». Откроется окно с перечнем программ, установленных на компьютере. Из них выберите «Internet Explorer», жмите удалить. Как и в предыдущем случае в правом нижнем углу клик мышкой по «Дальше» и обозреватель удалится. Перед тем как воспользоваться вторым типом деинсталляторов, установите один из них на ПК. Позже установки, перезагрузите девайс и откройте приложение. Оно выдаст все программы, которые устанавливались пользователем. Из них предпочтете, соответственно, «Internet Explorer» и щелкните «Деинсталлировать». Плюсом такой программы является то, что она не примитивно стирает приложение с компьютера, но и подчищает так называемые «хвосты» в реестре. От удаленного приложения не останется ни следа, как словно его и не устанавливали. Это, разумеется, правильно влияет на систему. Поменьше вероятности происхождения ошибок. Основной недочет – в основном все эти программы требую вступления лицензионного ключа и многие на английском языке. Если с языком хоть как то дозволено будет разобраться, то поиск бесплатного ключа в интернете – задачка трудоемкая, а его неимение вполовину уменьшает рабочий потенциал программы, либо просто делает ее неработоспособной.
Как использовать веб-архив?
Форма для поиска информации на Peeep.us
Как уже отмечалось выше, веб-архив — это сайт, который предоставляет определенного рода услуги по поиску в истории. Чтобы использовать проект, необходимо:
- Зайти на специализированный ресурс (к примеру, web.archive.org).
- В специальное поле внести информацию к поиску. Это может быть доменное имя или ключевое слово.
- Получить соответствующие результаты. Это будет один или несколько сайтов, к каждому из которых имеется фиксированная дата обхода.
- Нажатием по дате перейти на соответствующий ресурс и использовать информацию в личных целях.
О специализированных сайтах для поиска исторического фиксирования проектов поговорим далее, поэтому оставайтесь с нами.
Сайт «Аэрофлота»
Не все первые российские сайты были «домашними поделками». Крупнейшая авиакомпания страны заказывала сайт у дизайн-студии при компании Seanet и он выглядел довольно привлекательно и гармонично, но не очень читаемо. Также присутствовала традиционная надпись «under construction», а расписание рейсов выложить пока не успели.
Точная дата создания ресурса неизвестна, но по счетчику посещений видно, что к концу октября 1996 года сайт главного авиаперевозчика страны посетили всего 12 тысяч человек. Ведь интернет тогда был редким и дорогим развлечением.
Сохраненная страница: 25 октября 1996 года.
Поисковые системы
Поисковики автоматически помещают копии найденных веб‑страниц в специальный облачный резервуар — кеш. Система часто обновляет данные: каждая новая копия перезаписывает предыдущую. Поэтому в кеше отображаются хоть и не актуальные, но, как правило, довольно свежие версии страниц.
Кеш Google
Чтобы открыть копию страницы в кеше Google, сначала найдите ссылку на эту страницу в поисковике с помощью ключевых слов. Затем кликните на стрелку рядом с результатом поиска и выберите «Сохранённая копия».
Есть и альтернативный способ. Введите в браузерную строку следующий URL: https://webcache.googleusercontent.com/search?q=cache:lifehacker.ru. Замените lifehacker.ru на адрес нужной страницы и нажмите Enter.
Сайт Google →
Кеш «Яндекса»
Введите в поисковую строку адрес страницы или соответствующие ей ключевые слова. После этого кликните по стрелке рядом с результатом поиска и выберите «Сохранённая копия».
Сайт «Яндекса» →
Кеш Bing
В поисковике Microsoft тоже можно просматривать резервные копии. Наберите в строке поиска адрес нужной страницы или соответствующие ей ключевые слова. Нажмите на стрелку рядом с результатом поиска и выберите «Кешировано».
Сайт Bing →
Кеш Yahoo
Если вышеупомянутые поисковики вам не помогут, проверьте кеш Yahoo. Хоть эта система не очень известна в Рунете, она тоже сохраняет копии русскоязычных страниц. Процесс почти такой же, как в других поисковиках. Введите в строке Yahoo адрес страницы или ключевые слова. Затем кликните по стрелке рядом с найденным ресурсом и выберите Cached.
Сайт Yahoo →
Архивы веб-страниц, постоянные
Если вы хотите сохранять текстовый контент, то для этих целей рекомендуются Pocket и Instapaper. Вы можете сохранять страницы через электронную почту, расширения для браузеров или через приложения. Эти сервисы извлекают текстовый контент из веб-страниц и делают его доступным на всех ваших устройствах. Но вы не можете загрузить сохраненные статьи, а только прочитать их на сайте Pocket или через мобильное приложение сервиса. Дальше мы расскажем, как полностью скопировать страницу сайта.
Evernote и OneNote — это инструменты для архивирования контента в подборки. Они предоставляют в распоряжение пользователей веб-клипперы (или расширения), которые позволяют легко сохранять полные веб-страницы в один клик.
Захваченные веб-страницы могут быть доступны с любого устройства, сохраняется оригинальный дизайн и возможность поиска по странице. Эти сервисы могут даже выполнять оптическое распознавание, чтобы найти текст на фотографиях. Evernote также позволяет экспортировать сохраненные страницы как HTML-файлы, которые можно загрузить в другом месте.
Если нужен быстрый и простой доступ к веб-страницам, то сохраняйте их в виде PDF-файлов. Перед тем, как скопировать страницу сайта в виде картинки, выберите правильный инструмент.
Google Chrome имеет встроенный PDF-конвертер. Также можно использовать Google Cloud Print. На сервис добавлен новый виртуальный принтер «Сохранить в Google Drive«. В следующий раз, когда вы будете печатать страницу на компьютере или мобильном устройстве через Cloud Print, вы сможете сохранить ее PDF-копию в Google Drive. Но это не лучший вариант сохранения страниц со сложным форматированием.
Когда важно сохранить дизайн, то лучше всего использовать скриншотер. Выбор подобных программ довольно велик, но я бы рекомендовал официальное дополнение Chrome от
Оно не только захватывает полные скриншоты веб-страниц, но также загружает полученное изображение на Google Drive. Дополнение может сохранять веб-страницы в формате веб-архива (MHT), который поддерживается в IE и Firefox.
Wayback Machine на Internet Archive — это идеальное место для поиска предыдущих версий веб-страницы. Но этот же инструмент можно использовать, чтобы скопировать страницу сайта и сохранить ее. Перейдите на archive.org/web и введите URL-адрес любой веб-страницы. Архиватор скачает на сервер ее полную копию, включая все изображения. Сервис создаст постоянный архив страницы, который выглядит так же, как оригинал. Он останется на сервере, даже если исходная страница была переведена в автономный режим.
Internet Archive не предоставляет возможности загрузки сохраненных страниц, но для этого можно использовать Archive.Is. Этот сервис очень похож на archive.org в том, что вы вводите URL-адрес страницы, и он создает на своем сервере точный ее снимок. Страница будет сохранена навсегда, но здесь есть возможность загрузить сохраненную страницу в виде ZIP-архива. Сервис также позволяет создавать архивы по дате. Благодаря чему вы можете получить несколько снимков одной и той же страницы для разных дат.
Все популярные браузеры предоставляют возможность загрузить полную версию веб-страницы на компьютер. Они загружают на ПК HTML страницы, а также связанные с ней изображения, CSS и JavaScript. Поэтому вы сможете прочитать ее позже в автономном режиме.
Теперь разберемся, как полностью скопировать страницу сайта на электронную читалку. Владельцы eReader могут использовать dotEPUB, чтобы загрузить любую веб-страницу в формате EPUB или MOBI. Данные форматы совместимы с большинством моделей электронных книг. Amazon также предлагает дополнение, с помощью которого можно сохранить любую веб-страницу на своем Kindle-устройстве, но этот инструмент в основном предназначен для архивирования текстового контента.
Большинство перечисленных инструментов позволяют загружать одну страницу, но если вы хотите сохранить набор URL-адресов, решением может стать Wget. Также существует Google Script для автоматической загрузки веб-страниц в Google Drive, но таким образом можно сохранить только HTML-контент.
Сохранить как HTML-файл
Вот как сохранить страницу ресурса глобальной сети на компьютер в формате html. Впоследствии его можно будет конвертировать в другой тип. При таком копировании картинки с веб-портала помещаются в отдельную папку, которая будет иметь то же название, что html-файл, и находится в том же месте, что и он.
- Откройте сайт.
- Кликните правой кнопкой мышки в любом месте, свободном от рисунков, фонов, видео и анимации.
- Выберите «Сохранить как». В Mozilla Firefox аналогичную кнопку можно найти в меню. Для этого нужно нажать на значок с тремя горизонтальными чёрточками. В Opera эти настройки вызываются кликом на логотип.
- Задайте имя. Укажите путь.
- Подтвердите действие.
Как найти уникальный контент для своего сайта
Часто возникают ситуации, когда проекты по различным причинам закрывают, удаляя сайт с хостинга. При этом на таком ресурсе могут сохраняться полезные и интересные статьи. Через некоторое время они перестают индексироваться поисковыми системами и текст статей становится уникальным. Для владельцев информационных сайтов подобные статьи на нужную тематику представляют интерес.
Такой контент можно добавлять на собственный проект без угрозы каких-либо санкций со стороны поисковых систем, поскольку для них основное значение имеет уникальность контента на текущий момент, а не его первоисточник. Чтобы найти подходящие статьи, сэкономив время и деньги необходимые на создание собственного контента, нужно предварительно узнать список доменов, которые освободились в последнее время.
Зайдем в раздел продающихся доменов на сервисе Reg.ru, выберем категорию, совпадающую с тематикой собственного проекта, например, здоровье:
Далее выбираем подкатегорию или просматриваем все предложенные домены, выбирая из них варианты для дальнейшего анализа в веб-архиве:
После того как подходящие статьи найдены в веб-архиве необходимо проверить их на уникальность с помощью сервисов антиплагиата, например, text.ru. Если контент уникален, опубликуйте его на собственном сайте.
Кэш браузера
Если ни один из представленных ваше способов не помог вам найти нужную страницу, остается надеяться только на то, что копия уже сохранена на вашем компьютере. Большинство современных браузеров сохраняет информацию посещенных сайтов. Это необходимо для ускорения загрузки. Попробуйте открыть необходимую страницу в автономном режиме.
В браузере Mozilla Firefox это делается следующим образом:
- зайдите в меню, нажав кнопку в виде трех горизонтальных полос;
- выберите пункт «Веб-разработка»;
в этом подменю нажмите «Работать автономно».
Когда вы перешли в автономный режим, браузер не сможет загружать никакую информацию из интернета. Он будет использовать только те данные, которые сохранил на компьютере. Введите в адресную строку адрес нужной вам страницы и нажмите «Enter». Если на компьютере есть сохраненная версия аккаунта, то браузер загрузит его. В противном случае он скажет, что страница не найдена и напомнит вам, что он работает в автономном режиме.
Как видите, даже из самых, казалось бы, безвыходных ситуаций можно найти выход. Если же ни один из способов вам не помог, то позвоните другу и попросите восстановить страницу. А также отправьте ему ссылку на сайт vkbaron.ru, чтобы он видел, сколько всего интересного можно делать в социальной сети Вконтакте. В случае если вы пытаетесь сохранить информацию со своей страницы, которую кому-то удалось взломать, обязательно ознакомьтесь со статьей о составлении пароля, который не сможет подобрать ни один хакер.
IT-специалист и продвинутый пользователь ВК. Зарегистрировался в соцсети в 2007 году.
Разбираем на примере как правильно подойти к оценке первичной информации
Возьмем всем известный ресурс — cian.ru. Вводим домен в текстовое поле на нашей странице и получаем информацию представленную ниже на скриншоте. Выбираем 2010 год.
Количество HTML страниц = 630. Что это означает? Это значит, что за 2010 год веб-архив увидел 630 уникальные страницы. При этом, если главная страница менялась например 30 раз, то для нас будет уже 600 уникальных страниц. Тоесть по сути это может быть и 200 страниц, но они обновляемые и поэтому считаются как уникальные.
* При восстановлении сайта у нас, мы берем самую последнюю версию страницы, т.к. невозможно сохранить например 2 главные страницы и на них ссылаться. Поэтому сайт будет наиболее полным и ничего не потеряется. Все зависит от того сколько к себе сохранил на сервер веб-архив.
Бывают ситуации, когда в начале года был старый сайт, а в середине года изменился на новый: поменяли дизайн, структуру ссылок и т.д. В данном случае все страницы посчитаются как уникальные, и при восстановлении нужно указывать последнюю версию с тем дизайном, который вам нужен.
Так как реально оценить сколько уникальных (для пользователя) страниц не предоставляется возможным, то мы предоставляем то суммарное количество файлов больше которого точно сайт не будет. Да, это не совсем корректная оценка, но хотя бы приблизительно можно понять размеры ресурса.
492 039 HTML страниц — это сумма страниц за все годы.
Надеемся, что все вышеописанное не будет сложным для понимания и снимет множество вопросов. Если есть вопросы относящиеся к данной теме, но не описанные в статье — пишите нам на почту, с радостью ответим.
Создание задачи
Вводим название задачи и переходим на следующий шаг к настройкам сбора. Тут есть чекбокс “Выбрать период”, чтобы скачать документы по установленной дате. Если чекбокс не будет активирован — система скачает документ по последней доступной дате.
Рекомендуем не включать этот чекбокс, если вы точно не знаете за какую дату вам нужна копия. Если домен, например, старый и вы точно знаете, за какую дату нужна копия, тогда просто выбираете в календаре:
Чекбоксы “Сделать пути относительными” и “Удалить счетчики статистики” рекомендуется всегда оставлять включенными — они помогут избежать различных проблем при переносе копии сайта на ваш сервер.
Далее, переходим на третий шаг и вводим адрес домена (без http и www), который нужно восстановить и после этого жмем “Добавить домен”:
Важно: на данный момент поддерживаются только задачи по 1 домену, поэтому если вам надо восстановить несколько сайтов, придется создать несколько задач. Далее нажимаем “Создать новую задачу” и подтверждаем запуск
Далее нажимаем “Создать новую задачу” и подтверждаем запуск.
Что если сохраненной страницы нет?
Иногда в выдаче при нажатии на зеленую стрелку отсутствует пункт «Сохраненная копия». Этому может быть несколько причин:
- Иногда некоторые браузеры, в которых установлены плагины для блокировки рекламы, могут не отображать эту ссылку. Стоит попробовать приостановить плагин или удалить его и просмотреть сайт снова;
- Яндекс вообще не гарантирует попадание страницы сайта в сохраненные копии. То есть если ресурса нет, значит по какой-то причине поисковик решил не делать резервной копии. Ничего страшного, стоит проверить, не сохранила ли страницы сайта другая поисковая система — например, Google;
- Сайт отказал поисковым роботам в индексации своих страниц. Файл robots.txt, который может лежать в корне сайта, содержит инструкции для поисковых роботов, каким образом они должны сканировать его. Например, он может содержать требование не сканировать сайт совсем или сканировать только отдельные его страницы;
- Схожая с предыдущим пунктом причина. В html коде веб-ресурса может быть указан мета-тег Robots с атрибутом noarchive. Эта директива запрещает поисковому роботу делать копию сохраненной страницы.
Для чего может понадобиться сохраненная копия сайта?
Одна из самых очевидных возможностей этого функционала — просмотр, попала ли определенная страница в индексацию Яндекса. Правда, сделать это можно, если страница не менялась: как копия страницы не обязательно будет заменена на новую, хотя новая при этом уже проиндексирована. Также копия страницы может понадобиться:
- При отсутствии доступа к сайту. Это может произойти по разным причинам: ошибка сервера, просрочка оплаты хостинга, запрет посещения сайта провайдером. Сохраненная копия поможет зайти на страницу, хотя и не самую актуальную, но тем не менее, помогающую понять, что это за веб-ресурс;
- Как бесплатный бэкап. Во время существования ресурса в интернете с ним может произойти разное: хакерская атака, включение в реестр запрещенных сайтов, отказ хостинга и многое другое. Если основное наполнение сайта представлено в качестве текстовой информации, то с помощью копии страницы можно попытаться восстановить утерянные данные. То есть это некий бесплатный бэкап;
- Как инструмент мониторинга продвижения. Если страница попала в сохраненную копию, то она в любом случае прошла индексацию поисковиком. Однако, если ее нет, то нет и гарантий, что она не прошла индексирование.
Как узнать историю сайта? Пошаговая инструкция
Есть ли история у интернет-сайтов? Есть сервисы и инструменты, которые позволяют узнать историю для большинства сайтов.
Как же нам узнать и посмотреть своими глазами историю интересного нам сайта? Ответ вы узнаете из этой статьи.
Интернет – это динамическая среда, в которой все меняется очень быстро. Так, у доменных имен могут меняться их владельцы, обновляться или даже полностью меняться контент сайта, его дизайн, разметка, функциональность. Стоит пустить сайт на самотек – и он уже через пару лет сильно устареет.
Благодаря одному интересному инструменту мы можем узнать историю, отправившись в прошлое, будто бы на машине времени.
Вебархив – www.archive.org
Это интернет-сайт, который индексирует сайты, делает снимки их состояния в разное время и кладет их на свои полки архива, то есть на жесткие диски.
Интересно узнать историю Google.com? Это сделать очень просто – заполняем и смотрим:
История поисковика Google уходит своими корнями в далекий по меркам интернета 1998 год. Посмотрим как он выглядел тогда:
Вот такой вид имела поисковая система Google в то время. Посмотрим еще на любимый Яндекс примерно в то же время:
Любой популярный сайт, как правило, архивируется подобным образом, так что любой желающий может пострадать ностальгией и вспомнить, как давным-давно выглядели его любимые сайты.
Разумеется, сохранить всю историю всех сайтов невозможно, но тем не менее, в базе данных веб архива насчитывается более 450 000 000 сайтов. Архив может быть полезен в самых разных случаях и, кроме того, он абсолютно бесплатен!
Если нужно узнать хронологию сайта, то сервис незаменим, так как можно:
1. Определить тематику усиленного имени и сайта
С помощью веб архива мы сможем увидеть контент, который был на сайте этого домена, а значит – распознать тематику ресурса.
2. Узнать историю сайта
Частно начинающие вебмастеры забрасывают свои сайты, недооценивая их потенциал. А опытные веб-мастеры просто охотятся на такие домены с хорошей историей, чтобы создать на них сайты. Одним из инструментов, который они используют для анализа истории и содержания старого сайта является веб архив.
Поэтому не стоит пренебрегать возможностями, которые нам предоставляет веб архив. Ведь применяя этот инструмент, можно извлечь достаточно много полезной информации о сайте, в том числе просмотреть контент старого сайта.
Как узнать историю сайта? Пошаговая инструкция
Есть ли история у интернет-сайтов? Есть сервисы и инструменты, которые позволяют узнать историю для большинства сайтов.
Как же нам узнать и посмотреть своими глазами историю интересного нам сайта? Ответ вы узнаете из этой статьи.
Интернет – это динамическая среда, в которой все меняется очень быстро. Так, у доменных имен могут меняться их владельцы, обновляться или даже полностью меняться контент сайта, его дизайн, разметка, функциональность. Стоит пустить сайт на самотек – и он уже через пару лет сильно устареет.
Благодаря одному интересному инструменту мы можем узнать историю, отправившись в прошлое, будто бы на машине времени.
Вебархив – www.archive.org
Это интернет-сайт, который индексирует сайты, делает снимки их состояния в разное время и кладет их на свои полки архива, то есть на жесткие диски.
Интересно узнать историю Google.com? Это сделать очень просто – заполняем и смотрим:
История поисковика Google уходит своими корнями в далекий по меркам интернета 1998 год. Посмотрим как он выглядел тогда:
Вот такой вид имела поисковая система Google в то время. Посмотрим еще на любимый Яндекс примерно в то же время:
Любой популярный сайт, как правило, архивируется подобным образом, так что любой желающий может пострадать ностальгией и вспомнить, как давным-давно выглядели его любимые сайты.
Разумеется, сохранить всю историю всех сайтов невозможно, но тем не менее, в базе данных веб архива насчитывается более 450 000 000 сайтов. Архив может быть полезен в самых разных случаях и, кроме того, он абсолютно бесплатен!
Если нужно узнать хронологию сайта, то сервис незаменим, так как можно:
1. Определить тематику усиленного имени и сайта
С помощью веб архива мы сможем увидеть контент, который был на сайте этого домена, а значит – распознать тематику ресурса.
2. Узнать историю сайта
Частно начинающие вебмастеры забрасывают свои сайты, недооценивая их потенциал. А опытные веб-мастеры просто охотятся на такие домены с хорошей историей, чтобы создать на них сайты. Одним из инструментов, который они используют для анализа истории и содержания старого сайта является веб архив.
Поэтому не стоит пренебрегать возможностями, которые нам предоставляет веб архив. Ведь применяя этот инструмент, можно извлечь достаточно много полезной информации о сайте, в том числе просмотреть контент старого сайта.