Контекстные менеджеры в python
Содержание:
- The file Object Attributes
- Извлечение текста с помощью PyPDF2
- Шаг 6 — Проверка кода
- Извлечение изображений из PDF с помощью PyMuPDF
- Закрытие открытого файла с помощью метода close()
- Openpyxl formulas
- Чтение файлов JSON с помощью Pandas
- Что такое файл CSV?
- Метод write() для записи в файл в Python
- Альтернатива для модуля glob
- Openpyxl append values
- Other Useful Items
- Open multiple files in a single “with statement”
- Примеры построчного чтения файла.
- Создание файла, его открытие и закрытие
- Синтаксис YAML¶
- Шаг 4 — Запись файла
- Openpyxl Charts
- Генерация кроссплатформенных путей в Pathlib
- Производит чтение одной строки из файла.
The file Object Attributes
Once a file is opened and you have one file object, you can get various information related to that file.
Here is a list of all attributes related to file object −
| Sr.No. | Attribute & Description |
|---|---|
| 1 |
file.closed Returns true if file is closed, false otherwise. |
| 2 |
file.mode Returns access mode with which file was opened. |
| 3 |
file.name Returns name of the file. |
| 4 |
file.softspace Returns false if space explicitly required with print, true otherwise. |
Example
#!/usr/bin/python
# Open a file
fo = open("foo.txt", "wb")
print "Name of the file: ", fo.name
print "Closed or not : ", fo.closed
print "Opening mode : ", fo.mode
print "Softspace flag : ", fo.softspace
This produces the following result −
Name of the file: foo.txt Closed or not : False Opening mode : wb Softspace flag : 0
Извлечение текста с помощью PyPDF2
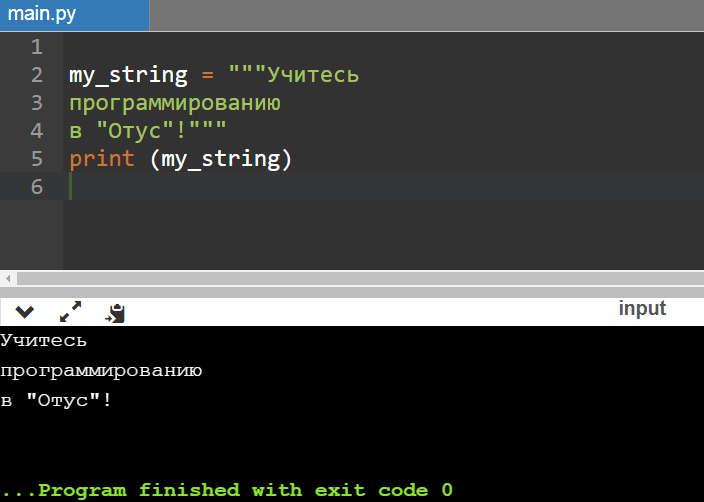
Начнём с . Ниже приведен скрипт, который позволяет извлечь из PDF‑файла текст и вывести него в консоль.
Сначала импортируем , помня о том, что пакет уже установлен. Задаём имя файла из папки (можете загрузить туда свой файл и поменять в скрипте на имя загруженного файла), открывает документ и получаем информацию о документе, используя метод и общее количество страниц . Далее в цикле читаем каждую страницу, получаем содержимое и печатаем в .
Обратите внимание, что PyPDF2 начинает считать страницы с 0, и поэтому вызов при извлекает первую страницу документа
from PyPDF2 import PdfFileReader
pdf_document = "source/Computer-Vision-Resources.pdf"
with open(pdf_document, "rb") as filehandle:
pdf = PdfFileReader(filehandle)
info = pdf.getDocumentInfo()
pages = pdf.getNumPages()
print("Количество страниц в документе: %i\n\n" % pages)
print("Мета-описание: ", info)
for i in range(pages):
page = pdf.getPage(i)
print("Стр.", i, " мета: ", page, "\n\nСодержание;\n")
print(page.extractText())
Извлечение текста с помощью PyPDF2
Как видите, извлеченный текст печатается сплошным потоком. Здесь нет ни абзацев, ни разделений предложений. Как указано в документации по PyPDF2, все текстовые данные возвращаются в том порядке, в котором они представлены на странице. В основном, это зависит от внутренней структуры документа PDF и от того, как поток инструкций, создан во время его записи, поэтому их использование может привести к неожиданностям, надо дополнительно «парсить», не очень удобно.
Шаг 6 — Проверка кода
Конечный результат должен выглядеть примерно так:
files.py
path = '/users/sammy/days.txt' days_file = open(path,'r') days = days_file.read() new_path = '/users/sammy/new_days.txt' new_days = open(new_path,'w') title = 'Days of the Weekn' new_days.write(title) print(title) new_days.write(days) print(days) days_file.close() new_days.close()
После сохранения кода откройте терминал и запустите свой Python- скрипт, например:python files.py
Результат должен выглядеть так:
Вывод Days of the Week Monday Tuesday Wednesday Thursday Friday Saturday Sunday
Теперь проверим код полностью, открыв файл new_days.txt. Если все пройдет хорошо, когда мы откроем этот файл, его содержимое должно выглядеть следующим образом:
new_days.txt
Days of the Week Monday Tuesday Wednesday Thursday Friday Saturday Sunday
Извлечение изображений из PDF с помощью PyMuPDF
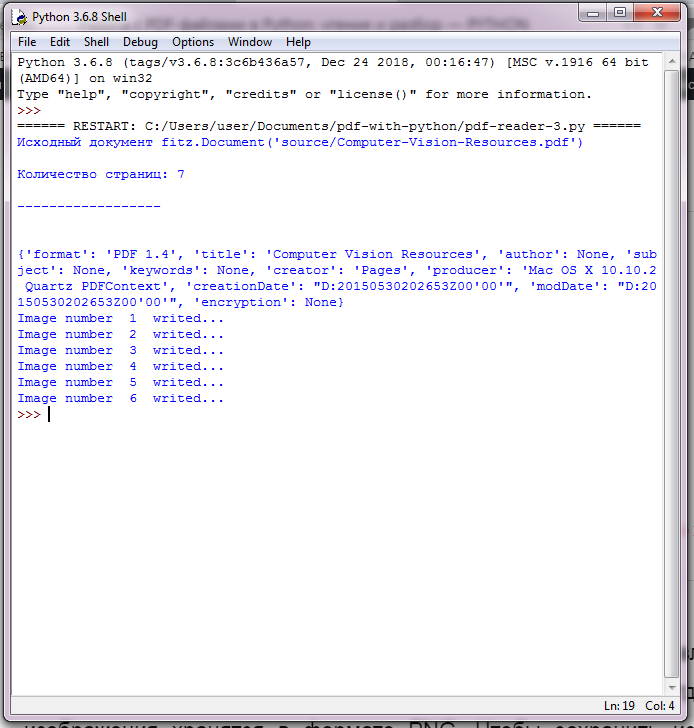
Переходим к изображениям. PyMuPDF упрощает извлечение изображений из документов PDF с использованием метода . Скрипт, приведённый ниже, основан на примере из вики-страницы PyMuPDF и извлекает и постранично сохраняет все изображения из PDF в формате PNG. Если изображение имеет цветовое пространство CMYK, оно будет сначала преобразовано в RGB.
import fitz
pdf_document = "source/Computer-Vision-Resources.pdf"
doc = fitz.open(pdf_document)
print("Исходный документ", doc)
print("\nКоличество страниц: %i\n\n------------------\n\n" % doc.pageCount)
print(doc.metadata)
page_count = 0
for i in range(len(doc)):
for img in doc.getPageImageList(i):
xref = img
pix = fitz.Pixmap(doc, xref)
pix1 = fitz.Pixmap(fitz.csRGB, pix)
page_count += 1
pix1.writePNG("images/picture_number_%s_from_page_%s.png" % (page_count, i+1))
print("Image number ", page_count, " writed...")
pix1 = None
 Извлечение изображений
Извлечение изображений
Этот скрипт Python извлёк 773 изображения на 400-страничном PDF, размером полгигабайта менее чем за 3 минуты, что удивительно. Отдельные изображения хранятся в формате PNG. Чтобы сохранить исходный формат и размер изображения вместо преобразования в PNG, взгляните на расширенные версии сценариев в .
Закрытие открытого файла с помощью метода close()
Когда вы открываете файл в Python, чрезвычайно важно закрыть файл после внесения изменений. Это сохраняет любые изменения, которые вы сделали ранее, удаляет файл из памяти и предотвращает дальнейшее чтение или запись в программе
Синтаксис для закрытия открытого файла в Python:
fileobject.close()
Если мы продолжим наши предыдущие примеры, где мы читаем файлы, вот как вы закроете файл:
text_file = open('/Users/pankaj/abc.txt','r')
# some file operations here
text_file.close()
Кроме того, вы можете избежать закрытия файлов вручную, если используете блок with. Как только блок with выполняется, файлы закрываются и становятся недоступными для чтения и записи.
Openpyxl formulas
The next example shows how to use formulas. The does
not do calculations; it writes formulas into cells.
formulas.py
#!/usr/bin/env python
from openpyxl import Workbook
book = Workbook()
sheet = book.active
rows = (
(34, 26),
(88, 36),
(24, 29),
(15, 22),
(56, 13),
(76, 18)
)
for row in rows:
sheet.append(row)
cell = sheet.cell(row=7, column=2)
cell.value = "=SUM(A1:B6)"
cell.font = cell.font.copy(bold=True)
book.save('formulas.xlsx')
In the example, we calculate the sum of all values
with the function and style the
output in bold font.
rows = (
(34, 26),
(88, 36),
(24, 29),
(15, 22),
(56, 13),
(76, 18)
)
for row in rows:
sheet.append(row)
We create two columns of data.
cell = sheet.cell(row=7, column=2)
We get the cell where we show the result of the calculation.
cell.value = "=SUM(A1:B6)"
We write a formula into the cell.
cell.font = cell.font.copy(bold=True)
We change the font style.
Figure: Calculating the sum of values
Чтение файлов JSON с помощью Pandas
Чтобы прочитать файл JSON с помощью Pandas, вызовем метод read_json() и передадим ему путь к файлу, который нужно прочитать. Метод возвращает DataFrame, который хранит данные в виде столбцов и строк.
Но сначала нужно установить библиотеку Pandas:
$ pip install pandas
Чтение JSON из локальных файлов
Приведенный ниже скрипт считывает файл patients.json из локальной системной директории и сохраняет результат во фрейме данных patients_df. Затем заголовок фрейма выводится с помощью метода head():
import pandas as pd
patients_df = pd.read_json('E:/datasets/patients.json')
patients_df.head()
Запуск этого кода должен дать следующий результат:
Следующий скрипт считает файл cars.json из локальной системы и затем вызовет метод head()cars_df для вывода заголовка:
cars_df = pd.read_json('E:/datasets/cars.json')
cars_df.head()
Результат запуска этого кода:
Чтение JSON из удаленных файлов
С помощью метода read_json() также можно считывать файлы JSON, расположенные на удаленных серверах. Для этого нужно передать в вызов функции путь удаленного файла JSON.
Давайте прочитаем и выведем заголовок из Iris Dataset:
import pandas as pd
iris_data = pd.read_json("https://raw.githubusercontent.com/domoritz/maps/master/data/iris.json")
iris_data.head()
Результат запуска этого кода:
Что такое файл CSV?
Файл CSV (файл значений, разделенных запятыми) – это тип простого текстового файла, в котором для упорядочения табличных данных используется определенное структурирование. Поскольку это простой текстовый файл, он может содержать только фактические текстовые данные – другими словами, печатные символы ASCII или Unicode .
Структура CSV-файла определяется его именем. Обычно файлы CSV используют запятую для разделения каждого конкретного значения данных. Вот как выглядит эта структура:
Обратите внимание, что каждый фрагмент данных разделен запятой. Обычно первая строка идентифицирует каждый фрагмент данных, другими словами, имя столбца данных. Каждая последующая строка после этого является фактическими данными и ограничена только ограничениями размера файла. В общем, символ разделителя называется разделителем, и запятая используется не только одна. Другие популярные разделители включают символы табуляции ( ), двоеточия ( ) и точки с запятой ( ). Правильный анализ файла CSV требует, чтобы мы знали, какой разделитель используется
В общем, символ разделителя называется разделителем, и запятая используется не только одна. Другие популярные разделители включают символы табуляции ( ), двоеточия ( ) и точки с запятой ( ). Правильный анализ файла CSV требует, чтобы мы знали, какой разделитель используется.
Откуда берутся файлы CSV?
Файлы CSV обычно создаются программами, которые обрабатывают большие объемы данных. Это удобный способ экспортировать данные из электронных таблиц и баз данных, а также импортировать или использовать их в других программах. Например, вы можете экспортировать результаты программы интеллектуального анализа данных в файл CSV, а затем импортировать их в электронную таблицу для анализа данных, создания графиков для презентации или подготовки отчета для публикации.
С файлами CSV очень легко работать программно. Любой язык, который поддерживает ввод текстовых файлов и манипуляции со строками (например, Python), может работать с файлами CSV напрямую.
Метод write() для записи в файл в Python
В предыдущих примерах мы уже использовали метод write(). Он позволяет записывать любую строку в открытый файл. Помните, что строки в Python способны содержать не только текст, но и двоичные данные.
Запись в файл построчно выполняется посредством записи нужной вам строки с последующей записью \n— символа перевода строки.
Давайте ещё раз посмотрим на запись в файл с помощью метода write().
Синтаксис:
my_file.write(string);
Пример использования:
my_file = open("otus.txt", "w")
my_file.write("Люблю Python!\nЭто крутой язык!")
my_file.close()
Код, представленный выше, создаст файл otus.txt , записав в него указанную строку.
Давайте теперь выполним запись списка поэлементно, где каждый элемент списка будет записан в новой строке:
lines = "one", "two", "three"
with open(r"C:\otus.txt", "w") as file
for line in lines
file.write(line + '\n')
Этот код позволит создать небольшой массив lines, содержащий три строковых элемента: «one», «two» и «three». Благодаря функции open и связке операторов with as произойдёт открытие текстового файла otus.txt в корневом каталоге жёсткого диска C. Далее произойдёт запись всех элементов списка с помощью write. Символ \n обеспечит, чтобы каждая запись была выполнена с новой строки.
Альтернатива для модуля glob
Помимо модулей , в Python также доступен модуль , что предоставляет путь связанных утилит. Функция модуля используется для нахождения файлов, соответствующих шаблону.
Python
from glob import glob
top_xlsx_files = glob(‘*.xlsx’) # Все файлы с расширением .xlsx
all_xlsx_files = glob(‘**/*.xlsx’, recursive=True)
|
1 2 3 4 |
fromglobimportglob top_xlsx_files=glob(‘*.xlsx’)# Все файлы с расширением .xlsx all_xlsx_files=glob(‘**/*.xlsx’,recursive=True) |
Pathlib предоставляет свою реализацию :
Python
from pathlib import Path
top_xlsx_files = Path.cwd().glob(‘*.xlsx’)
all_xlsx_files = Path.cwd().rglob(‘*.xlsx’)
|
1 2 3 4 |
frompathlib importPath top_xlsx_files=Path.cwd().glob(‘*.xlsx’) all_xlsx_files=Path.cwd().rglob(‘*.xlsx’) |
Функциональность glob доступна с объектами . Следовательно, модуль Pathlib упрощают сложные задачи.
Openpyxl append values
With the method, we can append a group of
values at the bottom of the current sheet.
appending_values.py
#!/usr/bin/env python
from openpyxl import Workbook
book = Workbook()
sheet = book.active
rows = (
(88, 46, 57),
(89, 38, 12),
(23, 59, 78),
(56, 21, 98),
(24, 18, 43),
(34, 15, 67)
)
for row in rows:
sheet.append(row)
book.save('appending.xlsx')
In the example, we append three columns of data into
the current sheet.
rows = (
(88, 46, 57),
(89, 38, 12),
(23, 59, 78),
(56, 21, 98),
(24, 18, 43),
(34, 15, 67)
)
The data is stored in a tuple of tuples.
for row in rows:
sheet.append(row)
We go through the container row by row and insert
the data row with the method.
Other Useful Items
- Looking for 3rd party Python modules? The
Package Index has many of them. - You can view the standard documentation
online, or you can download it
in HTML, PostScript, PDF and other formats. See the main
Documentation page. - Information on tools for unpacking archive files
provided on python.org is available. -
Tip: even if you download a ready-made binary for your
platform, it makes sense to also download the source.
This lets you browse the standard library (the subdirectory Lib)
and the standard collections of demos (Demo) and tools
(Tools) that come with it. There’s a lot you can learn from the
source! - There is also a collection of Emacs packages
that the Emacsing Pythoneer might find useful. This includes major
modes for editing Python, C, C++, Java, etc., Python debugger
interfaces and more. Most packages are compatible with Emacs and
XEmacs.
Open multiple files in a single “with statement”
Let’s open two files using a single “with statement”. We will read from sample.txt and write in the outfile.txt,
# Read from sample.txt and write in outfile.txt
with open('outfile.txt', 'w') as file_obj_2, open('sample.txt', 'r') as file_obj_1:
data = file_obj_1.read()
file_obj_2.write(data)
# Both the files will be closed automatically when execution block ends.
The complete example is as follows,
def main():
print('*** Open a file using without "open with" statement ***')
print('Normal way of opening & reading from a file using open() function')
# open a file
file_object = open('sample.txt')
# read the file content
data = file_object.read()
print(data)
#close the file
file_object.close()
print('** Open a file using open() function & handle exception **')
# File is not closed in case of exception
try:
# open a file
file_object = open('sample.txt')
# read file content
data = file_object.read()
# It will raise an exception
x = 1 / 0
print(data)
file_object.close()
except:
# Handling the exception
print('An Error')
finally:
if file_object.closed == False:
print('File is not closed')
else:
print('File is closed')
print('**** Open a file using "open with" statement ****')
# using "with statement" with open() function
with open('sample.txt', "r") as file_object:
# read file content
data = file_object.read()
# print file contents
print(data)
# Check if file is closed
if file_object.closed == False:
print('File is not closed')
else:
print('File is closed')
print('**** "open with" statement & Exception handling ****')
# File will be closed before handling the exception
try:
# using "with statement" with open() function
with open('sample.txt', "r") as file_object:
# read file content
data = file_object.read()
# it raises an error
x = 1 / 0
print(data)
except:
# handling exception
print('An Error')
if file_object.closed == False:
print('File is not closed')
else:
print('File is closed')
print('**** Multiple open() function calls in a single "with statement" ****')
# Read from sample.txt and write in outfile.txt
with open('outfile.txt', 'w') as file_obj_2, open('sample.txt', 'r') as file_obj_1:
data = file_obj_1.read()
file_obj_2.write(data)
# Both the files will be closed automatically when execution block ends.
if __name__ == '__main__':
main()
*** Open a file using without "open with" statement *** Normal way of opening & reading from a file using open() function This is a sample file. It contains some sample string. you are going to use it. Thanks. ** Open a file using open() function & handle exception ** An Error File is not closed **** Open a file using "open with" statement **** This is a sample file. It contains some sample string. you are going to use it. Thanks. File is closed **** "open with" statement & Exception handling **** An Error File is closed **** Multiple open() function calls in a single "with statement" ****
Примеры построчного чтения файла.
- ;
- ;
- .
Общий случай использования метода файла .
# подготовим файл 'foo.txt'
>>> text = 'This is 1st line\nThis is 2nd line\nThis is 3rd line\n'
>>> fp = open('foo.txt', 'w+')
# запишем текст в файл 'foo.txt'
>>> fp.write(text)
# 51
# указатель в начало файла
>>> fp.seek()
# 0
# начинаем читать построчно
>>> fp.readline()
# 'This is 1st line\n'
>>> fp.readline()
# 'This is 2nd line\n'
>>> fp.readline()
# 'This is 3rd line\n'
>>> fp.readline()
# ''
>>> fp.close()
Чтение файла при помощи цикла .
Так как операция открытия файла возвращает поток, представляющий из себя генератор строк из файла, то можно итерироваться по нему при помощи функции .
>>> fp = open('foo.txt', 'r')
>>> next(fp)
# 'This is 1st line\n'
>>> next(fp)
# 'This is 2nd line\n'
>>> next(fp)
# 'This is 3rd line\n'
>>> next(fp)
# Traceback (most recent call last):
# File "<stdin>", line 1, in <module>
# StopIteration
>>> fp.close()
Так как цикл делает то же самое, а именно при прохождении по последовательности вызывает , следовательно, более просто, читать файл построчно, без ущерба для оперативной памяти можно следующим образом.
Внимание! Функцию предпочтительнее использовать с оператором контекстного менеджера. При использовании оператора файл закрывать не нужно:
>>> with open('foo.txt', 'r') as fp
... for n, line in enumerate(fp, 1):
... # Обработка строки 'line'
... line = line.rstrip('\n')
... print(f"Вывод строки: {n}) - {line}")
...
# Вывод строки: 1) - This is 1st line
# Вывод строки: 2) - This is 2nd line
# Вывод строки: 3) - This is 3rd line
Чтение строк файла кусками при помощи цикла .
Возможно возникнет вопрос, зачем тогда вообще нужен метод файла , если все так просто. Ответы просты. А если необходимо прочитать только одну строку? А если строка файла (до разделителя строки ) очень длинная и не умещается в оперативной памяти, то тогда приходит на помощь метод файла , т.к. он умеет разбивать строку файла на куски.
>>> fp = open('foo.txt', 'r')
# будем читать строку по 10 байт
>>> line = fp.readline(10)
>>> while line
... line = line.rstrip('\n')
... print(line)
... line = fp.readline(10)
...
# This is 1s
# t line
# This is 2n
# d line
# This is 3r
# d line
>>> fp.close()
Создание файла, его открытие и закрытие
Работа с текстовым файлом в Python начинается с момента вызова функции open. Она принимает в качестве атрибутов путь к объекту на ПК и режим обработки. Вы можете указать абсолютный путь (это адрес размещения на жёстком диске) или относительный (речь идёт о координатах относительно папки проекта).
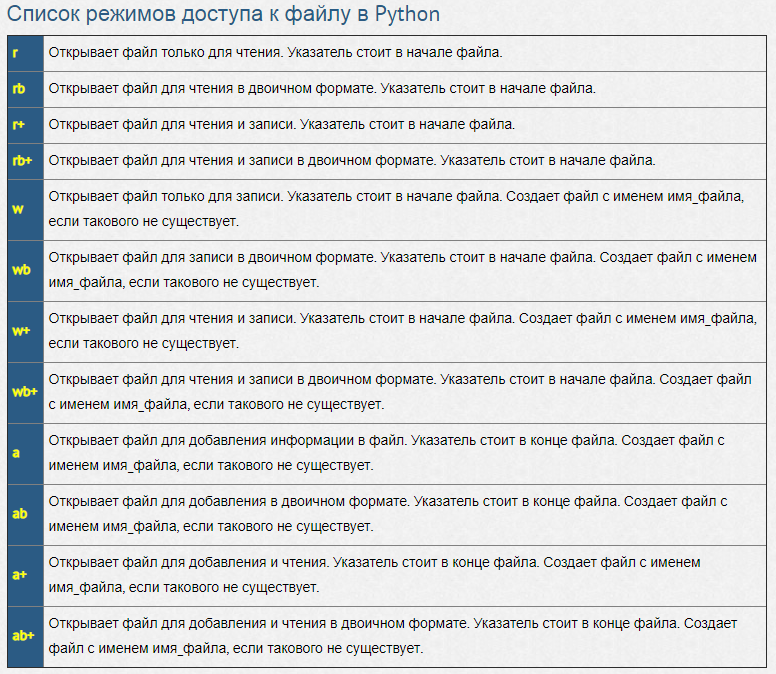
Что касается режима обработки файла, то при его выборе учитывайте его назначение («r» — для чтения, «w» — для записи). Таблица ниже позволит вам ознакомиться с режимами доступа к файлу в Python:
А вот пример простейшего взаимодействия с текстовым документом:
file = open("otus.txt", "w")
file.write("hello world")
file.close()
Здесь функция open принимает относительный путь, открывая его для записи. При этом, если в папке файл otus.txt будет отсутствовать, метод open создает его автоматически, после чего откроет для него нужный режим обработки.
Метод close закрывает файл, а это необходимо сделать, выполнив нужные вам действия с переменной file (иначе потеряете информацию). Впрочем, можно обойтись и без close, используя связку операторов with as (переменная, которая ссылается на файл, должна быть прописана после конструкции):
with open("otus.txt", "w") as file
file.write("hello world")
Синтаксис YAML¶
Как и Python, YAML использует отступы для указания структуры документа.
Но в YAML можно использовать только пробелы и нельзя использовать знаки
табуляции.
Еще одна схожесть с Python: комментарии начинаются с символа # и
продолжаются до конца строки.
Список
Список может быть записан в одну строку:
switchport mode access, switchport access vlan, switchport nonegotiate, spanning-tree portfast, spanning-tree bpduguard enable
Или каждый элемент списка в своей строке:
- switchport mode access - switchport access vlan - switchport nonegotiate - spanning-tree portfast - spanning-tree bpduguard enable
Когда список записан таким блоком, каждая строка должна начинаться с
(минуса и пробела), и все строки в списке должны быть на одном
уровне отступа.
Словарь также может быть записан в одну строку:
{ vlan 100, name IT }
Или блоком:
vlan 100 name IT
Строки
Строки в YAML не обязательно брать в кавычки. Это удобно, но иногда всё
же следует использовать кавычки. Например, когда в строке используется
какой-то специальный символ (специальный для YAML).
Такую строку, например, нужно взять в кавычки, чтобы она была корректно
воспринята YAML:
command "sh interface | include Queueing strategy:"
Шаг 4 — Запись файла
На этом этапе мы запишем новый файл, который включает в себя название «Days of the Week», и дни недели. Сначала создадим переменную title.
files.py
title = 'Days of the Weekn'
Также нужно сохранить дни недели в строковой переменной days. Открываем файл в режиме чтения, считываем файл и сохраняем вывод в новую переменную days.
files.py
path = '/users/sammy/days.txt' days_file = open(path,'r') days = days_file.read()
Теперь, когда у нас есть переменные для названия и дней недели, запишем их в новый файл. Сначала нужно указать расположение файла. Мы будем использовать каталог /users/sammy/. Также нужно указать новый файл, который мы хотим создать. Фактический путь будет /users/sammy/new_days.txt. Мы записываем его в переменную new_path. Затем открываем новый файл в режиме записи, используя функцию open() с режимом w.
files.py
new_path = '/users/sammy/new_days.txt' new_days = open(new_path,'w')
Если файл new_days.txt уже существовал до открытия, его содержимое будет удалено, поэтому будьте осторожны при использовании режима «w».
Когда новый файл будет открыт, поместим в него данные, используя <file>.write(). Операция write принимает один параметр, который должен быть строкой, и записывает эту строку в файл.
Если хотите записать новую строку в файл, нужно указать символ новой строки. Мы записываем в файл заголовок, за которым следуют дни недели.
iles.py
new_days.write(title) print(title) new_days.write(days) print(days)
Всякий раз, когда мы заканчиваем работу с файлом, нужно его закрыть. Мы покажем это в заключительном шаге.
Openpyxl Charts
The library supports creation of various charts, including
bar charts, line charts, area charts, bubble charts, scatter charts, and pie charts.
According to the documentation, supports chart creation within
a worksheet only. Charts in existing workbooks will be lost.
create_bar_chart.py
#!/usr/bin/env python
from openpyxl import Workbook
from openpyxl.chart import (
Reference,
Series,
BarChart
)
book = Workbook()
sheet = book.active
rows =
for row in rows:
sheet.append(row)
data = Reference(sheet, min_col=2, min_row=1, max_col=2, max_row=6)
categs = Reference(sheet, min_col=1, min_row=1, max_row=6)
chart = BarChart()
chart.add_data(data=data)
chart.set_categories(categs)
chart.legend = None
chart.y_axis.majorGridlines = None
chart.varyColors = True
chart.title = "Olympic Gold medals in London"
sheet.add_chart(chart, "A8")
book.save("bar_chart.xlsx")
In the example, we create a bar chart to show the number of Olympic
gold medals per country in London 2012.
from openpyxl.chart import (
Reference,
Series,
BarChart
)
The module has tools to work with charts.
book = Workbook() sheet = book.active
A new workbook is created.
rows =
for row in rows:
sheet.append(row)
We create some data and add it to the cells of the active sheet.
data = Reference(sheet, min_col=2, min_row=1, max_col=2, max_row=6)
With the class, we refer to the rows in the sheet that
represent data. In our case, these are the numbers of olympic gold medals.
categs = Reference(sheet, min_col=1, min_row=1, max_row=6)
We create a category axis. A category axis is an axis with the data
treated as a sequence of non-numerical text labels. In our case, we have
text labels representing names of countries.
chart = BarChart() chart.add_data(data=data) chart.set_categories(categs)
We create a bar chart and set it data and categories.
chart.legend = None chart.y_axis.majorGridlines = None
Using and attributes, we
turn off the legends and major grid lines.
chart.varyColors = True
Setting to , each bar has a different
colour.
chart.title = "Olympic Gold medals in London"
A title is set for the chart.
sheet.add_chart(chart, "A8")
The created chart is added to the sheet with the method.
Figure: Bar chart
In this tutorial, we have worked with the openpyxl library. We have read data
from an Excel file, written data to an Excel file.
Visit Python tutorial or
list .
Генерация кроссплатформенных путей в Pathlib
Пути используют разные соглашения в разных операционных системах. Windows использует обратный слеш между названиями папок, тогда как все другие популярные операционные системы используют прямой слеш .
Если вы хотите, чтобы ваш код работал, независимо от базовой ОС, вам нужно будет обрабатывать различные соглашения, характерные для базовой платформы. Модуль Pathlib упрощает работу с путями к файлам. В Pathlib можно просто передать путь или название файла объекту , используя слеш, независимо от ОС. Pathlib занимается всем остальным.
Python
pathlib.Path.home() / ‘python’ / ‘samples’ / ‘test_me.py’
| 1 | pathlib.Path.home()’python»samples»test_me.py’ |
Объект конвертирует в слеш соответствующий операционной системе. может представлять путь Windows или Posix. Кроме того, Pathlib решает многие кросс-функциональные баги, легко обрабатывая пути.
Производит чтение одной строки из файла.
Описание:
Метод файла читает одну целую строку из файла. Конечный символ новой строки сохраняется в строке. Метод возвращает одну строку или байтовый объект в зависимости от режима, в котором открыт файл функцией .
Если необязательный аргумент присутствует и неотрицателен, то метод читает строку частями по байтов, пока не достигнет символ новой строки . Если отрицателен, то считывается строка полностью.
Пустая строка возвращается только тогда, когда достигнут конец файла, т. е. встречается немедленно.
- Прочитать файл кусками можно с помощью метода .
- Создать список строк из файла .