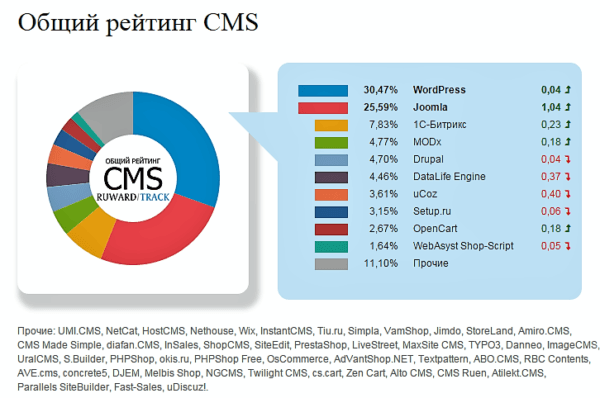
50+ инструментов для подбора ключевых слов. чем пользоваться при составлении семантического ядра сайта??
Содержание:
- Виды парсеров по сферам применения
- Яндекс.Вордстат
- Минусы парсинга
- Возможности Парсера и его преимущества
- Как пользоваться парсером?
- Программы и сервисы для парсинга
- Инструменты для определения частотностей
- Зачем нужен Kparser?
- Различия между Словоеб_ом и Key Collector_ом
- Что такое парсинг?
- Маркерные запросы
- Как проверить частоту запросов и их конкурентность
Виды парсеров по сферам применения
Для организаторов СП (совместных покупок)
Есть специализированные парсеры для организаторов совместных покупок (СП). Их устанавливают на свои сайты производители товаров (например, одежды). И любой желающий может прямо на сайте воспользоваться парсером и выгрузить весь ассортимент.
Чем удобны эти парсеры:
- интуитивно понятный интерфейс;
- возможность выгружать отдельные товары, разделы или весь каталог;
- можно выгружать данные в удобном формате. Например, в Облачном парсере доступно большое количество форматов выгрузки, кроме стандартных XLSX и CSV: адаптированный прайс для Tiu.ru, выгрузка для Яндекс.Маркета и т. д.
Популярные парсеры для СП:
- SPparser.ru,
- Облачный парсер,
- Турбо.Парсер,
- PARSER.PLUS,
- Q-Parser.
Вот три таких инструмента:
- Marketparser,
- Xmldatafeed,
- ALL RIVAL.
Парсеры для быстрого наполнения сайтов
Такие сервисы собирают названия товаров, описания, цены, изображения и другие данные с сайтов-доноров. Затем выгружают их в файл или сразу загружают на ваш сайт. Это существенно ускоряет работу по наполнению сайта и экономят массу времени, которое вы потратили бы на ручное наполнение.
В подобных парсерах можно автоматически добавлять свою наценку (например, если вы парсите данные с сайта поставщика с оптовыми ценами). Также можно настраивать автоматический сбор или обновление данных по расписания.
Примеры таких парсеров:
- Catalogloader,
- Xmldatafeed,
- Диггернаут.
Яндекс.Вордстат
Wordstat — бесплатный инструмент от Яндекса, который подойдет владельцам блогов и небольших сайтов. Функционал довольно ограничен, поэтому для серьезных сайтов он не пойдет.
Сервис позволяет посмотреть статистику по ключевым словам. Мы можем узнать, какие запросы люди вводили в Яндексе за последний месяц. Также Яндекс.Вордстат показывает:
- похожие ключи;
- количество запросов;
- что еще искали с введенной фразой;
- в каких странах этот ключ наиболее часто ищут;
- историю запросов.
Я лично использую этот сервис для поиска тем для статей и главного ключа. Вордстат позволяет узнать, стоит ли продвигаться по выбранной фразе или же люди такое не ищут.
Давайте разберем функционал на примере:
Запрос вбивается в поле, отмеченное на картинке красной стрелкой. Ниже можно выбрать тип поиска: по словам (сколько людей вводило этот запрос за последний месяц), по регионам (показы в месяц в разных регионах) или историю запроса.
Давайте введем запрос и поищем «по словам»:
Вот такой список мы получаем. Слева — синонимичные запросы. Справа — похожие запросы. К каждому ключу прилагается количество показов в месяц. А сверху над списком есть кнопки для установки фильтра по устройствам.
Если на какой-то из приведенных ключевых запросов кликнуть, то сервис покажет статистику уже по этому слову.
Итак, суммируем.
Плюсы Яндекс.Вордстат:
- весьма точная статистика,
- похожие запросы, расширяющие семантику,
- поиск по регионам.
Минус Яндекс.Вордстат: cтатистика только по запросам в Яндексе, для Гугла нужно искать отдельно. У Google, кстати, есть свой сервис, называется он Google Trends.
Минусы парсинга
Главный недостаток парсеров заключается в том, что ими не всегда удается воспользоваться. В частности, когда владельцы чужих сайтов запрещают автоматический сбор информации со страниц. Есть сразу несколько методов блокировки доступа со стороны парсеров: и по IP-адресам, и с помощью настроек для поисковых ботов. Все они достаточно эффективно защищают от парсинга.
В минусы метода можно отнести и то, что конкуренты тоже могут использовать его. Чтобы защитить сайт от парсинга, придется прибегнуть к одной из техник:
- либо заблокировать запросы со стороны, указав соотвествующие параметры в robots.txt;
- либо настроить капчу – обучить парсер разгадыванию картинок слишком затратно, никто не будет этим заниматься.
Но все методы защиты легко обходятся, поэтому, скорее всего, придется с этим явлением мириться.
Возможности Парсера и его преимущества
Парсер Wordstat позволяет быстро собрать частотность для отдельных фраз или целого семантического ядра. Вот, что можно сделать с помощью инструмента:
- собрать частотность по Wordstat для неограниченного количества фраз;
- загрузить списком или файлом фразы для парсинга частотности;
- собрать частотность по любому региону, поддерживаемому Яндексом;
- собрать частотность только по фразам в определенном виде (с фиксированным порядком слов или словоформами), используя типы соответствия (операторы « », ! и ).
Главные преимущества:
- нет лимитов по количеству запросов: за один раз можно спарсить любое количество запросов (хоть 100, хоть 100 тысяч);
- весь парсинг выполняется на стороне сервиса. Вам не нужно опасаться бана личного аккаунта в Яндексе или создавать фейковые аккаунты под парсинг;
- при использовании Парсера не нужно применять прокси и вводить капчу;
- данные по частотности можно просуммировать по всем регионам или вывести отдельно по каждому региону. В этом случае вы фактически получаете отдельный отчет для каждого региона;
- парсинг работает «в облаке» – нет необходимости загружать ПО и устанавливать на компьютер, не нужно держать вкладку или браузер открытыми. Отчеты также сохраняются «в облаке» и доступны в любое время;
- готовый отчет формируется в формате XLSX-файла. С ним удобно работать, можно импортировать в Google Таблицы, если для вас они более привычны, чем Excel.
Как пользоваться парсером?
На начальных этапах парсинг пригодится для анализа конкурентов и подбора информации, необходимой для собственного проекта. В дальнейшей перспективе парсеры используются для актуализации материалов и аудита страниц.
При работе с парсером весь процесс строится вокруг вводимых параметров для поиска и извлечения контента. В зависимости от того, с какой целью планируется парсинг, будут возникать тонкости в определении вводных. Придется подгонять настройки поиска под конкретную задачу.
Иногда я буду упоминать названия облачных или десктопных парсеров, но использовать именно их необязательно. Краткие инструкции в этом параграфе подойдут практически под любой программный парсер.
Это наиболее частый сценарий использования утилит для автоматического сбора данных. В этом направлении обычно решаются сразу две задачи:
- актуализация информации о цене той или иной товарной единицы,
- парсинг каталога товаров с сайтов поставщиков или конкурентов.
В первом случае стоит воспользоваться утилитой Marketparser. Указать в ней код продукта и позволить самой собрать необходимую информацию с предложенных сайтов. Большая часть процесса будет протекать на автомате без вмешательства пользователя. Чтобы увеличить эффективность анализа информации, лучше сократить область поиска цен только страницами товаров (можно сузить поиск до определенной группы товаров).
Парсинг других частей сайта
Принцип поиска других данных практически не отличается от парсинга цен или адресов. Для начала нужно открыть утилиту для сбора информации, ввести туда код нужных элементов и запустить парсинг.
Разница заключается в первичной настройке. При вводе параметров для поиска надо указать программе, что рендеринг осуществляется с использованием JavaScript. Это необходимо, к примеру, для анализа статей или комментариев, которые появляются на экране только при прокрутке страницы. Парсер попытается сымитировать эту деятельность при включении настройки.
Также парсинг используют для сбора данных о структуре сайта. Благодаря элементам breadcrumbs, можно выяснить, как устроены ресурсы конкурентов. Это помогает новичкам при организации информации на собственном проекте.
Программы и сервисы для парсинга
Для начала нужно подобрать около 20 базовых фраз. Для этого используем свой мозг (подумайте, какие словосочетания ассоциируются с вашим родом деятельности), поисковую выдачу по схожим запросам и данные из Яндекс.Метрики и Google Search Console (смотрим, по каким ключам больше переходов на ваш сайт).
Далее для создания хорошего семантического ядра используем специальные программы.
Бесплатные
Часть работы можно проделать, не заплатив ни копейки. Здесь на помощь приходят определенные сервисы.
Wordstat Yandex
- показывает количество и частоту запросов в Яндексе;
- фразы изменяются в падежах;
- можно задать регион;
- позволяет сделать выборку по типу устройства (ПК, планшет, смартфон);
- позволяет исключить лишние фразы.
Планировщик ключевых слов Google
- подходит для узкой тематики;
- позволяет собрать широкую базу ключей;
- показывает статистику по словам;
- прогнозирует эффективность фраз.
Букварикс
- содержит большую базу запросов;
- функции фильтрации минимальны.
При использовании бесплатных ресурсов семантическое ядро получается «грязным» — словосочетания дублируются, выдаются нерелеватные запросы, слова с нулевой частотностью, которые приходится чистить с помощью фильтров или вручную.
Платные
Для расширения ядра советуем воспользоваться платными сервисами.
Rush Analytics
- автоматизирует сбор и группировку значимых словосочетаний;
- парсит запросы через Wordstat;
- регулируемая глубина поиска;
- классифицирует запросы по типам (коммерческие и информационные).
База Пастухова
- большая база ключевых слов (на русском и английском языке);
- фильтрует запросы по числовым данным;
- есть онлайн-версия;
- из-за дороговизны больше подходит крупным компаниям.
Serpstat
- комплексный сервис для продвижения ресурса;
- выделяет запросы, по которым проект попадает в ТОП-100 выдачи;
- возможность анализировать сайты конкурентов.
Для наибольшей эффективности советуем комбинировать бесплатные и платные сервисы.
Инструменты для определения частотностей
А теперь к самому интересному – как же определить частотность?
Для этого можно использовать различные сервисы.
В Яндекс WordStat необходимо ввести запрос, выбрать регион, интересующее устройство, нажать «Подобрать», далее сервис покажет результат:
Можно посмотреть статистику по регионам и городам:
Яндекс.Директ – сервис для запуска рекламы в поисковой системе Яндекс. Посмотреть частотность запроса можно при создании рекламной кампании. Доходим до второго шага «Выбор аудитории», задаем регион и нажимаем «Подобрать фразы». При вводе фразы получаем статистику по ним.
Частота запросов в Яндекс.Директ может несколько отличаться от показателей Яндекс.Вордстат. Это происходит, потому что последний не учитывает вложенные запросы с прогнозом меньше пяти. Кроме того, данные берутся за последние 30 дней, но в Директе они обновляются чаще из-за чего могут быть расхождения в пару дней. И наконец, необходимо отслеживать нет ли минус-слов в Яндекс.Директе, которые могут повлиять на статистику.
В случае снятия данных за год, они могут отличаться от данных в сервисе WordStat и быть некорректными.
Google Keyword Planner – инструмент для подбора ключевых слов при создании рекламы в ПС Google. Поможет при сборе статистики по запросам в Google.
Необходимо зайти в инструмент, авторизоваться и выбрать «Найдите новые ключевые слова»:
Далее нужно ввести слова через запятую и нажать «Показать результаты»:
Далее необходимо отметить добавленные слова галочкой (расширить список можно будет дальше), выбрать соответствие (точное, широкое, фразовое) и нажать «Добавить ключевые слова»:
Рядом с каждым запросом появляется зеленый значок «В плане»:
Переходим в пункт меню «Ключевые слова», выбираем корректный регион вверху страницы, раскрываем график по стрелочке, выставляем максимальную цену за клик:
Для анализа нужно использовать столбец «Показы»:
Этот способ покажет точную статистику по Google, насколько это возможно в рамках данной поисковой системы.
SemRush – сервис, который может показать подробную информацию по ключевому слову, в том числе уровень конкурентности, вариации ключевого слова, поисковую выдачу и другие параметры. Часть инструментов в нем платная.
Ahrefs – еще один сервис для просмотра статистики по ключевому слову и подбора аналогов. Также является платным.
Серверы SemRush, Ahrefs и другие подобные инструменты получают данные о количестве запросов методом покупки сlickstream у крупных провайдеров, поэтому их данные будут отличаться от данных в Google Keyword Planner.
Зачем нужен Kparser?
На официальном сайте найдете несколько полезных статей с описанием способов применения Kparser. Например:
- В Youtube — осуществляет подбор тегов и ключевых слов с «длинным хвостом» для видео, которые бы отлично охарактеризовали ролик и были максимально эффективны с точки зрения продвижения.
- Google — сбор подсказок под SEO и Adwords. Используя совместно сервисы Adwords Keyword Tool и Kparser, вы достигнете лучшего результата по выборке. Причем последний выдает в разы больше информации + доступен всем пользователями.
- Google Search Console — соединение данных из двух инструментов позволит улучшить показатели органического трафа. Собирайте релевантные подсказки для тайтлов/текстов имеющихся страниц либо делайте новые под ключевые запросы с хорошим потенциалом.
- Определяйте минус слова под ваши Adwords и Direct кампании.
- Google Search Trends — ищите трендовые направления для создания актуального контента + формируйте через Kparser фразы с длинным хвостом.
- eBay + Amazon — по аналогии с Youtube и другими нишевыми продуктами рассматриваемый проект помогает определять релевантные ключи и поднять ваш товар повыше в выдаче.
Советую хорошенько изучить все эти инструкции, т.к. там весьма детально рассмотрены ситуации, в которых Kparser позволит выжать максимум из того или иного сервиса. К сожалению, пока что информация представлена только на английском.
Возьмем к примеру Youtube…
По правилам хорошей оптимизации ролика вам нужно:
- придумать наиболее релевантный ключевой запрос для видео;
- использовать его в имени загружаемого файла, заголовке и других элементах на странице;
- создать хорошее описание с вашими ключевиками и похожими по смыслу фразами;
- добавить запросы в теги, по которым должны находить данное видео;
- напоследок поделитесь роликом во всех своих социальных аккаунтах и, возможно, попросите об этом друзей либо закажите небольшую рекламу — надо постараться сделать своего рода вирусный эффект после публикации.
Теги для видоса — очень важны. Если их не указываете, то получите нулевую оценку параметра vidIQ. С заполненными полями результат явно получше:
Теги добавляются дабы поисковики понимали о чем ваше видео и, соответственно, по каким запросам в Youtube оно будет ранжироваться.
Если у вас новый канал, старайтесь использовать менее конкурентные ключевики с длинным хвостом — так больше шансов побороться за трафик. Популярным авторам есть смысл вклиниться в борьбу по крутым тегам. Найти подходящие варианты вам как раз и поможет текущий инструмент.
Различия между Словоеб_ом и Key Collector_ом
Разницу между программами Словоёб и Key Collector вы можете увидеть в на следующем рисунке (в виде таблицы):
Пусть программа Slovoeb не может получать позиции запросов, выполнять пакетный сбор Google AdWords, производить интеллектуальный сбор поисковых подсказок, выполнять прогноз трафика по контексту и исполнять другие функции, включенные в КейКоллектор, однако другие её функции очень полезны.
Парсинг, анализ заранее введённых слов
Словоёб позволяет выполнять пакетный сбор слов из левой и правой колонки Яндекс.Вордстат, а также пакетный сбор из Рамблер.Адстат, а также собирать в пакетном режиме поисковые подсказки. Далее, полученные слова можно проанализировать — получить частотности, узнать количество вхождений в заголовки внутренних и главных страниц.
Анализ можно провести также для самостоятельно введённых слов.
Прокси-серверы в Словоеб_е
Словоеб поддерживает работу через HTTP прокси-сервера (в том числе и с защитой доступа по паролю). Доступна загрузка списка прокси-серверов из файла или их ручная формировка. После создание списка в ручном режиме, его можно будет экспортировать в файл, нажимая кнопку «Сохранить в файл». Чтобы указать программе прокси-сервер, который следует использовать, нужно отметить строку с этим сервером галочкой. Доступные настройки вы можете увидеть на рисунке:
«Использовать прокси-серверы» — если отметить, то программа начинает использовать прокси-сервера из таблицы прокси-серверов (зелёные, отмеченные флажками).
«Деактивировать на 360 сек. не прошедшие проверку прокси-серверы» — если эта опция включена и программа получила ошибку, то после выполнения быстрой проверки на доступность прокси-сервера и получения сообщения о его недоступности, сервер исключается из очереди прокси-серверов на 360 секунд.
«Отключать в настройках отброшенные при парсинге прокси-серверы» — указание для программы автоматически выключать отброшенный прокси-сервер в таблице прокси-серверов.
«Отключать в настройках деактивированные из-за капчи прокси-серверы» — если вы используете хорошие прокси, то капчу лучше распознавать, нежели отклонять её.
Системные требования
Если подразумевается обработка большого числа данных (количество ключевых слов исчисляется десятками и сотнями тысяч штук), то желательно иметь высокопроизводительный компьютер. В таком случае также важна оперативная память ПК — чем больше, тем лучше. Наиболее оптимальной оперативной памятью является 3Гб, но и при меньших объёмах программа будет работать, правда медленно и менее устойчиво.
Также есть минимальные рекомендуемые системные требования:
- Операционная система Windows 7/8/8.1/10 или Windows XP/Vista
- Объём оперативной памяти от 2 Гб
- Тактовая частота процессора от 1,8 ГГц
- Также требуются дополнительные модули Microsoft.NET Framework 4.5 Full(для Windows 7/8/8.1/10) или Microsoft.NET Framework 4.0 Full(для других версий Windows).
О том, как настроить и использовать эту программу читайте в следующих статьях!
Что такое парсинг?
Начнем с определения. Парсинг – это метод индексирования информации с последующей конвертацией ее в иной формат или даже иной тип данных.
Парсинг позволяет взять файл в одном формате и преобразовать его данные в более удобоваримую форму, которую можно использовать в своих целях. К примеру, у вас может оказаться под рукой HTML-файл. С помощью парсинга информацию в нем можно трансформировать в «голый» текст и сделать понятной для человека. Или конвертировать в JSON и сделать понятной для приложения или скрипта.
Но в нашем случае парсингу подойдет более узкое и точное определение. Назовем этот процесс методом обработки данных на веб-страницах. Он подразумевает анализ текста, вычленение оттуда необходимых материалов и их преобразование в подходящий вид (тот, что можно использовать в соответствии с поставленными целями). Благодаря парсингу можно находить на страницах небольшие клочки полезной информации и в автоматическом режиме их оттуда извлекать, чтобы потом переиспользовать.
Ну а что такое парсер? Из названия понятно, что речь идет об инструменте, выполняющем парсинг. Кажется, этого определения достаточно.
Маркерные запросы
Маркерные запросы — это запросы, которые четко отвечают продвигаемой странице. Такие запросы обычно имеют значимую частотность ключевых слов по Wordstat и являются средне-частотными (СЧ), или «жирными» низкочастотниками (НЧ), и могут породить «хвост» запросов, например при добавлении слов «купить», «цена», «отзывы».
Примеры:
Платья
Красные платья
Красные платья в пол
Телевизоры
Телевизоры Samsung
Телевизоры Самсунг
LED телевизоры Samsung
Стиральные машины
Стиральные машины для дачи
Стиральные машины шириной 40 см
Другими словами, эти ключевые слова часто являются названием страниц/категорий/статей/карточек товара и прочих типов страниц, которые вообще можно продвигать в поисковых системах.
Часто задаваемые вопросы про маркеры:
Q: Могут ли для страницы быть несколько маркеров?
A: Да — конечно — это довольно частый случай.
Например, на одну страницу могут идти такие маркеры как:
Телевизоры Samsung
Телевизоры Samsung купить
Телевизоры Самсунг
Телевизоры Самсунг купить
Телевизоры самсунг цена
Все эти запросы четко отвечают одной странице
Так же на одну страницу могут идти два маркера-синонима, не связанных лингвистически:
Спецоджеда
Рабочая одежда
или
электроплита бош
электрическая плита bosch
Это вполне нормально и логично.
НЕ маркеры — облако запросов. Это все второстепенные запросы, которые уточняют маркерные запросы — т.е. по факту это маркеры + 1/2/3 слова или синонимы маркеров. Как правило запросы из облака — менее частотные и поэтому мы будем привязывать их к маркерам
Как найти маркерные запросы?
Вариант №1: можно получить поисковые запросы из Яндекс Метрики. Плюсы такого метода — что вы сразу будете знать релевантные URL для этих запросов.
Вариант №2: Берем названия категорий/услуг своего сайта и расширяем их логическими гипотезами:«Как, по каким запросам пользователи еще могут искать эту страницу моего сайта? Какие есть синонимы?»
NB!: Отличным подспорьем в определении маркеров является старый добрый Яндекс Wordstat, при всех его недостатках. Рекомендуем использовать браузерный плагин Yandex Wordstat Assistant от компании Semantica — очень удобный — выполняет роль своего рода «заметок на полях» — в него можно в один клик добавить интересующие слова.
Мы понимаем, что не у каждого оптимизатора/владельца бизнеса есть под рукой департамент разработки, который быстро сможет выгрузить для сайта связку URL — название категории/страницы.
Что такое связка URL-название категории/страницы?
Поэтому есть 3 варианта как получить связку URL — название категории/страницы:
Фактически маркеры для вашего сайта будут состоять из:
- Запросов, выгруженных из Яндекс Метрики
- Названий категорий/страниц, взятых с сайта
- Расширений названий категорий/страниц т.е. логических гипотез
Важно выполнить эту часть работы по подбору семантического ядра максимально тщательно т.к. если вы потеряете большую часть маркеров — вы потеряете большую часть семантического ядра
Часто задаваемые вопросы по подбору маркеров:
Q: У меня большой сайт и маркеров сотни или тысячи — как быть?!
Q: На сколько низкочастотное слово может быть маркером?
A: Здесь все зависит от тематики. В узких тематиках даже ключевые слова с частотностью 15 по кавычкам «» могут быть маркерными запросами. Главное правило — спросите себя — хотел бы мой пользователь видеть отдельную страницу под этот запрос (и связанные с ним?). Удобно ли ему будет пользоваться той структурой, что я создаю?
Q: Как мне держать маркеры в Excell, чтобы потом мне было удобно с ними работать?
A: Идеальный и единственно правильный вариант — всегда держать связку URL-маркер в Excel — так вы всегда сможете понимать какие маркеры идут на один URL, даже если ваш список перемешается.
В дальнейшем таким образом вы сможете фильтровать целые кластеры, которые идут на одну страницу — это может быть и 10 и 50 ключевых слов. Очень удобно.
Пример правильного оформления маркеров в Excel
Итак, после N времени работы мы собрали маркеры для всего сайта (или части сайта), что дальше?
Естественно, что маркеры, это далеко не полная семантика — теперь нам нужно собрать облако запросов — расширить наше семантическое ядро.
Как проверить частоту запросов и их конкурентность
Прежде всего, в семантическое ядро сайта нужно включить все типы частотных запросов. Исключить можно НЧ запросы с показателем 10 и менее запросов в месяц. Если у вас магазин, то 5 и менее запросов в месяц.
Чтобы проверить частоту запросов пользователями в месяц, для начала, освойте работу с простыми серверами подбора ключевых слов:
- Яндекс-Wordstat;
- Google-AdWords.
Яндекс — Wordstat.yandex
Для Рунета, этот сервис наиболее подходящий. Он простой понятный без заморочек. Выдает нужные показатели, есть минимальные фильтры, есть недостатки, которые не мешают, например, нет экспорта результатов.
Как работать с Wordstat.yandex
- Авторизуйтесь в Яндекс. Войдите на сервис (https://wordstat.yandex.ru/);
- В форму поиска введите нужное ключевое слово (фразу) общего характера (ВЧ запрос);
- Wordstat.yandex откроет вам большую таблицу, где будут показаны и ваш ВЧ запрос и все включающие и похожие запросы, которые делались в поисковике Яндекс за последний месяц. Можете уточнить запрос по региону, для этого есть фильтр.
Составление семантического ядра на Яндекс подбор слов
В левой таблице вы видите все запросы с вашим ключевым словом, включая фразы с этим словом, которые пользователи вводили в поисковик.
В правой таблице, запросы близкие к вашим, причем эти запросы делались людьми, искавшими ваше ключевое слово. Эти фразы можно использовать в статьях, если вы подбираете ключевик отдельной статьи. Для общего семантического ядра эти фразы не нужны.
Но это еще не все. Можно использовать язык поисковых запросов. Если в поиск Wordstat.yandex ввести туже ключевую фразу в кавычках, сервис выдаст вам количество точных запросов, по этой фразе. Например, вводим запрос мебель, теперь в кавычках «мебель» (копирование фразы не пройдет, набираем руками): получаем, только статистику точных запросов – мебель.
Можно пойти дальше. Выясняем, сколько людей запрашивали конкретную фразу, без дополнительных словесных вхождений. Делаем такой запрос: «!мебель !для !дома». Получаем точное количество запросов, точной фразы – мебель для дома.
Запросы с кавычками и с восклицательным знаком используем, для тонкой коррекции семантического ядра. А пока, нас интересует первый анализ, со всеми возможными формами.
К сожалению, у Wordstat.yandex нет экспорта найденных запросов, поэтому таблицу запросов копируем и экспортируем в Excel вручную.
В приведенном примере, запроса (мебель), Wordstat.yandex выдал 40 страниц. Дальше аналитическая работа. Из всех найденных вариантов отбираете нужные вам запросы, они же ключевые слова вашего семантического ядра.
Можно пойти таким путем:
Из первого анализа по общей фразе без кавычек, подобрать ключевые фразы для разделов сайта
Например: мебель – разделы по Wordstat.yandex: корпусная мебель, кухонная мебель, мебель гостиной, детская мебель и т. д.
- Далее для каждого названия раздела подбираем свой список фраз;
- Если есть подразделы, для них тоже делаем анализ;
- В результате получаем древовидную структуру ключевых слов и фраз семантического ядра сайта.