Как (и зачем) бесплатно парсить ключи и объявления конкурентов из яндекс.директ и google ads
Содержание:
- Метод перемножения
- Будущее
- Классификация семантики
- Плюсы и минусы раскрутки сайта в подсказках
- Парсеры сайтов в зависимости от используемой технологии
- Зачем нужен парсинг подсветок?
- Метод для получения максимального охвата
- Парсеры сайтов по способу доступа к интерфейсу
- Сбор частот
- Оффлайн парсеры
- Для чего нужен парсинг частотности
- Кому и зачем нужны парсеры сайтов
- Как собирать маски ключевых слов
- REGEXEXTRACT — извлекаем нужный текст из ячеек
- SUBSTITUTE — меняем/удаляем пробелы и спецсимволы
- Расширения для браузера Яндекс Wordstat
- Поиск «фейловых» ключей (тепловая карта позиций)
- Возможности Парсера и его преимущества
- Как пользоваться парсером подсказок от Click.ru: пошаговая инструкция
Метод перемножения
Шаг 1: расширения масок
Добавляем к базовым маскам расширения из одного слова, чтобы уточнить запрос по разным характеристикам в зависимости от специфики продукта:
Какие категории использовать — решаете сами. Откуда брать варианты? Сайты конкурентов, словари синонимов, тематические форумы и блоги — всё, где можно найти идеи о том, что именно в продукте интересует целевую аудиторию. Это могут быть синонимы, жаргоны, специфическая лексика и т.д.
Всё заносим для удобства в Excel. Получаем по каждому базису примерно такое:
Принцип: 1 ячейка = 1 слово.
Шаг 2: перемножение
Перемножаем первый столбец с остальными по очереди в любом сервисе генерирования ключевых слов:
Результаты переносим на отдельный лист, удаляем нецелевые и ультранизкочастотные запросы.
Будущее
В этот исторический момент мы поняли, что полноценное развитие ввода на мобильных связано с множеством различных аспектов: это и качество данных, и интерфейс, и сеть. Дальнейшее развитие должно было осуществляться во всех этих направлениях и, возможно, в ещё каких-то новых, которые ещё не были нами замеченными.
Кроме того, подсказки присутствуют не только в поиске, но также в наших приложениях, в браузере, в сервисах, отличных от Поиска, и с ними тоже нужно было что-то делать. Кроме того, ввод не обязан быть только текстовым.
И всем этим мы занялись в 2017 году. О том, к чему это привело, мы поговорим в следующей статье.
Классификация семантики
При сборе семантического ядра, важно учитывать какой тип семантики отвечает вашему сайту. Всю семантику можно поделить на:
- коммерческая / информационная;
- геозависимая / геонезависимая;
- сезонная / несезонная;
- высококонкурентная / среднеконкурентная / низкоконкурентная;
- Коммерческая семантика — это так-называемая «продающая» семантика с целью конвертировать посетителя сайта в потенциального покупателя / клиента. Зачастую в нее входят такие слова как: купить, цена, заказать, продать, обмен и так далее. Их еще называют транзакционными запросами.
Информационная семантика — это семантика, у которой нет коммерческой цели, основной целью является рассказать о чем-то / ком-то, например о продукте, товаре или персоне и т.д. Это может быть статья, справочная информация, просто текст — но информационного характера.
Геозависимая семантика — это семантика, которая имеет четкую привязку к конкретному населенному пункту. Например, «стоматологический кабинет “Арника” в Москве». И преимущественно — это коммерческая семантика. Такая семантика нацелена на поисковую выдачу по конкретному городу, а значит при сборе семантического ядра необходимо максимально учитывать ключевые слова именно по этому региону — все остальные населенные пункты игнорировать.
Геонезависимая семантика — это преимущественно информационная тематика, без привязки к конкретному населенному пункту. Например, новостные сайты, информационные порталы, статейники, аналитические ресурсы и так далее. То есть, это та семантика, которая не привязана к региону.
Ваша задача заключается в том, чтобы точно определить какой вид семантики отвечает вашему сайту и по ней собрать семантическое ядро.
Ядра смешанных типов семантики создавать не рекомендуется — запросы могут не правильно сгруппироваться и вы получите, грубо говоря, кривую структуру. Если же у вас сайт, на котором планирует несколько типов семантики — рекомендую разместить их на разных разделах и собрать отдельное семантическое ядро под каждый.
Плюсы и минусы раскрутки сайта в подсказках
Присутствие сайта в подсказках и расширение семантического ядра с их помощью для привлечения трафика — основные цели, которые преследуют вебмастера. Но, чтобы понять насколько эффективны подсказки в плане привлечения трафика, нужно выделить их преимущества и недостатки.
Плюсы наличия сайта (бренда) в подсказках
- Повышение узнаваемости. Когда пользователи видят рядом с запросом название бренда, они больше ему доверяют, считая лидером ниши. Соответственно по таким запросам больше конверсия.
- Лояльность целевой аудитории. Выйдя на высокие позиции в выдаче по подсказкам с брендом, вы улучшите доверие потенциальных клиентов.
- Мнение независимого эксперта. Интернет-пользователи воспринимают подсказки «Яндекса», как рекомендацию независимого эксперта. Они считают, раз поисковая система показывает рядом с запросом сайт, значит, он надежный и ему можно доверять.
- Экономия на рекламе и рост качественного трафика. Такой дополнительный трафик из органической выдачи обойдется дешевле, чем полученный посредством сетей контекстной рекламы.
Минусы поисковых подсказок
Трудоемкий процесс. Чтобы регулярно обновлять подсказки в СЯ, приходится тратить много времени и сил на их сбор.
Накрутка запрещена поисковыми системами. Такой способ продвижения относится к запрещенным. Если алгоритмы «поймают» вас, сайт попадет под санкции. К тому же, когда накрутка будет приостановлена, сайт пропадет из подсказок и потеряет трафик.
Искусственные ключевые запросы
Включать в семантическое ядро подсказки нужно осторожно, ведь они могут утратить актуальность или что еще хуже — быть накрученными вашими конкурентами. Таким образом, вы можете не получить то количество трафика, на которое надеялись.
Парсеры сайтов в зависимости от используемой технологии
Парсеры на основе Python и PHP
Такие парсеры создают программисты. Без специальных знаний сделать парсер самостоятельно не получится. На сегодня самый популярный язык для создания таких программ Python. Разработчикам, которые им владеют, могут быть полезны:
- библиотека Beautiful Soup;
- фреймворки с открытым исходным кодом Scrapy, Grab и другие.
Заказывать разработку парсера с нуля стоит только для нестандартных задач. Для большинства целей можно подобрать готовые решения.
Парсеры-расширения для браузеров
Парсить данные с сайтов могут бесплатные расширения для браузеров. Они извлекают данные из html-кода страниц при помощи языка запросов Xpath и выгружают их в удобные для дальнейшей работы форматы — XLSX, CSV, XML, JSON, Google Таблицы и другие. Так можно собрать цены, описания товаров, новости, отзывы и другие типы данных.
Примеры расширений для Chrome: Parsers, Scraper, Data Scraper, kimono.
Парсеры сайтов на основе Excel
В таких программах парсинг с последующей выгрузкой данных в форматы XLS* и CSV реализован при помощи макросов — специальных команд для автоматизации действий в MS Excel. Пример такой программы — ParserOK. Бесплатная пробная версия ограничена периодом в 10 дней.
Парсинг при помощи Google Таблиц
В Google Таблицах парсить данные можно при помощи двух функций — importxml и importhtml.
Функция IMPORTXML импортирует данные из источников формата XML, HTML, CSV, TSV, RSS, ATOM XML в ячейки таблицы при помощи запросов Xpath. Синтаксис функции:
IMPORTXML("https://site.com/catalog"; "//a/@href")
IMPORTXML(A2; B2)
Расшифруем: в первой строке содержится заключенный в кавычки url (обязательно с указанием протокола) и запрос Xpath.
Знание языка запросов Xpath для использования функции не обязательно, можно воспользоваться опцией браузера «копировать Xpath»:
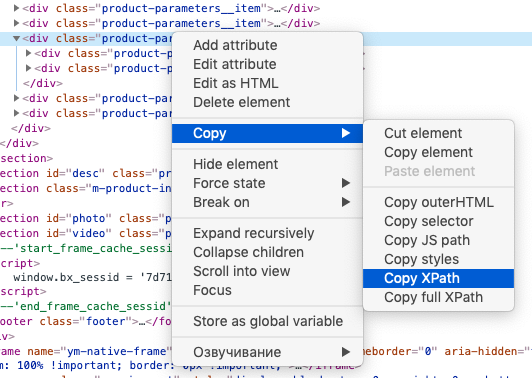
Вторая строка указывает ячейки, куда будут импортированы данные.
IMPORTXML можно использовать для сбора метатегов и заголовков, количества внешних ссылок со страницы, количества товаров на странице категории и других данных.
У IMPORTHTML более узкий функционал — она импортирует данные из таблиц и списков, размещенных на странице сайта. Синтаксис функции:
IMPORTHTML("https://https://site.com/catalog/sweets"; "table"; 4)
IMPORTHTML(A2; B2; C2)
Расшифруем: в первой строке, как и в предыдущем случае, содержится заключенный в кавычки URL (обязательно с указанием протокола), затем параметр «table», если хотите получить данные из таблицы, или «list», если из списка. Числовое значение (индекс) означает порядковый номер таблицы или списка в html-коде страницы.
Зачем нужен парсинг подсветок?
Парсер подсветок – крайне полезная вещь. Она позволяет узнать, какие слова из сниппетов в выдаче поисковая машина подсвечивает по конкретным поисковым запросам. По сути, это автоматизированная альтернатива ручной проверке поисковой выдачи.
Полученные в результате проверки слова можно (и нужно) использовать при формировании сниппетов.
В этой инструкции мы рассмотрим следующий сервис для парсинга, разработанный Александром Арсёнкиным: http://arsenkin.ru/tools/sp/
Как работает Парсинг подсветок Яндекс?
Из названия понятно, что сервис ведет сбор подсветок только из поисковой системы Яндекс.
Функционал сервиса очень прост, а интерфейс лаконичен и интуитивно понятен.
Сервис парсит первые 50 результатов выдачи Яндекс. Этого вполне достаточно.
За один раз можно загрузить 50 ключей. Но лучше проверять каждое ключевое слово по очереди, т.к. посмотреть результаты для каждого нет возможности (результат выводится единым столбцом).
Опция “Убрать спектр”.
Спектр умеет автоматически собирать, распознавать, анализировать и группировать поисковые запросы. И если спектр распознает запрос как коммерческий, он добавляет к нему слова “купить”, “цена”, “каталог”, “фото”, “выбрать” и т.п. Если они вас не интересуют, поставьте галочку возле опции “Убрать спектр”.
Узнать больше о технологии Спектр можно тут: https://yandex.ru/company/technologies/spectrum/.
Естественно, сервис требует задать регион. Из выпадающего списка предлагается выбрать страну, область, город.
Но все это, опять-таки, подается единым списком без какой-либо закономерности, что не очень удобно. Поэтому проще регион задавать вручную.
В результате парсинга сервис выдает подсвечиваемые слова, включая используемые для коммерческих запросов (“купить”, “цена” и т.д.), регион и синонимы из своей базы.
Пример
Нас интересует, какие слова из сниппетов Яндекса подсвечены для поискового запроса “чайный сервиз” по региону Уфа.
Вводим ключевое слово, Спектр не убираем, задаем регион, нажимаем кнопку “Найди мне подсветки”.
Сбор результатов занимает секунды. На выходе получаем три таблицы.
-
Таблица “Результат подсветки”.
Вкладка “Подсветки”:
Как видим, слова из запроса в точной форме сервис решил не собирать, о чем он нас предупреждает.
Вкладка “Лемматизированные”:
-
Таблица “Лемматизированные слова из запросов”:
-
Таблица “Слова, задающие тематику (лемматизированные)” .
Вкладка “Слова”:
Вкладка “Скопировать”:
Кнопка “Копировать в буфер” на нажатие не реагирует.
Если поставить галочку возле “Убрать спектр”, результаты подсветки изменятся:
Результаты в таблице “Слова, задающие тематику (лемматизированные)” также поменяются.
Вывод
Парсинг подсветок Яндекс позволяет быстро собирать разные слова из сниппетов, которые Яндекс подсвечивает, а значит, которые нравятся его поисковой машине. И это может очень пригодиться при формировании собственных сниппетов.
Метод для получения максимального охвата
Этап 1: соберите общие фразы, которые описывают ваш продукт
Ответьте на вопрос, как его называет ЦА. Придумайте все возможные формулировки, написания (в том числе русские для зарубежных брендов) и синонимы.
Можно взять их из описания сегментов целевой аудитории. В нашем примере — семантика для курсов английского языка, сегмент «Карьеристы».
Примерные запросы для этого типа ЦА:
- «Деловой английский курсы»;
- «Бизнес английский»;
- «Карьера в зарубежной фирме»;
- «Английский для работы»;
- «Деловой английский по скайпу»;
- «Курсы английского с сертификатом»;
- «Английский интенсивный курс».
Постройте таблицу в любом формате, чтобы фиксировать идеи. Занесите то, что есть на данный момент:
Это удобный формат отчета: всё сгруппировано по темам, брендам, категориям, проще оценивать общую частотность и в дальнейшем — размер низкочастотного хвоста.
Столбец «Семантика» — это количество уникальных фраз с ненулевой частотностью для этой маски. Его мы заполняем далее — на этапе парсинга СЯ. Сейчас только выписываем частотность из Яндекс Wordstat.
Столбец «Раздел» пригодится, если у вас много товаров, брендов, категорий.
Этап 2: пробейте фразы в Wordstat
Используйте только широкое соответствие, чтобы получить по максимуму вложенные запросы из каждого базиса.
Сервис выдает количество показов рекламных блоков Яндекса. Чем уже запрос, тем меньше предполагаемое количество запросов и трафика на сайт, а следовательно — охвата ЦА.
Не забудьте настроить регион, если у вас локальный бизнес.
Фразы с очень низкими показателями лучше заменить на более емкие, так как ваша задача — получить маски, которые потенциально дают большое количество расширений при дальнейшем парсинге.
При этом исключайте варианты с нулевой частотностью:
Можно их также уточнить, чтобы получить больший прогнозируемый охват
Но учитывайте, что при этом в выдаче могут появиться нецелевые запросы, например:
Желательно сразу вносить их в минус-файл либо исключить при поиске:
Важно! Оценивайте результаты выдачи сразу, чтобы в дальнейшем избежать лишней работы. Если в выборке много лишнего, не стоит брать этот базис.
Например, запрос «Английский для работы» дает не те результаты, которые нужны для СЯ
Мы подразумевали под работой карьеру, но не как школьное задание.
В нашем случае всё, что связано со школой — «контрольная работа», «домашняя работа», «по-английски», «рабочая тетрадь» и т.д. — это минус-слова.
Пробуем уточнить формулировку. Совсем другая ситуация по фразе «Английский для работы за рубежом», но выдача маленькая.
Принцип №1: для полноценного СЯ подбирайте такие маски, чтобы «зацепить» больше расширений (охвата) и меньше «мусора».
По мере парсинга масок в Wordstat заполняйте таблицу. У нас получаются такие данные:
Результаты довольно скромные, если пользоваться только выдачей Wordstat. За счет чего их можно расширить? Идем дальше.
Этап 3: посмотрите похожие запросы в Яндекс Wordstat
Принцип №2: используйте ключевые фразы в правом столбце как идеи, а не просто копируйте. Выделяйте из них полезные составляющие, расширяйте их как угодно, убирайте лишние слова.
Параллельно проверяйте каждую идею на содержание в поисковиках, чтобы представлять, какие запросы по нему вводят:
И отсеивайте то, что не попадает в тему.
Этап 4: изучите источники семантики
Принцип тот же — придумывайте маски из того, что увидите. Например, загляните в:
Поисковые подсказки Яндекс и Google:
Похожие запросы в SERP:
Статистику запросов Mail.ru
А также сервисы синонимов, форумы, Alt-теги к картинкам в поисковой выдаче, Планировщик ключевых слов Google и т.д.
Полезно черпать идеи с сайтов конкурентов.
Отдельно пара слов о сервисе SpyWords. Это не буквальное руководство. База запросов, по которой раз в месяц снимается поисковая выдача и реальные запросы — это разные вещи. Копировать их бессмысленно, а поискать идеи для новых масок стоит.
Рекомендация та же: проверяйте результаты в поисковой выдаче. Плюс пробивайте на частотность в Яндекс Wordstat.
Заносите в таблицу те, где частотность выше нуля. Вот некоторые маски, которые мы получили из похожих запросов и поисковых подсказок:
Парсеры сайтов по способу доступа к интерфейсу
Облачные парсеры
Облачные сервисы не требуют установки на ПК. Все данные хранятся на серверах разработчиков, вы скачиваете только результат парсинга. Доступ к программному обеспечению осуществляется через веб-интерфейс или по API.
Примеры облачных парсеров с англоязычным интерфейсом:
- http://import.io/,
- Mozenda (есть также ПО для установки на компьютер),
- Octoparce,
- ParseHub.
Примеры облачных парсеров с русскоязычным интерфейсом:
- Xmldatafeed,
- Диггернаут,
- Catalogloader.
У всех сервисов есть бесплатная версия, которая ограничена или периодом использования, или количеством страниц для сканирования.
Программы-парсеры
ПO для парсинга устанавливается на компьютер. В подавляющем большинстве случаев такие парсеры совместимы с ОС Windows. Обладателям mac OS можно запускать их с виртуальных машин. Некоторые программы могут работать со съемных носителей.
Примеры парсеров-программ:
- ParserOK,
- Datacol,
- SEO-парсеры — Screaming Frog, ComparseR, Netpeak Spider и другие.
Сбор частот
Сбор частот позволяет оценить популярность запросов.
Сервис выдает кол-во показов запроса за последние 30 дней.
Статистика обновляется не ежедневно, поэтому не воспринимайте этот период буквально.
Сервис поддерживает различные операторы поиска, поэтому программа способна получать несколько видов частот.
Программа автоматически добавляет нужные операторы при сборе того или иного вида частот (добавлять операторы вручную к текст запросов не требуется).
Базовая частота
Базовая частота соответствует широкому типу вхождения слов. Для выполнения запроса достаточно отправить сам запрос в исходном виде:
- свежий хлеб
- условная вероятность
- теорема Байеса
В результатах могут быть учтены и другие фразы, косвенно относящиеся к запросу «свежий хлеб» в широком соответствии: купить свежий хлеб, свежий ржаной хлеб, рецепт хлеба, свежая выпечка и др.
Фразовая частота
Фразовая частота фиксирует состав слов в искомом запросе, и показы считаются для словосочетания целиком. Для выполнения запроса необходимо добавить двойные кавычки:
- «свежий хлеб»
- «теорема Байеса»
- «плотность распределения»
В результатах к запросу «свежий хлеб» будут учтены только фразы с тем же набором слов:: свежий хлеб, хлеба свежего и др.
Точная фразовая частота
Точная фразовая частота фиксирует не только состав, но и словоформы слов в искомом запросе. Для выполнения запроса необходимо добавить оператор ! перед каждым словом в запросе и взять его в двойные кавычки:
- «!свежий !хлеб»
- «!теорема !Байеса»
- «!плотность !распределения»
В результатах к запросу «!свежий хлеб!» будут учтены только фразы с тем же набором слов в той же словоформе: свежий хлеб, хлеб свежий (порядок не фиксируется).
Точная фразовая частота с порядком
Точная фразовая с порядком частота фиксирует состав, словоформы и порядок следования слов в искомом запросе. Для выполнения запроса необходимо добавить оператор ! перед каждым словом в запросе, взять его в и двойные кавычки:
- «!свежий !хлеб»
- «!теорема !Байеса»
- «!плотность !распределения»
В результатах к запросу «!свежий хлеб!» будут учтены только фразы с тем же набором слов в той же словоформе и том же порядке следования: свежий хлеб.
Частота по маске
Вы можете самостоятельно определить маску запроса, используя поддерживаемые сервисом операторы.
Маска запроса должна содержать фрагмент QUERY, который при сборе частот будет заменяться на текст исследуемого запроса.
Оффлайн парсеры
Возможность парсинга Яндекс Вордстат без доступа к интернету или при его низкой скорости – одно из требований к современным инструментам СЕО анализа. Технически это реализовано просто – на компьютер или аналогичное устройство, скачивается базы Wordstat и затем с помощью программы происходит выборка ключевых слов.
Букварикс десктопная версия
Впервые полноценный десктопный вариант представили разработчики «Букварикс». Однако уже в октябре 2017 года этот проект был «заморожен», ПО и базы данных не обновляются. Компания предлагает все инструменты в онлайн-режиме. Скачать приложение можно на старой версии официального сайта, использование бесплатное.
Что нужно учитывать при использовании десктопной версии:
- скачиваемый объем – около 30 Гбайт;
- скачать можно только с Яндекс.Диска, состоит из 20 частей;
- последняя дата обновления БД – 1 октября 2017 г.
Информация в этой версии устарела, возможно использование как вспомогательного инструмента.
Для чего нужен парсинг частотности
Оценка объема трафика по определенным ключевым словам
Частотность в Яндекс.Вордстат отображает количество показов по выбранному ключевому слову за месяц в определенном регионе. С помощью этих данных можно примерно рассчитать потенциальный объем трафика, который можно получать в поисковой выдаче на разных позициях.
Сделать это можно так:
1. Соберите целевую семантику (список ключевиков, по которым вам нужно получать поисковой трафик). Собрать семантику можно с помощью медиапланера от Click.ru.
2. Спарсите частотность ключевых слов. Для примера мы возьмем ключевик «купить Samsung Galaxy в Москве» и проверим его частотность непосредственно в Вордстате. Итого, по данному запросу – 11757 показов в месяц.
3. Найдите в интернете средние значения CTR для каждой из позиций первой страницы поисковой выдачи.
Если ваш сайт добавлен в Яндекс.Вебмастер и работает как минимум несколько месяцев, данные по CTR будут доступны в отчете «Поисковые запросы» → «Все запросы и группы».
К примеру, CTR для второй позиции – 18%. Теперь мы можем посчитать примерный уровень трафика, который можем получить. Формула для расчета:
(Частотность * CTR)/100
Подставляем в формулу наши данные: (11 757 * 18)/100 = 2116.
Конечно, нет гарантии, что мы получим точно такое количество посещений, но для примерной оценки потенциала запроса такие расчеты будут очень полезными.
Еще одна причина для сбора частотности ключей – фильтрация запросов с околонулевой частотностью
Фразы, по которым нет показов (или показов совсем мало – от 1 до 10), лучше убрать из семантического ядра и не тратить время на оптимизацию страниц под такие запросы.
По ним практически не будет трафика, а если запускать контекстную рекламу, объявления получат статус «мало показов» и не будут показываться.
Обратите внимание! Иногда семантику с низкой частотностью не нужно исключать из ядра. Это касается узкоспециализированных тематик, например дорогого медицинского или производственного оборудования
Там ключевые запросы с указанием точной спецификации оборудования могут иметь всего пару запросов в месяц, но приводить максимально целевую и горячую аудиторию.
На что ориентироваться
В зависимости от ниши и типа сайта нижний порог частотности, по которому нужно отсекать бесперспективные запросы, отличается. Для ориентира можете использовать следующие данные:
|
Ниша |
Отсеиваем запросы с частотностью |
|
Узкие тематики |
|
|
Масс-маркет |
до 5 |
|
Информационные ресурсы |
до 30–35 |
При удалении низкочастотных фраз будьте внимательны: НЧ-запросы приводят качественный трафик, поэтому удаляйте фразы аккуратно, оставляя целевые.
Кому и зачем нужны парсеры сайтов
Парсеры экономят время на сбор большого объема данных и группировку их в нужный вид. Такими сервисами пользуются интернет-маркетологи, вебмастера, SEO-специалисты, сотрудники отделов продаж.
Парсеры могут выполнять следующие задачи:
Кому и для каких целей требуются парсеры, разобрались. Если вам нужен этот инструмент, есть несколько способов его заполучить.
- При наличии программистов в штате проще всего поставить им задачу сделать парсер под нужные цели. Так вы получите гибкие настройки и оперативную техподдержку. Самые популярные языки для создания парсеров — PHP и Python.
- Воспользоваться бесплатным или платным облачным сервисом.
- Установить подходящую по функционалу программу.
- Обратиться в компанию, которая разработает инструмент под ваши нужды (ожидаемо самый дорогой вариант).
С первым и последним вариантом все понятно. Но выбор из готовых решений может занять немало времени. Мы упростили эту задачу и сделали обзор инструментов.
Как собирать маски ключевых слов
Каждый, кто составлял список базисов, понимает основные сложности:
- Придумать все варианты из головы нереально — мы многое упускаем и теряем охват;
- Ни один даже самый идеальный сервис не подбирает на 100% корректные маркеры — без ручной чистки «мусорных» запросов не обойтись.
Мы применим подход, который дает охват, близкий к 100%. Принцип, как у всех семантических инструментов:
1) Задаете в Wordstat слово / фразу и получаете выборку;
2) Минусуете всё нерелевантное и некоммерческое;
3) Расширяете список за счет похожих фраз и других источников;
4) Проверяйте частотность полученных фраз в Вордстате.
Довольно трудозатратный процесс, но он позволяет достичь оптимального сочетания усилий и охвата.
Итак, всё по порядку. Пример — курсы английского языка.
REGEXEXTRACT — извлекаем нужный текст из ячеек
Эта функция позволяет извлечь из строки с данными текст, описанный с помощью регулярных выражений RE2, поддерживаемых Google. Синтаксис регулярных выражений достаточно сложный, больше примеров вы найдете в справке Google.
Синтаксис:
Пример 1. У нас есть список URL. Нужно извлечь домены. Здесь нам поможет регулярное выражение:
Пример 2. В списке ключевых фраз нужно найти брендированные ключи со словами «porta» и «порта». Для поиска фраз с вхождением любого из этих слов используем регулярное выражение:
Как видите, в таблицах можно кроить и резать данные так, как вам будет нужно, достаточно разобраться в формулах.
SUBSTITUTE — меняем/удаляем пробелы и спецсимволы
Универсальная функция замены/удаления символов в ячейках.
Синтаксис:
Номер соответствия — порядковый номер встреченного значения на замену, например, первое встреченное заменить, остальные оставить. Опциональный параметр.
Пример. У нас есть выгрузка ключевых фраз из Яндекс.Вордстат. Многие ключи содержат плюсики. Нам нужно их удалить.
Формула будет иметь вид:
Что мы сделали:
- где искать — указали ячейку с данными;
- «что искать» — указали плюсик, который нужно удалить;
- «на что менять» — поскольку символ нужно удалить, мы указали кавычки без символов внутри; если бы нам нужна была замена, здесь бы мы прописали текст, на который нужно заменить плюсик;
- номер соответствия — здесь мы ничего не указали, и функция удалит все плюсы в фразе; если бы мы указали 1, то функция удаляла бы только первый плюсик, если 2 — второй и т. д.
Расширения для браузера Яндекс Wordstat
Использовать Яндекс Wordstat по старинке, то есть копипастить подходящие запросы – вчерашний день. Использование бесплатных расширений для браузера дает гораздо больше возможностей.
Рассмотрим основные из них на примере плагина Wordstat Assistant. После установки его панель управления находится в левой области страницы Яндекс Wordstat.
Итак, плагины Вордстата позволяют:
1) Формировать собственный список ключей, отбирая из выдачи Вордстата нужные в пару кликов.
Знаком «+» около каждого результата вы добавляете фразу в свой список. Кликом по кнопке «Добавить все» – все фразы со страницы выдачи, на которой сейчас вы находитесь:
Удалить фразы можно из результатов поиска Яндекс Wordstat (1) или прямо из панели управления (2). Либо крестиком вверху панели управления (3), если нужно очистить весь список:
2) Видеть автоматически рассчитанное количество фраз и частотность по списку благодаря встроенным счетчикам;
3) Добавлять собственные ключи:
Правда, частотность для них не подтягивается из данных Вордстата, а обозначается знаком вопроса.
4) Сортировать список ключей по частотности, алфавиту и порядку добавления.
5) Сохранять список в аккаунте Яндекса и редактировать при повторном открытии.
Более сложный плагин – WordStater. Он поддерживает все базовые функции, плюс свои уникальные вещи.
WordStater включает три вкладки:
1) Общий список из результатов Wordstat;
2) Список минус-слов;
3) Без минусов и дублей – список фраз, отфильтрованный от минус-слов.
В верхней строке плагина вы видите общее количество собранных фраз (1) и можете найти конкретную фразу в списке (2):
Теперь – об уникальных возможностях WordStater, связанных со сбором семантики.
1) Полуавтоматический сбор – с помощью специальных горячих клавиш:
- Ctrl+Shift+A – для добавления ключей с текущей страницы;
- Ctrl+Shift+(стрелка вправо) – со следующей, и т.д.
Так вы быстрее соберете много фраз, однако есть риск «схватить» за это капчу.
2) Исключение из выдачи Вордстата ранее минус-слов, заданных вручную или собранных из выдачи.
Активируйте минусацию, откройте вкладку «Сбор минус-слов»:
Или исключите слова прямо в выдаче Вордстата:
3) Генерация ключевых фраз в «Комбинаторе слов»:
Работает она по принципу перемножения:
Подробнее об этих и других возможностях расширений Яндекс Вордстат смотрите здесь.
Поиск «фейловых» ключей (тепловая карта позиций)
Этот инструмент от JSVXC похож на предыдущий, но решает другую задачу. Он помогает найти «фейловые» запросы, по которым сайт недополучает трафик. Фишка инструмента — тепловая карта. С ней удобно ориентироваться в большой массе запросов.
«Фейловыми» можно условно назвать запросы, по которым сайт занимает позиции с 10 по 100. Содержимое сайта обычно релевантно таким запросам, но по какой-то причине поисковики не выводят его в ТОП-10 (проблемы с контентом, внутренней оптимизацией, недостаточный авторитет сайта).
Что нужно для использования тепловой карты:
- создать копию шаблона Content Gap Finder;
- установить дополнение для Google Sheets Search Analytics for Sheets (если вы его установили при работе с предыдущим шаблоном, то повторная установка не требуется);
- иметь доступ к аккаунту в Search Console с данными хотя бы за пару месяцев.
Вначале настраиваем выгрузку данных из Search Console:
- открываем скопированный шаблон и запускаем дополнение Search Analytics for Sheets;
- выбираем сайт, период выгрузки данных, в поле «Group By» указываем «Query» и «Page», в поле «Results Sheet» — «RAW Data»;
Переходим на лист «Content Gaps». Ключи сгруппированы по страницам. По каждому из них отражено количество кликов, показов, CTR и средняя позиция. Цветовая маркировка (тепловая карта) помогает увидеть общую картину и быстро находить нужные ключи.
Таким образом, мы сразу видим, по каким запросам можно «подтянуть» позиции. Как — другой вопрос. Например, недавно мы рассказывали, как отсеошить старый контент и нарастить более чем в 2 раза трафик из SERP.
Возможности Парсера и его преимущества
Парсер Wordstat позволяет быстро собрать частотность для отдельных фраз или целого семантического ядра. Вот, что можно сделать с помощью инструмента:
- собрать частотность по Wordstat для неограниченного количества фраз;
- загрузить списком или файлом фразы для парсинга частотности;
- собрать частотность по любому региону, поддерживаемому Яндексом;
- собрать частотность только по фразам в определенном виде (с фиксированным порядком слов или словоформами), используя типы соответствия (операторы « », ! и ).
Главные преимущества:
- нет лимитов по количеству запросов: за один раз можно спарсить любое количество запросов (хоть 100, хоть 100 тысяч);
- весь парсинг выполняется на стороне сервиса. Вам не нужно опасаться бана личного аккаунта в Яндексе или создавать фейковые аккаунты под парсинг;
- при использовании Парсера не нужно применять прокси и вводить капчу;
- данные по частотности можно просуммировать по всем регионам или вывести отдельно по каждому региону. В этом случае вы фактически получаете отдельный отчет для каждого региона;
- парсинг работает «в облаке» – нет необходимости загружать ПО и устанавливать на компьютер, не нужно держать вкладку или браузер открытыми. Отчеты также сохраняются «в облаке» и доступны в любое время;
- готовый отчет формируется в формате XLSX-файла. С ним удобно работать, можно импортировать в Google Таблицы, если для вас они более привычны, чем Excel.
Как пользоваться парсером подсказок от Click.ru: пошаговая инструкция
1 Зарегистрируйтесь на Click.ru и перейдите на страницу парсера.
2 Добавьте запросы из эксель-файла или вставьте их списком.
Этап загрузки запросов
3 Выберите нужную поисковую систему и настройте региональность.
Выбор поисковых систем и управление регионами
4 Выберите способы сбора подсказок.По умолчанию подсказки собираются только по заданным запросам. Если нужно собрать семантическое ядро по максимуму, то следует включить дополнительные опции: перебор и/или и/или .
Просто подсказки по запросуА это подсказки по запросу + первая буква алфавита. Большая разница
5 Укажите глубину сбора.
Если оставить первую глубину, то будут собраны подсказки по умолчанию + подсказки, полученные в результате автоподстановок и/или и/или . Если же включить вторую глубину, то вы также получите дополнительные подсказки, собранные по всем словам и фразам первого результата.
Процесс выбора способа и глубины сбора подсказок
6. Запустите проверку.По окончании парсинга отчет можно будет изучить в интерфейсе Click.ru или же скачать на компьютер в эксель-формате.
Стоимость сбора подсказок зависит от количества ТЗ (внутренняя валюта Click.ru). 1 ТЗ — это сбор подсказок в 1 поисковой системе в 1 регионе по 1 фразе. Чтобы сначала попробовать инструмент, платить ничего не надо, так как при регистрации в Click.ru в подарок дается 50 ТЗ.