Непонятные символы вместо текста в браузере
Содержание:
- Установка кодировки в интерфейсе Блокнота
- Противопоказания к медикаментозному кодированию
- ASCII
- Приход новой власти
- Закодированные тексты на ваших сайтах
- Трактовка понятий
- Навигатор по конфигурации базы 1С 8.3 Промо
- Создание договоров по шаблонам Word в УТ 11.2, БП 3.0 с возможностью хранения в справочнике «Файлы»
- Способ 2: FoxTools
- Почему возникает страх перед кодированием
- Инструкция по изменению кодировки в стандартном блокноте
- Набор инструментов для девелоперов
- Определение кодировки
- Гипнотическое
- Важная информация о кодировании от алкоголизма
- Разрешение проблем
- 6.1.3. Использование кодировок в олимпиадах¶
- Медикаментозное
- Особенности с которыми я столкнулся
- Что делать, если имеются противопоказания в кодировке?
- Сравнение стандартов UTF-8 и UTF-16 с точки зрения объема машинной памяти, используемой кодом для представления символов
- KOI8
- Выбор кодировки при сохранении файла
- Поднимет ли уникальность замена букв на символы иностранного алфавита
- Заключение
Установка кодировки в интерфейсе Блокнота
Тем юзерам, кому необходимо пользоваться стандартным приложением «Блокнот» , будет полезно знать о том, что изменить кодировку можно следующим образом:
-
Открыть текстовый документ и повторно сохранить его, нажав «Файл» и затем «Сохранить как».
-
В появившемся окне помимо директории следует выбрать и кодировку, найдя необходимый формат, нажать «Сохранить».
После этого без труда можно открывать необходимый текст в нужной кодировке.
Благодаря правильно подобранной и установленной кодировке пользователь может избежать неприятностей при отправке файла другим юзерам. Все, что для этого требуется, – это выставлять перед началом работы необходимое значение.
Противопоказания к медикаментозному кодированию
Антиалкогольные препараты, которые используют при кодировании алкогольной зависимости, имеют некоторые противопоказания. Для избежания осложнений, их необходимо знать.
Противопоказания к препаратам на основе Дисульфирама
Дисульфирам обладает способностью блокировать метаболизм алкоголя. Препятствует его разложению в печени. Повышает содержание ацетальдегида в кровяном русле. Из-за этого происходит интоксикация организма. Данное фармакологическое действие препарата снижают влечение и вызывают отвращение к алкоголю.
Противопоказания к кодированию Дисульфирамом:
- Попытки суицида, депрессии, в анамнезе инсульт и кровоизлияние в мозг, психопатия.
- Болезни эндокринной системы.
- Бронхиальная астма.
- Неврит слухового нерва.
- Глаукома.
- Кровотечение желудочно-кишечного тракта.
- Грудное вскармливание.
- Гиперчувствительность к Дисульфираму.
- Алкогольное опьянение, употребление алкоголя за последние 12 часов до проведения кодирования.
- Гипертония, ишемическая болезнь сердца, сосудистая недостаточность.
- Эпилепсия.
- Сахарный диабет.
- Почечная и печеночная недостаточность.
- Неврит зрительного нерва.
- Туберкулезная инфекция.
- Злокачественные опухоли.
- Первый триместр беременности.
- Нежелание пациента лечиться.
Лекарственные препараты, в которых содержится Дисульфирам, не назначаются пациенту без его ведома.
ASCII
А начнем мы с возникновения кодировки ASCII, которую в середине двухтысячных и начала вытеснять собой из интернета кодировка UTF-8.
ASCII (англ. American Standard Code for Information Interchange) — американская стандартная кодировочная таблица для печатных символов и некоторых специальных кодов. В американском варианте английского языка произносится , тогда как в Великобритании чаще произносится ; по-русски произносится также или .
— Статья об ASCII на Википедии
Кодировка ASCII была разработана в 1963 году Американской Ассоциацией Стандартов (которая позже стала Американским Национальным Институтом Стандартов — ANSI), впоследствии несколько раз обновлялась — в 1967 и 1986 годах. ASCII — 7-битная кодировка, включающая в себя 128 символов: 33 непечатных управляющих символа (влияющих на обработку текста и пробелов) и 95 печатных символов, включая цифры, буквы латинского алфавита в строчном и прописном вариантах и ряд пунктуационных символов.
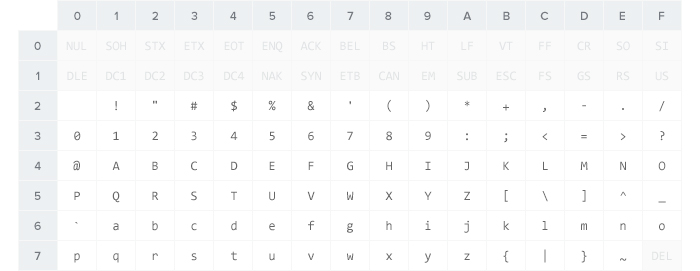 Таблица кодов символов в ASCII.
Таблица кодов символов в ASCII.
Расположение символов внутри кодировки упрощало сортировку, смену регистра букв и перевод десятичных чисел в двоичную форму и обратно — словом, постарались авторы на славу. Однако решить абсолютно все задачи эта кодировка не могла. В частности, в ASCII не было букв и символов многих национальных алфавитов.
Приход новой власти
Спасательным кругом оказался новый стандарт кодирования алфавитов – Unicode. Все его кодировки имеют в названии UTF, а после через дефис количество битов для 1-го символа.
Так вот, продвинутые умы того времени скооперировались и создали UTF-32. Конечно это решило проблему нехватки места для тех же объемных иероглифов, однако вызвало другую – размер файлов увеличивался в 4 раза.
После выделяемая память уменьшилась до 16 бит. И наконец дошла до 8.
UTF-8 является стандартом, который не использует фиксированный размер битов для одного символа и в этом ее огромное преимущество: использование переменной длины.
Благодаря этому латиница и другие простые символы кодируются 1-м байтом, как и в ASCII. А вот «тяжелые» знаки могут быть представлены от одного и до шести байт последовательно. Стоит отметить, что помимо алфавитов, в таблицах Юникода можно найти всевозможные закорючки, смайлы, греческие буквы, цветы и другие нестандартные элементы.
Вот мы и разобрали, почему UTF-8 стала лидером.
Закодированные тексты на ваших сайтах
Так как вычислительные системы понимают только переведённый в цифры текст, один и тот же материал в разных кодировках будет выглядеть для них по-разному. Эта особенность используется некоторыми для плагиата. Всё ещё есть роботы, проверяющие уникальность, которые могут не отличить текст с непривычной им кодировкой. Но если его скопировать в блокнот, он станет нечитабельным или обрастет лишними символами.
Браузер воспринимает текст сайта тоже через кодировку. Если она будет неправильно подобрана, вместо текста будут вопросы или непонятные знаки. Кодировка задается в head, в теге. В кавычках может быть любой стандарт, но utf-8 самый распространенный из них. Поэтому для своих русскоязычных проектов используйте её. Тогда ваши сайты будут корректно отображаться в любом браузере.
Чтобы детальнее разобраться с особенностями кодировки для вашего сайта, смотрите видеоуроки. В них наглядно разбираются вероятные проблемы и их решения. На портале у Михаила Русакова есть целый ряд таких уроков. Там можно найти ответы на множество вопросов по верстке сайтов.
А то, что уже умеете, сможете делать качественнее и быстрее, учась у профессионалов. Все уроки вы сможете сохранить в компьютере, просматривая при необходимости снова.
Подписывайтесь на обновления моего блога, чтобы не пропустить самое интересное. Также добавляйтесь в мою группу Вконтакте, где свежие дублируются свежие обновления. Так вы сможете видеть их прямо в своей ленте новостей.
Трактовка понятий
Человеческие мысли выражаются в виде текста, который состоит из слов. Подобное представление информации называется алфавитным, так как основа языка — алфавит. Он считается конечным набором различных знаков любой природы. Их используют для составления сообщений.
Вам известно что для обозначения количества мы пользуемся цифрами, для обозначения звуков на письме буквами. Можно сказать что цифры и буквы это коды. Одна и тажа информация может быть закодирована по разному. Например китайские и японские иероглифы являются символами которыми кодируется буква или слово. Основу любого языка составляет алфавит — конечный набор различных знаков (символов) любой природы, из которых складывается сообщение на данном языке. То есть символизация информации – это описание объектов или явлений с помощью символов того или иного алфавита. Под мощностью алфавита понимают количество символов, составляющий данный алфавит, что в свою очередь определяет количество возможных комбинаций (слов) которые можно составить из символов данного алфавита в соответствии с определенными правилами.
Чтобы зашифровать данные, необходимо знать правила записи кодов (условные обозначения информации). Понятие кодирование связано с преобразованием сообщений в комбинацию символов с учётом кодов. При общении люди используют русский либо другой национальный язык. В процессе разговора код передаётся звуками, а при письменном общении с помощью букв. У водителей или у пилотов обработка информации также осуществляется световыми сигналами, специальнвми символами — знаками.
Количество и графическое отображение символов в алфавитах естественных языков сложилось исторически и характеризуется особенностями языка (произносимыми звуками). Например русский алфавит имеет 33 символа, латинский – 26, китайский несколько тысяч.
К основным способам кодирования информации в информатике относятся: числовой, символьный (текстовый), графический. В первом случае используются числа, во втором — символы того алфавита, что и первоначальный текст, в третьем — картинки, рисунки, значки.
Навигатор по конфигурации базы 1С 8.3 Промо
Универсальная внешняя обработка для просмотра метаданных конфигураций баз 1С 8.3.
Отображает свойства и реквизиты объектов конфигурации, их количество, основные права доступа и т.д.
Отображаемые характеристики объектов: свойства, реквизиты, стандартные рекизиты, реквизиты табличных частей, предопределенные данные, регистраторы для регистров, движения для документов, команды, чужие команды, подписки на события, подсистемы.
Отображает структуру хранения объектов базы данных, для регистров доступен сервис «Управление итогами».
Платформа 8.3, управляемые формы. Версия 1.1.0.81 от 09.04.2021
3 стартмани
Создание договоров по шаблонам Word в УТ 11.2, БП 3.0 с возможностью хранения в справочнике «Файлы»
Публикация предназначена тем, кто ведет договоры в УТ 11 не только в справочнике «Договоры с контрагентами», но также формирует и согласовывает с контрагентами договоры в формате Word (*.doc). А так как программисты люди ленивые и я не являюсь исключением в этом (хорошем) смысле :), была создана эта печатная форма. Но это не простая печатная форма, а инструмент, который позволяет на основании шаблона, хранящегося в информационной базе в справочнике «Файлы», быстро заполнять и сохранять тут же в справочник «Файлы», но в другую папку, уже заполненный на основании шаблона договор в формате Word.
10 стартмани
Способ 2: FoxTools
Если предыдущий метод по каким-либо причинам вам не подошел, рекомендуем воспользоваться онлайн-сервисом FoxTools, интерфейс которого выполнен в более понятном и простом виде, а по функциональности вы получите те же самые инструменты и поддержку большинства кодировок с автоматическим исправлением.
- Оказавшись на главной странице сайта FoxTools, активируйте поле для ввода, куда в дальнейшем и будете вставлять текст в сбившейся кодировке.
Скопируйте его в текстовом документе и вставьте в данное поле на сайте.
В большинстве случаев при исправлении исходная кодировка неизвестна, поэтому основная форма FoxTools сейчас нам не пригодится. Вместо этого разверните выпадающее меню «Выберите читаемый вариант из списка».
В нем найдите подходящий текст в желаемой кодировке и щелкните по нему ЛКМ.
Вы сразу же будете уведомлены, какая исходная кодировка была у неправильного текста.
Дополнительно можете ознакомиться с той кодировкой, которую выбрали при исправлении.
Нажмите «Отправить», чтобы получить правильный вариант текста для дальнейшего копирования.
Опуститесь ниже к блоку «Результат», скопируйте правильное содержимое и переходите к дальнейшему его использованию в своих текстовых документах.
Почему возникает страх перед кодированием
Кодирование – не слишком мягкий, но и не радикальный метод избавления от алкогольной зависимости. У каждого человека есть право на выбор того или иного способа лечения, однако многие из пациентов выбирают именно кодирование. Опасно ли оно, и какие страхи связаны с этой процедурой?
При систематическом употреблении спиртных напитков в сознании человека происходят изменения, которые вызывают различные страхи. Эти страхи могут быть связаны и с кодированием, когда человек сам их придумывает, чтобы избежать этой процедуры. Наиболее часто встречаются следующие мнения относительно кодирования от алкоголизма:
- Вред для печени, головного мозга, мочеполовой системы и других органов;
- Нежелание делиться своей проблемой с врачами и окружающими;
- Вред препаратов для кодирования;
- Страх перед самой процедурой кодирования;
- Страх «сорваться» и получить сильное отравление.
Все эти страхи являются лишь плодом воображения пациентов. Возможно, некоторые побочные эффекты и присутствуют, но негативное влияние спиртного на организм и психику человека гораздо сильнее. Вдобавок все вышеописанное может возникнуть и из-за алкоголизма, особенно это касается развития сопутствующих заболеваний, таких как цирроз печени, панкреатит, язва желудка и т.д. Словом, все «аргументы» придумываются алкоголиками для того, чтобы оправдать свое нежелание лечиться. Помните, что при правильном подходе к кодированию и выполнении последующих предписаний врача, избавление от алкогольной зависимости практически всегда бывает успешным.
Инструкция по изменению кодировки в стандартном блокноте
Его обычно можно найти по следующему пути: «пуск», «все программы», «стандартные». Нашли? Давайте откроем. Если требуется произвести работы с уже существующем документом, то нажимаем «файл», «открыть» и выбираем его.
После написания текста или открытия готового документа в меню «файл» нажимаем «сохранить как».
После этого на экране появляется окно, в котором можно выбрать подходящий вариант из представленного списка.
Выбираем подходящий вариант, место сохранения документа и подтверждаем операцию. Вот и всё. Было просто? На самом деле для выполнения нужных работ могут потребоваться лишь считанные секунды.
Набор инструментов для девелоперов
Для того, чтобы в коде задать определенный тип кодирования текстового контента, можно воспользоваться несколькими способами.
Первый вариант – это указать в документе .htaccess «AddDefaultCharset UTF-8».
1 2 3 4 5 6 7 8 9 10 |
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>Пример с charset</title> </head> <body> <h2>Привычный вид text-а! Все 4 слова и 2 числа отобразились корректно.<h2> </body> </html> |
Поэкспериментируйте и подставьте другие названия кодировок.
Если материал статьи был вам полезен и понравился, то подписывайтесь на обновления блога и делитесь ссылкой на статьи с друзьями. Желаю удачи. Пока-пока!
Прочитано: 240 раз
Определение кодировки
Есть несколько способов определения:
- В Ворде во время открытия документа: если есть отличия от СР1251, редактор предлагает выбирать одну из самых подходящих кодировок. Оценить, насколько они аналогичны, можно по превью текстового образца;
- В утилите KWrite. Сюда загружаете объект с расширением .txt и используете настройки в меню «Кодирование»;
- Открываете объект в обозревателе Mozilla Firefox. При правильном отображении в разделе «Вид» ищите кодировку. Нужный вариант – тот, возле которого установлен флажок. Если все отображается с ошибками, проверяете различные варианты в меню «Дополнительно»;
- Пользователи Unix могут воспользоваться приложением Enca.
С помощью предложенных инструментов вы можете быстро и легко раскодировать текст онлайн. Если у вас мало знаний, воспользуйтесь утилитами с простым меню и функционалом.
Гипнотическое
Чаще всего наркологические центры практикуют кодировку от алкоголизма по методу Довженко, однако некоторые специалисты используют менее распространенные методики (якорную, эриксоновский гипноз и другие) — решать, какое кодирование лучше, придется вам.
Гипнотические методы кодирования от алкоголя используют для внушения пациенту негативных установок на прием спиртного и позитивных — на результативное излечение.
Многие специалисты считают, что для достижения наилучшего результата самые лучшие кодировки от алкоголизма (медикаментозную и психологическую) лучше сочетать. В прайсах медцентров такая техника обычно называется «двойной блок».
Важная информация о кодировании от алкоголизма
Многие люди смутно представляют собой механизм действия кодировки и часто интересуются, опасна ли эта процедура. Стоит отметить, что кодирование – это не полноценное лечение, а лишь срочная кратковременная помощь для решения проблемы пьющего человека. Это достаточно радикальный метод, который используется в экстренных случаях, когда остальные способы лечения не могут дать гарантированный результат.
Правильно подобранный препарат для кодирования и его дозировка благотворно влияет на организм человека. Пациент перестает пить спиртные напитки, благодаря чему в его организме нормализуются обменные процессы, а поврежденные органы и ткани постепенно восстанавливаются. Эмоциональное состояние также претерпевает изменения, так как человек учится находить в жизни новые радости, не связанные с употреблением алкоголя.
Если кодирование проведено успешно и не приводит к негативным последствиям, в конце срока действия препарата пациенту следует задуматься о повторной процедуре. Если этого не сделать, риск возобновления алкоголизма очень велик, причем человек начинает пить намного больше, чем до сеанса кодирования.
Разрешение проблем
Благодарность за предоставленные рецепты и пояснения — участнику сообщества под ником YMP.
Иногда значительные неудобства доставляют тексты, сохранённые в неправильной кодировке.
Например, текст в кодировке КОИ-8, сохранённый в кодировке cp1251, выглядит примерно следующим образом:
оНМЪРХЕ ЯЙПХОРХМЦЮ (МЮОХЯЮМХЪ ЯЙПХОРНБ) ПЮАНРЮЕР ДНБНКЭМН УНПНЬН, ЕЯКХ ОНМХЛЮРЭ ЯЙПХОР ЙЮЙ РЕЮРПЮКЭМШИ ЯЖЕМЮПХИ. уНРЪ ЯЖЕМЮПХИ ЪБКЪЕРЯЪ ХЯВЕПОШБЮЧЫХЛ, ОПНПЮАНРЙЮ ДЕРЮКЕИ ХЯОНКМЕМХЪ НЯРЮБКЕМЮ ДЕИЯРБСЧЫХЛ ЮЙРЕПЮЛ Х ПЕФХЯЯЕПС. й ЯНФЮКЕМХЧ, РЮЙХЛ НАПЮГНЛ МЕКЭГЪ ЯСГХРЭ НОПЕДЕКЕМХЕ ЯЙПХОРНБШУ ЪГШЙНБ: ЛЮМХОСКХПСЪ ОПХКНФЕМХЪЛХ, КЧАНИ ЪГШЙ МХГЬЕЦН СПНБМЪ ЛНФМН ХЯОНКЭГНБЮРЭ ЙЮЙ ЯЙПХОРНБШИ ЪГШЙ!
Чтобы прочитать такой текст, можно проделать следующее:
- Перенесите такой текст через буфер обмена в стандартный редактор Блокнот и сохраните его в текстовом файле.
- Переименуйте расширение файла в .htm и откройте его двойным щелчком в Internet Explorer.
- В Internet Explorer выполните команду меню «Файл» — «Сохранить как» и сохраните в другой файл с расширением .htm. В диалоге «Сохранение веб-страницы» выберите кодировку «Кириллица (KOI8-R)».
- Откройте новый файл двойным щелчком в Internet Explorer и выполните команду меню «Вид» — «Кодировка» — «Кириллица (Windows)».
В некоторых случаях происходят ошибки при копировании текста через буфер обмена из одной программы в другую — вставка может превращать текст в «кракозябры».
Это может происходить из-за того, что приложение, из которого производится копирование, помещает текст в буфер обмена в 8-битной кодировке, а то, в которое происходит вставка, запрашивает его в Юникоде (так делает, например, Блокнот). Windows «идёт навстречу» и перекодирует текст. При копировании в буфер помещается также информация о языке. Это может делать само приложение, а если не делает, то Windows просто смотрит, на какой язык ввода было переключено приложение в момент копирования. Если на русский, то используется страница 1251 и при вставке всё нормально. Но если текст русский, а окно приложения было переключено в английский, кодирование пойдёт через 1252 страницу и вместо русских букв пойдут «кракозябры». В таких случаях может помочь предварительное переключение приложения, из которого производится копирование, на русский.
Обратный случай: русский текст помещён в буфер в Юникоде, когда окно было на английском, а вставляется в 8-битной кодировке. Таблица перекодировки берётся опять не та — 1252. Юникодовских кодов для русских букв там просто нет. Не найдя их, Windows использует подстановочный знак для «неизвестного символа» — отсюда вместо русского текста сплошь вопросительные знаки.
Например, при копировании текста через буфер обмена из некоторых PDF-документов можно получить текст «кракозябрами». При копировании из Adobe Reader текст в буфер помещается как в 8-битной кодировке, так и в Юникоде. Похоже, что Adobe Reader сам его перекодирует до того, как положить в буфер. Локаль буфера он не переключает, она соответствует языку окна. Если приложение, в которое осуществляется вставка, запрашивает текст в 8-битной кодировке, в нём отображается всё нормально, а если в Юникоде — в нём идут «кракозябры». Возможно, в самом PDF-документе содержится информация о том, какую страницу использовать при перекодировке, так как такое происходит, конечно, далеко не во всех PDF-документах. В такой ситуации могут выручить приложения, которые запрашивают текст в 8-битной кодировке, например свободный текстовый редактор AkelPad или PuntoSwitcher с его многокарманным буфером.
Чтобы перенести подобный текст, можно проделать следующее:
- Перенесите такой текст через буфер обмена в стандартный редактор Блокнот и сохраните его в текстовом файле. В диалоге «Сохранить как» выберите кодировку «Юникод».
- Переименуйте расширение файла в .htm и откройте его двойным щелчком в Internet Explorer.
- В Internet Explorer выполните команду меню «Файл» — «Сохранить как» и сохраните в другой файл с расширением .htm. В диалоге «Сохранение веб-страницы» выберите кодировку «Западноевропейская (Windows)».
- Откройте новый файл двойным щелчком в Internet Explorer и выполните команду меню «Вид» — «Кодировка» — «Кириллица (Windows)».
Людоговский Александр
2007 http://www.script-coding.com При любом использовании материалов сайта обязательна ссылка на него как на источник информации, а также сохранение целостности и авторства материалов.
6.1.3. Использование кодировок в олимпиадах¶
В настоящее время в олимпиадах в целом принято мнение, что работа с кодировками — это достаточно техническая вещь,
не относящаяся напрямую к алгоритмам и т.д., и поэтому задачи на олимпиадах не должны быть осложнены
работой с кодировками. (См. два моих поста в блоге алгопрога на смежные темы, хоть и не про кодировки:
раз, два).
Поэтому в современных олимпиадах в принципе считается правильным делать такие задачи, чтобы
во всех входных и выходных файлах все байты были не больше 127 (т.е. каждый байт файла
должен иметь числовое значение не больше 127). С такими файлами все языки — что классические, что юникодные, —
спокойно работают, потому что символы с кодами до 127 одинаковы во всех кодировках.
Поэтому такой файл можно считать в строку на любом языке, и спокойно с ним работать.
Раньше (особенно до широкого распространения юникодных языков) встречались и задачи, в которых могут быть байты больше 127;
ну и сейчас, наверное, на разных странных олимпиадах такое возможно (ну и уж тем более возможно в разных тренировочных контестах,
где используются старые задачи, в том числе на алгопроге есть такие задачи).
Такие задачи делятся на две больших группы.
Первая группа — где вам не надо уметь как-то особо различать отдельные символы с кодами больше 127,
например, вам не надо отличать русские буквы от всех остальных символов
Характерный пример — задача «Цензура»,
в ней надо уметь выделять во входном тексте только пробелы, переводы строки, и девять указанных в условии знаков препинания,
а из остальных символов вам надо только подсчитывать одинаковые; вас совершенно не интересует,
какой из символов, например, является русской буквой, а какой нет.
Поэтому тут совершенно не важно, в какой кодировке входной файл, главное чтобы это была однобайтовая кодировка
На любом классическом языке программирования такие задачи спокойно решаются без каких-либо специальных ухищрений.
Вы считываете входные данные как строку, и дальше с ней работаете.
И выводите ответ, причем тут нужно вывести просто те же байты, что вы прочитали,
а это делается естественно без каких-либо специальных действий, никаких и т.д. не нужно.
На юникодных же языках есть два способа решать такие задачи: можно, конечно, использовать тип данных «массив байт», но в целом
проще работать с файлами, указать при чтении данных какую-нибудь однобайтную кодировку (например, cp866),
тогда язык прекрасно сконвертирует входные строки в свое внутреннее представление, вы совершенно спокойно с ними поработаете,
и при выводе опять вы должны будете указать ту же кодировку.
В обоих случаях (и в классическом, и в юникодном языке) вы можете переживать, что ваш код выводит на экран
не совсем то, что было во входных данных, или например (на классических языках) обнаружить, что вы вводите данные, а длина строки
оказывается в два раза длиннее… — но, как я писал выше, это скорее вопрос к посредникам при вводе-выводе данных.
В тестирующей системе будет работа через файлы (либо напрямую, либо через перенаправление),
и всё будет работать. На классическом языке вы просто считаете именно те байты, что записаны во входном файле,
обработаете их и выведете; на юникодном языке вы считаете эти байты, сконвертируете их во внутреннюю кодировку, обработаете,
и выведете, перекодировав их обратно. В обоих случаях ошибаться именно в работе с кодировками негде, поэтому
на самом деле вы вполне можете сами тестировать задачу чисто на английских буквах (на символах с кодами до 127),
а потом отправить задачу в тестирующую систему, и у вас само всё заработает. Единственное, что от вас требуется — еще раз повторюсь
— на юникодных языках указать явно однобайтную кодировку при вводе и выводе.
(Собственно, примерно потому такие задачи раньше и существовали — раньше все писали
на классических языках, и там никаких проблем с этим не было, последовательность байт и есть последовательность байт,
с ней вы спокойно работаете, и даже не задумываетесь про кодировки.)
Медикаментозное
Многие специалисты на вопрос, какой метод кодирования от алкоголизма самый эффективный, ответят — медикаментозный.
Лекарственная кодировка от алкоголизма применяется давно, эффективность препаратов, используемых для процедуры, подтверждена клиническими испытаниями. Лекарства отличаются способами воздействия на человеческий организм, поэтому, чтобы понять, кодирование каким методом эффективнее, необходимо изучить их особенности.
Например, средства на основе налтрексона, блокируют рецепторы мозга, ответственные за удовольствие от спиртного. Закодированный не получает прежнего эффекта эйфории даже от повышенной дозы. Дисульфирам и его аналоги действуют иначе — даже при малом количестве выпитого вызывают симптомы сильнейшей передозировки алкоголем: тахикардию, аритмию, повышение давления, тошноту, рвоту, тремор и другие негативные проявления. Закодированный человек боится пить из-за последствий.
Особенности с которыми я столкнулся
Чуть коснусь прелестей и проблем связанных с golang. Раздел может быть интересен только начинающим писать на golang.
Проблемы
Лично походил по некоторым подводным камушкам из 50 оттенков Go: ловушки, подводные камни и распространённые ошибки новичков.
Что делать если интерфейс является входным параметром нашей функции? Например если мы принимаем io.Reader, проверить его на nil ведь надо. Проверить на существование переменной типа io.Reader мне удалось только с помощью рефлексии.
Разок наступил на грабли с передачей массивов по значению. Немного тупанул на попытке изменять элементы хранящиеся в map пробегая по ним в range…
Прелести
Сложно сказать что конкретно, постоянное ли битьё по рукам от линтера и компилятора или активное использование range, или всё вместе, но практически отсутствуют залёты по выходу индекса за пределы.
Конечно очень приятно жить со сборщиком мусора. Полагаю мне ещё предстоит освоить грабли автоматизации выделения/освобождения памяти, но пока дебильная улыбка не покидает лица.
Строгая типизация — тоже кусочек счастья.
Переменные имеющие тип функции — соответственно лёгкая реализация различного поведения у однотипных объектов.
Странно мало пришлось сидеть в отладчике, перечитывание кода обычно быстро давало результат.
Щенячий восторг от наличия массы инструментов из коробки, это чудное ощущение когда компилятор, язык, библиотека и IDE Visual Studio Code работают на тебя вместе, слаженно.
Что делать, если имеются противопоказания в кодировке?
Что предпринять алкоголику, если у него выявили ограничения к проведению кодирования? Достойной альтернативой в этом случае и дополнением к общему лечению является социальная реабилитация. Проводится психотерапевтическая коррекция поведения, эмоций и характера. Пройти курс можно:
- Амбулаторно при наркологической клинике.
- В группе анонимных алкоголиков.
- В центрах реабилитации.
Противопоказаний для реабилитационного процесса нет. Главное, заручиться желанием самого больного. В период реабилитационный программы с пациентами общаются доктора. При положительной динамике, они предложат больному закодироваться от алкогольной зависимости.
Если у вас или ваших родственников появилось желание закодироваться, обращайтесь в наркологическую клинику «Медик-Групп» за консультацией. Вы можете записаться на приём к специалисту и выполнить полученные рекомендации.
Является мифом, что кодирование влияет на алкоголика негативно. В действительности, если больной всесторонне обследуются, побочных эффектов не возникает. А кажущиеся изменения психики — это последствия алкоголизма, которые уже произошли до кодировки и становятся очевидны в период трезвости.
Кодирование проводят после очищения организма от токсичных продуктов. Когда этими условиями пренебрегают, тогда можно ожидать негативных последствий.
Сравнение стандартов UTF-8 и UTF-16 с точки зрения объема машинной памяти, используемой кодом для представления символов
Результаты сравнения стандартов представлены в таблице 1.
Таблица 1. Результаты сравнения стандартов.
|
Диапазон номеров |
0-127 |
128 — 2047 |
2048-32767 |
32768-65535 |
65535- 1048575 |
1048575-… |
|
UTF-8 |
8 |
16 |
24 |
32 |
32 |
_ |
|
UTF-16 |
16 |
16 |
16 |
16 |
32 |
32 |
В ячейках таблицы 1 содержится количество бит, требуемое для кодирования одного символа из таблицы Юникод. Видно, что для диапазонов номеров ячеек 128-2047, 65535-1048575 стандарты UTF-8 и UTF-16 используют одинаковое количество бит. Для диапазона 0-127 выгодно использование стандарта UTF-8, например, в случае, если программисту поручили реализовать кодер букв английского алфавита. Для диапазонов 2048-32767 и 32768-65535 выгодно использование стандарта UTF-16, например, в случае, если программисту поручили реализовать кодер иероглифов Бопомофо (занимают в таблице Юникод диапазон ячеек 12549-12589). Кодирование символов таблицы Юникод, расположенных в ячейках, номера которых начинаются от 1048575 возможно только с использованием кодировки UTF-16.
В предыдущих главах приведены примеры кодирования фразы «Папа Hello» стандартами UTF-8 и UTF-16. Кодировкой UTF-8 используются 14 байт, кодировкой UTF-16 20 байт, что связано с избыточностью кодирования англоязычных символов во втором случае из-за использования дополнительного байта 0х00. Можно сделать вывод, что для кодирования текста содержащего набор букв русского и английского алфавитов, предпочтительно использование кодировки UTF-8.
Вывод: в зависимости от языка алфавита может быть выбрана как кодировка UTF-8, так и кодировка UTF-16. Для английского алфавита однозначно более выгодно использование кодировки UTF-8, для русского алфавита буквы представляются одинаковым количеством бит при использовании как одной, так и другой кодировки.
KOI8
Естественно, СССР не остался в стороне, разработав в 1974 году свою кодировку — KOI8 (Код Обмена Информацией, 8 бит). Как следует из названия, это была 8-битная кодировка, что позволяло включить в нее в два раза больше символов. KOI8 включала в себя цифры, буквы латинского и русского алфавита, а также знаки пунктуации, спецсимволы и псевдографику.
Таблица кодов символов в KOI8-R.
Эта кодировка существует в нескольких вариантах для разных кириллических алфавитов, в частности: KOI8-R — для русского алфавита, и KOI8-U — для украинского. Кодировки KOI8 стали одними из самых популярных в русском сегменте интернет до распространения UTF-8.
Выбор кодировки при сохранении файла
Если не выбрать кодировку при сохранении файла, будет использоваться Юникод. Как правило, рекомендуется применять Юникод, так как он поддерживает большинство символов большинства языков.
Если документ планируется открывать в программе, которая не поддерживает Юникод, вы можете выбрать нужную кодировку. Например, в операционной системе на английском языке можно создать документ на китайском (традиционное письмо) с использованием Юникода. Однако если такой документ будет открываться в программе, которая поддерживает китайский язык, но не поддерживает Юникод, файл можно сохранить в кодировке «Китайская традиционная (Big5)». В результате текст будет отображаться правильно при открытии документа в программе, поддерживающей китайский язык (традиционное письмо).
Примечание: Так как Юникод — это наиболее полный стандарт, при сохранении текста в других кодировках некоторые знаки могут не отображаться. Предположим, например, что документ в Юникоде содержит текст на иврите и языке с кириллицей. Если сохранить файл в кодировке «Кириллица (Windows)», текст на иврите не отобразится, а если сохранить его в кодировке «Иврит (Windows)», то не будет отображаться кириллический текст.
Если выбрать стандарт кодировки, который не поддерживает некоторые символы в файле, Word пометит их красным. Вы можете просмотреть текст в выбранной кодировке перед сохранением файла.
При сохранении файла в виде кодированного текста из него удаляется текст, для которого выбран шрифт Symbol, а также коды полей.
Поднимет ли уникальность замена букв на символы иностранного алфавита
Иногда пользователи, пишущие контент, повышают процент антиплагиата следующим способом. Они просто меняют часть символов на похожие латинские знаки. Например, вписывают вместо А, В, О, Р и т. д. одинаковые по написанию буквы английского алфавита.
Такие знаки легко можно увидеть и в Word. Если скопировать в него скачанный контент, то эти символы будут подчеркнуты красным или другим цветом.
Но большинство программ нацелено на проверку только английских букв в русскоязычных текстах. Поэтому если взять похожие знаки других стран с алфавитом, отличным от латинского, то система может не распознать подмены и процент окажется высоким.
Программа может распознать замену некоторых символов латиницей.
Заключение
Всемирные ассоциации наркологов и психотерапевтов утверждают, что не существует единого протокола лечения и универсального алгоритма, который позволял бы гарантированно избавлять от пристрастия к алкогольным напиткам
Кроме того, что степень влияния каждого метода обусловлена индивидуальными особенностями организма человека, также существуют определенные противопоказания, которые важно учитывать при выборе тактики лечения
Если индивидуальную реакцию на гипноз и внушение предугадать сложно, то эффективность соответствующих препаратов исследована и доказана. Каждый может выбрать для себя способ, который поможет достичь необходимого результата – полного отказа от употребления спиртного на длительный срок.
Телефон горячей линии: +7 495 109 03 10