Основные методы строк
Содержание:
- Удаление элементов
- str-split()
- Ссылки
- STRING_SPLIT and JOIN:
- ОПЕРАТОРЫ УНАРного и БИНАРного разделенияUNARY and BINARY SPLIT OPERATORS
- preg_match()
- Конспект:
- Массивы в JavaScript
- Описание
- ПримерыEXAMPLES
- Accessing Characters
- Комментарии
- Расширенные строковые функции Python
- Класс StringTokenizer
- СинтаксисSyntax
- Python f-строки: особенности использования
- JavaScript
- Заключение
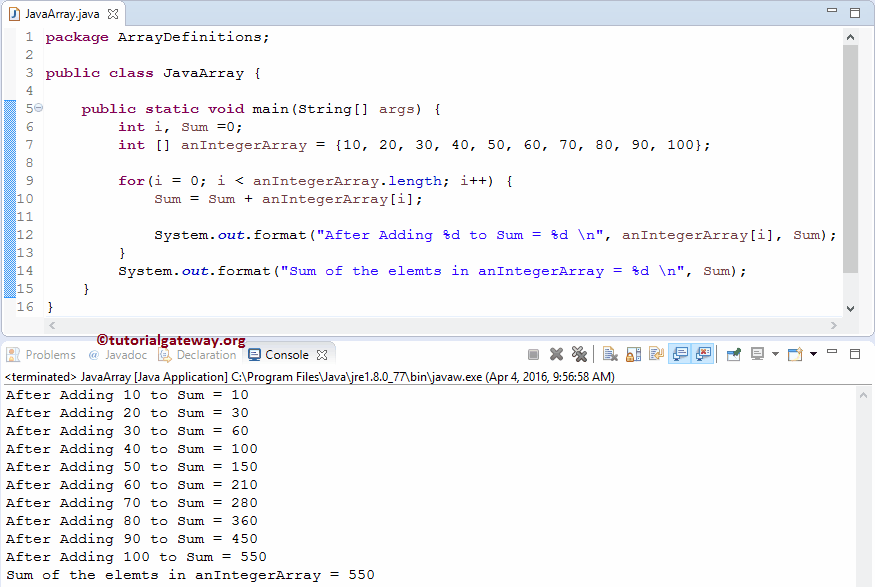
Удаление элементов
Чтобы удалить элементы, введите элемент, с которого нужно начать (index) и количество элементов, которые нужно удалить (number of elements):
array.splice(index, number of elements);
Параметр Index — это начальная точка удаления элементов. Элементы с порядковым номером меньше заданного параметра Index не будут удалены:
array.splice(2); // Every element starting from index 2, will be removed
Если не указать второй параметр, все элементы от заданного параметра Index и до конца будут удалены:
only index 0 and 1 are still there
В качестве еще одно примера, я указал 1 в качестве второго параметра: таким образом, каждый раз при повторе метода splice ( ) будет удалять по одному элементу, начиная со второго:
array.splice(2, 1);
Массив до метода splice ( )
Splice ( ) применен один раз:
Элемент 3 удален: следовательно, теперь элемент “hello world” имеет порядковый номер 2
Splice ( ) применен два раза:
На этот раз, был удален элемент “hello world”, потому что его порядковый номер 2
Так можно продолжать до тех пор, пока не останется элементов с порядковым номером 2.
str-split()
Функция str-split() может быть использована в приведенной выше функции для преобразования строки в массив. str-split () не разбивает строку до целого слова. С ее помощью PHP обрезает последний символ в строке ровно до 120 знаков.
/*
str-split()
http://php.net/manual/en/function.str-split.php
*/
function internoetics_truncate_split($string, $length, $trimmarker = '...') {
$lines = str_split($string, $length - strlen($trimmarker));
$line = rtrim($lines);
$result = ($lines != '') ? $line . $trimmarker : $line;
return $result;
}
/* Использование */
echo internoetics_truncate_split($string, 120);
Ссылки
Многобайтные кодировки и связанные с ними вопросы очень сложны.
Невозможно рассмотреть их здесь достаточно подробно. Дополнительно просмотрите следующие ресурсы.
-
Unicode/UTF/UCS/etc
http://www.unicode.org/
-
информация о символах Japanese/Korean/Chinese
ftp://ftp.ora.com/pub/examples/nutshell/ujip/doc/cjk.inf
- mb_convert_case — Perform case folding on a string
- mb_convert_encoding — конвертирует кодировку символов
- mb_convert_kana — конвертирует «kana» из одной в другую («zen-kaku» ,»han-kaku» и другие)
- mb_convert_variables — конвертирует код символа в переменной(-ых)
- mb_decode_mimeheader — декодирует строку в поле MIME header
- mb_decode_numericentity — декодирует HTML-ссылку на числовую строку в символ
- mb_detect_encoding — определяет кодировку символов
- mb_detect_order — устанавливает/получает порядок определения кодировки символов
- mb_encode_mimeheader — кодирует строку для MIME header’а
- mb_encode_numericentity — кодирует символ в HTML-ссылку на числовую строку
- mb_ereg_match — совпадение с регулярным выражением для многобайтной строки
- mb_ereg_replace — замещает регулярное выражение многобайтной поддержкой
- mb_ereg_search_getpos — возвращает стартовую точку следующего совпадения регулярного выражения
- mb_ereg_search_getregs — запрашивает результат из последнего совпадения многобайтного регулярного выражения
- mb_ereg_search_init — настраивает строку и регулярное выражение для совпадения с регулярным выражением
- mb_ereg_search_pos — возвращает позицию и длину совпавшей части многобайтного регулярного выражения для предопределённой многобайтной строки
- mb_ereg_search_regs — возвращает совпавшую часть многобайтного регулярного выражения
- mb_ereg_search_setpos — устанавливает стартовую точку следующего совпадения регулярного выражения
- mb_ereg_search — совпадение многобайтного регулярного выражения для предопределённой многобайтной строки
- mb_ereg — совпадение с регулярным выражением, с многобайтной поддержкой
- mb_eregi_replace — заменяет регулярное выражение с многобайтной поддержкой, игнорируя регистр
- mb_eregi — совпадение с регулярным выражением, игнорируя регистр, с многобайтной поддержкой
- mb_get_info — получает внутренние настройки mbstring
- mb_http_input — определяет кодировку символов HTTP-ввода
- mb_http_output — устанавливает/получает кодировку символов HTTP-вывода
- mb_internal_encoding — устанавливает/получает внутреннюю кодировку кодировку символов
- mb_language — устанавливает/получает текущий язык
- mb_list_encodings — возвращает массив всех поддерживаемых кодировок
- mb_output_handler — Callback-функция конвертирует кодировку символов в буфере вывода
- mb_parse_str — разбирает GET/POST/COOKIE данные и устанавливает глобальную переменную
- mb_preferred_mime_name — получает строку MIME charset
- mb_regex_encoding — возвращает текущую кодировку для многобайтного regex как строку
- mb_regex_set_options — Устанавливает/Получает опции по умолчанию для функций mbregex
- mb_send_mail — отправляет кодированную mail
- mb_split — делит многобайтную строку с использованием регулярного выражения
- mb_strcut — получает часть строки
- mb_strimwidth — получает усечённую строку специфицированной ширины
- mb_strlen — получает длину строки
- mb_strpos — находит позицию первого вхождения строки в строке
- mb_strtolower — приводит строку к нижнему регистру
- mb_strtoupper — приводит строку к верхнему регистру
- mb_strrpos — находит позицию последнего вхождения строки в строке
- mb_strwidth — возвращает ширину строки
- mb_substitute_character — устанавливает/получает замещающий символ
- mb_substr_count — Считает число вхождений подстроки
- mb_substr — получает часть строки
STRING_SPLIT and JOIN:
We can combine the function result set to the other table with the JOIN clause.
|
1 |
USEAdventureWorks2014 GO PersonType ,NameStyle ,FirstName ,MiddleName ,LastName FROMPerson.PersonP INNERJOINstring_split(‘Ken,Terri,Gail’,’,’) onP.FirstName=value |
Also, we can use CROSS APPLY function to combine the STRING_SPLIT function result set with other tables. CROSS APPLY function provides us to join table value function output to other tables.
In the following sample, we will create two tables and first table (#Countries) stores name and the continent of countries and second table (#CityList) stores city of countries table but the crucial point is #CityList table stores the city names as a string array which is separated by a comma. We will join this to the table over country columns and use the CROSS APPLY function to transform city array into a column. The below image can illustrate what will we do.
|
1 |
DROPTABLEIFEXISTS#Countries GO DROPTABLEIFEXISTS#CityList GO CREATETABLE#Countries (ContinentVARCHAR(100), CountryVARCHAR(100)) GO CREATETABLE#CityList (CountryVARCHAR(100), CityVARCHAR(5000)) GO INSERTINTO#Countries VALUES(‘Europe’,’France’),(‘Europe’,’Germany’) INSERTINTO#CityList VALUES(‘France’,’Paris,Marsilya,Lyon,Lille,Nice’),(‘Germany’,’Berlin,Hamburg,Munih,Frankfurt,Koln’) SELECT CN.Continent,CN.Country,value FROM#CityListCLCROSSAPPLYstring_split(CL.City,’,’)INNERJOIN #CountriesCNONCL.Country=CN.Country DROPTABLEIFEXISTS#Countries GO DROPTABLEIFEXISTS#CityList GO |
ОПЕРАТОРЫ УНАРного и БИНАРного разделенияUNARY and BINARY SPLIT OPERATORS
Оператор унарного разбиения ( ) имеет более высокий приоритет, чем запятая.The unary split operator () has higher precedence than a comma. В результате, если отправить разделенный запятыми список строк в оператор унарного разбиения, то разбиение выполняется только на первую строку (перед первой запятой).As a result, if you submit a comma-separated list of strings to the unary split operator, only the first string (before the first comma) is split.
Чтобы разделить более одной строки, используйте один из следующих шаблонов:Use one of the following patterns to split more than one string:
- Использование оператора двоичного разделения ( <string[]> -Split <delimiter> )Use the binary split operator (<string[]> -split <delimiter>)
- Заключите все строки в круглые скобкиEnclose all the strings in parentheses
- Сохранить строки в переменной, а затем отправить переменную оператору SplitStore the strings in a variable then submit the variable to the split operator
Рассмотрим следующий пример.Consider the following example:
preg_match()
Вы редко найдете тех, кто предпочитает использовать регулярные выражения, когда есть так много отличных функций PHP. Тем не менее, вот функция, которая обрезает строку до определенного символа в PHP, исходя из заданного количества знаков от начала. В отличие от других функций, описанных выше, эта функция обрезает строку до целого слова.
/* preg-match() http://php.net/manual/en/function.preg-match.php */ function internoetics_preg_string($string, $length, $trimmarker = '...') { $strlen = strlen($string); /* mb_substr добавляет принудительный разрыв в $length, если заданное количество символов не содержит окончания слова (пробела) */ $string = trim(mb_substr($string, 0, $strlen)); if ($strlen > $length) { preg_match('/^.{1,' . ($length - strlen($trimmarker)) . '}b/su', $string, $match); $string = trim($match) . $trimmarker; } else { $string = trim($string); } return $string; } /* Применение */ echo internoetics_preg_string($string, 100, $trimmarker = '...');
Описание функции
Функция принимает три параметра: $string, $length и $trimmarker (многоточие или другие символы, которые добавляются в конце строки).
Строка 7
$strlen = strlen($string);
Первое, что мы делаем, это проверяем длину PHP обрезанной строки после символа. Если строка короче, чем $length, то мы возвращаем эту строку.
Строка 9
$string = trim(mb_substr($string, 0, $strlen));
Функция mb_substr() прерывает строку в $length, если это количество символов не содержит окончания слова (пробела). Если мы передали строку длиною 500 символов и эта строка не содержит пробелов, то будет возвращена вся строка (так как функция preg_match не нашла окончания слова). На данный момент мы обрезаем строку таким образом, и возвращаем ее полностью.
Строки 10, 11, и 12
Если длина нашей строки превышает максимальную длину, определенную в качестве параметра функции, мы выполняем регулярное выражение функции preg_match(), чтобы вернуть часть строки до символа с номером $length, который определяется как конец слова (‘/^.{1,$length}b/s’). Знак периода означает любой символ, кроме символа новой строки (n). Фигурная скобка определяет диапазон, который задает, сколько символов должен PHP обрезать в строке. Таким образом {1,$length} означает от 1 до символа $length. Наконец, b означает, что шаблон будет соответствовать окончанию слова. Мы можем производить поиск только слов целиком по шаблону, который мы предоставили. И в конце s задает поиск всех пробелов.
Так как мы не хотим, чтобы возвращаемая строка превышала длину $length, максимальное количество символов в функции preg_match должно быть равно максимальной длине минус длина $trimmarke.r. Мы должны учитывать это.
Затем мы возвращаем либо усеченную строку, либо исходную строку, если она меньше заданной длины усечения.
Конспект:
Slice ( )
- Копирует элементы из массива
- Возвращает их в новый массив
- Не меняет оригинальный массив
- Нарезает массив с помощью параметров from и until: array.slice (from, until)
- Не включает параметр, заданный в “until”
- Используется и в массивах, и в строках
Splice ( )
- Добавляет и удаляет элементы из массива
- Возвращает массив удаленных элементов
- Меняет массив
- Добавление элементов: array.splice (index, number of elements, element)
- Удаление элементов: array.splice (index, number of elements)
- Используется только в массивах
Split ( )
- Делит строки на подстроки
- Возвращает их в виде массива
- 2 параметра, и оба из них не обязательно указывать: string.split(separator, limit)
- Не меняет оригинальную строку
- Используется только в строках
В JavaScript есть еще много других встроенных методов работы с массивами и строками. Если вы научитесь их использовать, программировать станет намного проще.
Перевод статьи Cem Eygi: Let’s clear up the confusion around the slice( ), splice( ), & split( ) methods in JavaScript
Массивы в JavaScript
Сперва нужно разобраться, как работают массивы JavaScript. Как и в других языках программирования, массивы используются для хранения нескольких единиц данных. Разница в том, что массивы JavaScript могут содержать несколько типов данных одновременно.
Чтобы работать с такими массивами, нам понадобятся JavaScript-методы: например, slice () & splice (). Создать массив можно так:
let arrayDefinition = []; // Array declaration in JS
Теперь создадим другой массив с данными разного типа:
let array = ;
В JavaScript можно создавать массивы с разными типами данных: с числами, строками и логическими значениями.
Описание
Функция Split разбивает строку текста на таблицу с подстроками. Используйте функцию Split, чтобы разбивать списки с разделителями-запятыми, даты с косой чертой, а также другие элементы с четко определенными разделителями.
Строка разделителя используется для разбивки текстовой строки. Разделитель может содержать ноль, один или несколько символов, которые в текстовой строке обрабатываются как одно целое. Если используется пустая строка или строка нулевой длины, будет разделен каждый символ. Соответствующие строки разделители не возвращаются в результатах. Если соответствующий разделитель не найден, вся строка текста возвращается как один результат.
Используйте функцию Concat, чтобы перекомпоновать строку без разделителей.
Используйте функцию MatchAll для разделения строки с помощью регулярного выражения.
Примеры показывают, как можно использовать функцию Split с функциями First и Last для извлечения одной подстроки с разделителями. Функция Match часто является более кратким и мощным выбором для тех, кто знаком с регулярными выражениями.
ПримерыEXAMPLES
Следующая инструкция разделяет строку на пробел.The following statement splits the string at whitespace.
Следующая инструкция разделяет строку на любую запятую.The following statement splits the string at any comma.
Следующая инструкция разделяет строку на шаблоне «ER».The following statement splits the string at the pattern «er».
Следующая инструкция выполняет разбиение с учетом регистра по букве «N».The following statement performs a case-sensitive split at the letter «N».
Следующая инструкция разделяет строку на «e» и «t».The following statement splits the string at «e» and «t».
Следующая инструкция разделяет строку на «e» и «r», но ограничивает результирующие подстроки до шести подстрок.The following statement splits the string at «e» and «r», but limits the resulting substrings to six substrings.
Следующая инструкция разделяет строку на три подстроки.The following statement splits a string into three substrings.
Следующая инструкция разделяет строку на три подстроки, начиная с конца строки.The following statement splits a string into three substrings starting from the end of the string.
Следующая инструкция разделяет две строки на три подстроки.The following statement splits two strings into three substrings.
(Ограничение применяется к каждой строке независимо друг от друга.)(The limit is applied to each string independently.)
Следующая инструкция разделяет каждую строку в строке Here в первой цифре.The following statement splits each line in the here-string at the first digit. Он использует многострочный параметр для распознавания начала каждой строки и строки.It uses the Multiline option to recognize the beginning of each line and string.
0 представляет значение «вернуть все» для параметра max-substring.The 0 represents the «return all» value of the Max-substrings parameter. Параметры, например Multiline, можно использовать, только если указано значение Max-substring.You can use options, such as Multiline, only when the Max-substrings value is specified.
Следующая инструкция использует символ обратной косой черты для экранирования разделителя с точкой (.).The following statement uses the backslash character to escape the dot (.) delimiter.
При использовании значения по умолчанию Режексматч точка, заключенная в кавычки («.»), интерпретируется так, чтобы соответствовать любому символу, кроме символа новой строки.With the default, RegexMatch, the dot enclosed in quotation marks («.») is interpreted to match any character except for a newline character. В результате инструкция Split возвращает пустую строку для каждого символа, кроме новой строки.As a result, the Split statement returns a blank line for every character except newline.
В следующей инструкции используется параметр SimpleMatch для направления оператора-split на интерпретацию разделителя с точкой (.) буквально.The following statement uses the SimpleMatch option to direct the -split operator to interpret the dot (.) delimiter literally.
0 представляет значение «вернуть все» для параметра max-substring.The 0 represents the «return all» value of the Max-substrings parameter. Параметры, такие как SimpleMatch, можно использовать, только если указано значение Max-substring.You can use options, such as SimpleMatch, only when the Max-substrings value is specified.
Следующая инструкция разделяет строку на один из двух разделителей в зависимости от значения переменной.The following statement splits the string at one of two delimiters, depending on the value of a variable.
Accessing Characters
We’re going to demonstrate how to access characters and indices with the string.
Using square bracket notation, we can access any character in the string.
We can also use the method to return the character using the index number as a parameter.
Alternatively, we can use to return the index number by the first instance of a character.
Although “o” appears twice in the string, will get the first instance.
is used to find the last instance.
For both of these methods, you can also search for multiple characters in the string. It will return the index number of the first character in the instance.
The method, on the other hand, returns the characters between two index numbers. The first parameter will be the starting index number, and the second parameter will be the index number where it should end.
Note that is , but is not part of the returned output. will return what is between, but not including, the last parameter.
If a second parameter is not included, will return everything from the parameter to the end of the string.
To summarize, and will help return string values based on index numbers, and and will do the opposite, returning index numbers based on the provided string characters.
Комментарии
По умолчанию или, когда Equals-1, функция разделяет входную строку на каждое вхождение строки разделителя и возвращает подстроки в массиве.By default, or when equals -1, the function splits the input string at every occurrence of the delimiter string, and returns the substrings in an array. Если значение параметра больше нуля, функция разделяет строку по первым 1 вхождениям разделителя и возвращает массив с результирующими подстроками.When the parameter is greater than zero, the function splits the string at the first -1 occurrences of the delimiter, and returns an array with the resulting substrings. Например, возвращает массив , а возвращает массив .For example, returns the array , while returns the array .
Если функция встречает два разделителя в строке или разделитель в начале или в конце строки, он интерпретирует их как окружающую пустую строку («»).When the function encounters two delimiters in a row, or a delimiter at the beginning or end of the string, it interprets them as surrounding an empty string («»). Например, возвращает массив, содержащий три пустые строки: один из между началом строки и первый «x», один из между двумя строками «x», а второй — между последним «x» и концом строки.For example, returns the array containing three empty strings: one from between the beginning of the string and the first «x», one from between the two «x» strings, and one from between the last «x» and the end of the string.
В этой таблице показано, как необязательные Параметры, и могут изменить поведение функции.This table demonstrates how the optional , , and parameters can change the behavior of the function.
| Вызов SplitSplit Call | Возвращаемое значениеReturn Value |
|---|---|
| {«42,» , «12,» , «19»}{«42,» , «12,» , «19»} | |
| {«42», «12», «19»}{«42», «12», «19»} | |
| {«42», «12, 19»}{«42», «12, 19»} | |
| {«192», «168», «0», «1»}{«192», «168», «0», «1»} | |
| {«Алиса и Боб»}{«Alice and Bob»} | |
| {«Алиса», «Bob»}{«Alice», «Bob»} | |
| {«someone@example.com»}{«someone@example.com»} | |
| {«кто», «example.com»}{«someone», «example.com»} |
Аргумент может иметь следующие значения.The argument can have the following values.
| КонстантаConstant | ОписаниеDescription | ЗначениеValue |
|---|---|---|
| Выполняет двоичное сравнениеPerforms a binary comparison | ||
| Выполняет текстовое сравнениеPerforms a textual comparison | 11 |
Расширенные строковые функции Python
| encode() | Используется для возврата закодированных строк | str_name.encode (кодировка = кодировка, ошибки = ошибки) |
| expandtabs() | Для установки или исправления пробелов табуляции между символами или алфавитами | str_name.expandtabs (размер табуляции) |
| format() | Заменяет имя переменной, записанное в {}, значением при выполнении | str_name.format (значение1, значение2 …) |
| format_map() | Для форматирования заданной строки и возвращается | str_name.format_map (отображение) |
| isidentifier() | Проверяет, являются ли символы буквенно-цифровыми буквами (az) и (0-9) или подчеркиванием (_), и возвращает True | str_name.isidentifier() |
| isprintable() | Проверяет, все ли символы доступны для печати, затем возвращает True | str_name.isprintable() |
| istitle() | Проверяет, все ли начальные символы слов в верхнем регистре, затем возвращает True | str_name.istitle() |
| join() | Принимает слова как повторяемые и объединяет их в строку | str_name.join (повторяемый) |
| ljust() | Возвращает выровненную по левому краю строку с минимальным значением, заданным как ширина | str_name.ljust (длина, символ) |
| lstrip() | Удаляет символы с левого края на основе данного аргумента | str_name.lstrip (символы) |
| maketrans() | Создает сопоставленную таблицу, используемую для переводов. | str_name.maketrans (x, y, z) |
| rsplit() | Используется для разделения строки с правого конца | str_name.rsplit (разделитель, maxsplit) |
| rfind() | Ищет указанное значение и находит позицию его последнего значения. | str_name.rfind (значение, начало, конец) |
| rindex() | Ищет указанное значение и находит позицию его последнего значения. | str_name.rindex (значение, начало, конец) |
| rjust() | Возвращает выровненную по правому краю строку с минимальным значением, заданным как ширина | str_name.rjust (длина, символ) |
| rpartition() | Ищет последнее вхождение указанной строки и разбивает строку на кортеж из трех элементов. | str_name.rpartition (значение) |
| rstrip() | Удаляет символы с правого конца на основе заданного аргумента | str_name.rstrip (символы) |
| translate() | Используется для получения переведенной строки | str_name.translate (таблица) |
| zfill() | Он возвращает новую строку с символами «0», добавленными слева в строке. | str_name.zfill (len) |
Класс StringTokenizer
И еще несколько самых частых сценариев работы со строками. Как разбить строку на несколько частей? Для этого есть несколько способов.
Метод
Первый способ разбить строку на несколько частей — использовать метод . В него в качестве параметра нужно передать регулярное выражение: специальный шаблон строки-разделителя. Что такое регулярное выражение, вы узнаете в квесте Java Multithreading.
Пример:
| Код | Результат |
|---|---|
| Результатом будет массив из трех строк: |
Просто, но иногда такой подход избыточен. Если разделителей много, например, «пробел», «enter», «таб», «точка», приходится конструировать достаточно сложное регулярное выражение. Его сложно читать, а значит, в него сложно вносить изменения.
Класс
В Java есть специальный класс, вся работа которого — разделять строку на подстроки.
Этот класс не использует регулярные выражения: вместо этого в него просто передается строка, состоящая из символов-разделителей. Преимущества этого подхода в том, что он не разбивает сразу всю строку на кусочки, а потихоньку идет от начала к концу.
Класс состоит из конструктора и двух методов. В конструктор нужно передать строку, которую мы разбиваем на части, и строку — набор символов, используемых для разделения.
| Методы | Описание |
|---|---|
| Возвращает следующую подстроку | |
| Проверяет, есть ли еще подстроки. |
Этот класс чем-то напоминает класс , у которого тоже были методы и .
Создать объект можно командой:
Где строка — это , которую будем делить на части. А — это строка, каждый символ которой считается символом-разделителем. Пример:
| Код | Вывод на экран |
|---|---|
Обратите внимание, что разделителем считается каждый символ строки, переданный второй строкой в конструктор
СинтаксисSyntax
Split(выражение, ])Split(expression, ]])
Синтаксис функции Split включает следующие :The Split function syntax has these :
| ЧастьPart | ОписаниеDescription |
|---|---|
| выражениеexpression | Обязательная часть.Required. , содержащее подстроки и разделители. containing substrings and delimiters. Если аргумент expression является строкой нулевой длины («»), функция Split возвращает пустой массив — без элементов и данных.If expression is a zero-length string(«»), Split returns an empty array, that is, an array with no elements and no data. |
| delimiterdelimiter | Необязательное свойство.Optional. Строковый символ, используемый для разделения подстрок.String character used to identify substring limits. Если этот аргумент не указан, в качестве разделителя используется знак пробела (» «).If omitted, the space character (» «) is assumed to be the delimiter. Если аргумент delimiter является строкой нулевой длины, возвращается массив с одним элементом, содержащим всю строку из аргумента expression.If delimiter is a zero-length string, a single-element array containing the entire expression string is returned. |
| ограничениеlimit | Необязательное свойство.Optional. Количество возвращаемого подстройки; -1 указывает, что возвращаются все подстройки.Number of substrings to be returned; -1 indicates that all substrings are returned. |
| comparecompare | Необязательно.Optional. Представляет собой числовое значение, указывающее вид сравнения, которое выполняется при оценке подстрок.Numeric value indicating the kind of comparison to use when evaluating substrings. Значения см. в разделе «Параметры».See Settings section for values. |
Python f-строки: особенности использования
Теперь, когда вы узнали все о том, почему f-строки великолепны, я уверен, что вы захотите начать их использовать. Вот несколько деталей, о которых нужно помнить, когда вы отправляетесь в этот дивный новый мир.
Кавычки
Вы можете использовать различные типы кавычек внутри выражений. Просто убедитесь, что вы не используете кавычки того же типа на внешней стороне f-строки, которые вы используете в выражении.
Этот код будет работать:
>>> f"{'Eric Idle'}"
'Eric Idle'
Этот код также будет работать:
>>> f'{"Eric Idle"}'
'Eric Idle'
Вы также можете использовать тройные кавычки:
>>> f"""Eric Idle""" 'Eric Idle'
>>> f'''Eric Idle''' 'Eric Idle'
Если вам нужно использовать одинаковый тип кавычки как внутри, так и снаружи строки, вы можете сделать это с помощью \:
>>> f"The \"comedian\" is {name}, aged {age}."
'The "comedian" is Eric Idle, aged 74.'
Словари
Говоря о кавычках, следите, когда вы работаете со словарями. Если вы собираетесь использовать одинарные кавычки для ключей словаря, то не забудьте убедиться, что вы используете двойные кавычки для f-строк, содержащих ключи.
>>> comedian = {'name': 'Eric Idle', 'age': 74}
>>> f"The comedian is {comedian}, aged {comedian}."
The comedian is Eric Idle, aged 74.
Пример с синтаксической ошибкой:
>>> comedian = {'name': 'Eric Idle', 'age': 74}
>>> f'The comedian is {comedian}, aged {comedian}.'
File "<stdin>", line 1
f'The comedian is {comedian}, aged {comedian}.'
^
SyntaxError: invalid syntax
Если вы используете тот же тип кавычки вокруг ключей словаря, что и на внешней стороне f-строки, то кавычка в начале первого ключа словаря будет интерпретироваться как конец строки.
Фигурные скобки
Чтобы в скобках появилась скобка, вы должны использовать двойные скобки:
>>> f"`74`"
'{74}'
Обратите внимание, что использование тройных скобок приведет к тому, что в вашей строке будут только одиночные скобки:
>>> f"{`74`}"
'{74}'
Тем не менее, вы можете получить больше фигурных скобок, если вы используете больше, чем тройные фигурные скобки:
>>> f"{{`74`}}"
'`74`'
Обратный слеш
Как вы видели ранее, вы можете использовать обратные слэши в строковой части f-строки. Однако вы не можете использовать обратную косую черту для экранирования части выражения f-строки:
>>> f"{\"Eric Idle\"}"
File "<stdin>", line 1
f"{\"Eric Idle\"}"
^
SyntaxError: f-string expression part cannot include a backslash
Вы можете обойти это, предварительно посчитав выражение и используя результат в f-строке:
>>> name = "Eric Idle"
>>> f"{name}"
'Eric Idle'
Выражения не должны содержать комментарии, использующие символ #. Используя это вы получите синтаксическую ошибку:
>>> f"Eric is {2 * 37 #Oh my!}."
File "<stdin>", line 1
f"Eric is {2 * 37 #Oh my!}."
^
SyntaxError: f-string expression part cannot include '#'
JavaScript
JS Array
concat()
constructor
copyWithin()
entries()
every()
fill()
filter()
find()
findIndex()
forEach()
from()
includes()
indexOf()
isArray()
join()
keys()
length
lastIndexOf()
map()
pop()
prototype
push()
reduce()
reduceRight()
reverse()
shift()
slice()
some()
sort()
splice()
toString()
unshift()
valueOf()
JS Boolean
constructor
prototype
toString()
valueOf()
JS Classes
constructor()
extends
static
super
JS Date
constructor
getDate()
getDay()
getFullYear()
getHours()
getMilliseconds()
getMinutes()
getMonth()
getSeconds()
getTime()
getTimezoneOffset()
getUTCDate()
getUTCDay()
getUTCFullYear()
getUTCHours()
getUTCMilliseconds()
getUTCMinutes()
getUTCMonth()
getUTCSeconds()
now()
parse()
prototype
setDate()
setFullYear()
setHours()
setMilliseconds()
setMinutes()
setMonth()
setSeconds()
setTime()
setUTCDate()
setUTCFullYear()
setUTCHours()
setUTCMilliseconds()
setUTCMinutes()
setUTCMonth()
setUTCSeconds()
toDateString()
toISOString()
toJSON()
toLocaleDateString()
toLocaleTimeString()
toLocaleString()
toString()
toTimeString()
toUTCString()
UTC()
valueOf()
JS Error
name
message
JS Global
decodeURI()
decodeURIComponent()
encodeURI()
encodeURIComponent()
escape()
eval()
Infinity
isFinite()
isNaN()
NaN
Number()
parseFloat()
parseInt()
String()
undefined
unescape()
JS JSON
parse()
stringify()
JS Math
abs()
acos()
acosh()
asin()
asinh()
atan()
atan2()
atanh()
cbrt()
ceil()
clz32()
cos()
cosh()
E
exp()
expm1()
floor()
fround()
LN2
LN10
log()
log10()
log1p()
log2()
LOG2E
LOG10E
max()
min()
PI
pow()
random()
round()
sign()
sin()
sqrt()
SQRT1_2
SQRT2
tan()
tanh()
trunc()
JS Number
constructor
isFinite()
isInteger()
isNaN()
isSafeInteger()
MAX_VALUE
MIN_VALUE
NEGATIVE_INFINITY
NaN
POSITIVE_INFINITY
prototype
toExponential()
toFixed()
toLocaleString()
toPrecision()
toString()
valueOf()
JS OperatorsJS RegExp
constructor
compile()
exec()
g
global
i
ignoreCase
lastIndex
m
multiline
n+
n*
n?
n{X}
n{X,Y}
n{X,}
n$
^n
?=n
?!n
source
test()
toString()
(x|y)
.
\w
\W
\d
\D
\s
\S
\b
\B
\0
\n
\f
\r
\t
\v
\xxx
\xdd
\uxxxx
JS Statements
break
class
continue
debugger
do…while
for
for…in
for…of
function
if…else
return
switch
throw
try…catch
var
while
JS String
charAt()
charCodeAt()
concat()
constructor
endsWith()
fromCharCode()
includes()
indexOf()
lastIndexOf()
length
localeCompare()
match()
prototype
repeat()
replace()
search()
slice()
split()
startsWith()
substr()
substring()
toLocaleLowerCase()
toLocaleUpperCase()
toLowerCase()
toString()
toUpperCase()
trim()
valueOf()
Заключение
Мы могли бы написать еще сотни примеров PHP обрезки строк, но когда-то нужно остановиться. Функции, приведенные в этой статье, являются частью ядра PHP, и вы можете использовать их для усечения строк. Хотя чаще всего программисты стараются избегать регулярных выражений, если другого выхода нет, вы можете прибегнуть и к их помощи.
В ряде примеров мы вернули $trimmarker, представляющий собой многоточие. При необходимости вы можете вернуть HTML-объект Ellipsis, для этого используется код …. Но лично я предпочитаю многоточие.
Скачать примеры
Скачать примеры из этой статьи вы можете здесь.
Данная публикация является переводом статьи «Truncate (Shorten) Strings to the Nearest Whole Word or Character Count with Trailing Dots using PHP Functions» , подготовленная редакцией проекта.