Галопом по основам regex
Содержание:
- preg_grep()
- 2 Практический раздел. Ссылки
- WordPress: Using Regexp to Retrieve Images From a Post
- Метасимволы
- Алгоритм[править]
- Специальные конструкции в регулярках
- preg_match()
- МетаСимволы
- Регулярные выражения PHP
- Отличие «preg_match» от «preg_match_all»
- Задачка на проверку телефонов
- Скобочные группы ― ()
- Использование нумирации в заменах и другие продвинутые возможности
- Строковые методы, поиск и замена
- Операторы повторения
- В теории формальных языков
- Нечёткие регулярные выражения
- Регулярные выражения в PHP
- Классы символовCharacter Classes
preg_grep()
Функция preg_grep() перебирает все элементы заданного массива и возвращает все элементы, в которых совпадает заданное регулярное выражение.
Синтаксис функции preg_grep():
array preg_grep(string шаблон, array массив)
Пример использования функции preg_grep() для поиска в массиве слов, начинающихся на р:
$foods = array("pasta", "steak", "fish", "potatoes");
// Поиск элементов, начинающихся с символа "р".
// за которым следует один или несколько символов
$p_foods = preg_grep("/p(\w+)/", $foods);
$х = 0;
while($x < sizeof($p_foods)) :
print $p_foods. "<br>";
$Х++;
endwhile;
Результат:
pasta potatoes
Назад |
Содержание раздела |
Общее Содержание |
Вперед
2 Практический раздел. Ссылки
Перед тем, как использовать регулярные выражения, стоит посмотреть в документацию по вашему языку программирования и используемой библиотеке, так как диалекты обладают особенностями. Например в Perl и некоторых версиях php можно описывать рекурсивные регулярные выражения, которые не поддерживаются большинством других реализаций; механизмом флагов отличается JavaScript и так далее. Незначительными отличиями могут обладать даже различные версии одной и той же библиотеки.
Отличаются регулярные выражения не только синтаксисом, но и реализацией. Регулярные выражения — это «не просто так». Строка, задающее выражение, преобразуется в автомат, от реализации которого зависит эффективность. Масштаб проблемы хорошо иллюстрирует график зависимости времени выполнения поиска от длины строки и реализации:
Картинка взята из статьи «Поиск с помощью регулярных выражений может быть простым и быстрым«. В ней можно прочитать про различные реализации выражений, а также о том, как написать выражение так, чтобы оно работало быстрее. Кстати, так как выражение преобразуется в автомат, то зачастую его удобно визуализировать — для этого есть специальные сервисы, например. Для последнего выражения статьи будет построен такой автомат:
Примеры использования регулярных выражений:
- для валидации вводимых в поля данных: QValidator примеры использования. Ряд библиотек построения графического пользовательского интерфейса позволяют закреплять к полям ввода валидаторы, которые не позволяет ввести в формы некорректные данные. По приведенной выше ссылке можно найти валидацию номера банковской карты и номера телефона с помощью регулярных выражений библиотеки Qt. Аналогичные механизмы есть в других языках, например в Java для этого используется пакет ;
- для парсинга сайтов: Парсер сайта на Qt, использование QRegExp. В примере с сайта-галереи выбираются и скачиваются картинки заданных категорий;
- для валидации данных, передаваемых в формате JSON ряд библиотек позволяет задавать схему. При этом для строковых полей могут быть заданы регулярные выражения. В качестве упражнения можно попробовать составить выражение для пароля — проверить что строка содержит символы в разном регистре и цифры.
В сообществе Программирование и алгоритмы можно посмотреть дополнительную литературу по теме. Книгу Гойвертса и Левитана рекомендую посмотреть особенно, так как в ней по-полочкам разобраны десятки примеров, причем с учетом специфики реализации регулярных выражений в конкретных языках программирования.
WordPress: Using Regexp to Retrieve Images From a Post
As I know many of you are WordPress users, you’ll probably enjoy that code which allows you to retrieve all images from post content and display it.
To use this code on your blog, simply paste the following code on one of your theme files.
<?php if (have_posts()) : ?>
<?php while (have_posts()) : the_post(); ?>
<?php
$szPostContent = $post->post_content;
$szSearchPattern = '~<img * />~';
// Run preg_match_all to grab all the images and save the results in $aPics
preg_match_all( $szSearchPattern, $szPostContent, $aPics );
// Check to see if we have at least 1 image
$iNumberOfPics = count($aPics);
if ( $iNumberOfPics > 0 ) {
// Now here you would do whatever you need to do with the images
// For this example the images are just displayed
for ( $i=0; $i < $iNumberOfPics ; $i++ ) {
echo $aPics;
};
};
endwhile;
endif;
?>
Метасимволы
В регулярных выражениях используются два типа символов: обычные символы и метасимволы. Обычные символы — это те символы, которые имеют «буквальное» значение, а метасимволы — это те символы, которые имеют «особое» значение в регулярном выражении.
Преимуществом регулярных выражений является возможность использовать условия и повторения в шаблоне. Выражения записываются при помощи метасимволов, которые специальным образом интерпретируются. Метасимвол отличается от любого другого символа тем, что имеет специальное значение.
Одним из основных метасимволов является обратный слэш (\), который меняет тип символа, следующего за ним, на противоположный. Таким образом обычный символ можно превратить в метасимвол, а если это был метасимвол, то он теряет свое специальное значение и становится обычным символом. Этот приём нужен для того, чтобы вставлять в текст специальные символы как обычные. Например, символ в обычном режиме не имеет никаких специальных значений, но — это уже метасимвол, который обозначает: «любая цифра». Символ точка в обычном режиме значит — «любой единичный символ», а экранированная точка (\.) означает просто точку.
| Метасимвол | Описание | пример |
|---|---|---|
| . | Соответствует любому одиночному символу, кроме новой строки. | /./ соответствует строке, состоящей из одного символа. |
| ^ | Соответствует началу строки. | /^cars/ соответствует любой строке, которая начинается с cars. |
| $ | Соответствует шаблону в конце строки. | /com$/ соответствует строке, заканчивающейся на com, например gmail.com |
| * | Соответствует 0 или более вхождений. | /com*/ соответствует commute, computer, compromise и т.д. |
| + | Соответствующий предыдущему символу появляется как минимум один раз. | Например, /z+oom/ соответствует zoom. |
| \ | Используется для удаления метасимволов в регулярном выражении. | /google\.com/ будет рассматривать точку как буквальное значение, а не как метасимвол. |
| a-z | Соответствует строчным буквам. | cars |
| A-Z | Соответствует буквам в верхнем регистре. | CARS |
| 0-9 | Соответствует любому числу от 0 до 9. | /0-5/ соответствует 0, 1, 2, 3, 4, 5 |
| Соответствует классу символов. | // соответствует pqr | |
| | | Разделяет перечисление альтернативных вариантов. | /(cat|dog|fish)/ соответствует cat или dog или fish |
| \d | Любая цифра. | /(\d)/ соответствует цифре |
| \s | Найти пробельный символ (в т.ч. табуляция). | /(\s)/ соответствует пробелу |
| \b | Граница слова (начало или конец). | /\bWORD/ найти совпадение в начале слова |
Алгоритм[править]
Данный алгоритм работает быстрее недетерминированного конечного автомата, построенного по теореме Клини, но только для регулярных выражений, состоящих из символов:
- — один любой буквенный символ,
- — один любой символ,
- — символ начала текста,
- — символ конца текста,
- — предыдущий символ встречается ноль или более раз.
Например, для , очевидно, проще написать простой сопоставитель, чем строить НКА.
Псевдокодправить
function match(regexp: String, text: String): boolean
if regexp == '^'
return matchHere(regexp, text)
int i = 0
while i text.length
if matchHere(regexp, text)
return true
i++
return false
Функция проверяет есть ли вхождение регулярного выражения в любом месте в пределах текста. Если существует более одного вхождения, то найдется самое левое и самое короткое.
Логика функции проста. Если — первый символ регулярного выражения, то любое возможное вхождение должно начинаться в начале текста. То есть если — регулярное выражение, то должно входить в текст только с первой позиции текста, а не где-то в середине текста. Это проверяется путем сопоставления остатка регулярного выражения с текстом, начиная с первой позиции и нигде более.
В противном случае регулярное выражение может входить в текст в любой позиции. Это проверяется путем сопоставления регулярного выражения во всех позициях текста. Если регулярное выражение входит более одного раза в текст, то только самое левое вхождение будет распознано. То есть если — регулярное выражение, то для него найдется самое левое вхождение в текст.
function matchHere(regexp: String, text: String): boolean
if regexp == '\0'
return true
if regexp == '*'
return matchStar(regexp, regexp, text)
if regexp == '$' and regexp == '\0'
return text == '\0'
if text != '\0' and (regexp == '.' or regexp == text)
return matchHere(regexp, text)
return false
Основная часть работы сделана в , которая сопоставляет регулярное выражение с текстом в текущей позиции. Функция пытается сопоставить первый символ регулярного выражения с первым символом текста. В случае успеха мы можем сравнить следующий символ регулярного выражения со следующим символом текста, вызвав рекурсивно. Иначе нет совпадения с регулярным выражением в текущей позиции текста.
function matchStar(c: char, regexp: String, text: String): boolean
int i = 0
while i text.length and (text == c or c == '.')
if matchHere(regexp, text)
return true
i++
return false
Рассмотрим возможные случаи:
- Если в ходе рекурсии регулярное выражение осталось пустым то текст допускается этим регулярным выражением.
- Если регулярное выражение имеет вид , то вызывается функция которая пытается сопоставить повторение символа , начиная с нуля повторений и увеличивая их количество, пока не найдет совпадение с оставшимся текстом. Если совпадение не будет найдено, то регулярное выражение не допускает текст. Текущая реализация ищет «кратчайшее совпадение», которое хорошо подходит для сопоставления с образцом, как в grep, где нужно как можно быстрее найти совпадение. «Наидлиннейшее совпадение» более интуитивно и больше подходит для текстовых редакторов, где найденное заменят на что-то. Большинство современных библиотек для работы с регулярными выражениями предоставляют оба варианта.
- Если регулярное выражение это , то оно допускает этот текст тогда и только тогда, когда текст закончился.
- Если первый символ текста совпал с первым символом регулярного выражения, то нужно проверить совпадают ли следующий символ регулярного выражения со следующим символом текста, сделав рекурсивный вызов .
- Если все предыдущие попытки найти совпадения провалились, то никакая подстрока из текста не допускается регулярным выражением.
Модификацииправить
Немного изменим функцию для поиск самого левого и самого длинного вхождения :
- Найдем максимальную последовательность подряд идущих символов . Назовем ее .
- Сопоставим часть текста без с остатком регулярного выражения.
- Если части совпали, то текст допускается этим регулярным выражением. Иначе, если пусто, то текст не допускается этим регулярным выражением, иначе убираем один символ из и повторяем шаг .
Псевдокодправить
function matchStar(c: char, regexp: String, text: String): boolean
int i
for (i = 0; text != '\0' and (text == c or c == '.'); i++)
while i 0
if matchHere(regexp, text)
return true
i--
return false
Специальные конструкции в регулярках
-
ищет одну любую цифру, — один
любой символ, кроме цифры -
соответствует одной любой букве (любого алфавита), цифре
или знаку подчеркивания . соответствует
любому символу, кроме буквы, цифры, знака подчеркивания.
Также, есть удобное условие для указания на границу слова: .
Эта конструкция обозначает, что с одной стороны от нее должен стоять символ,
являющийся буквой/цифрой/знаком подчеркивания (), а с
другой стороны — не являющийся. Ну, например, мы хотим найти в тексте слово
«кот». Если мы напишем регулярку , то она
найдет последовательность этих букв в любом месте — например, внутри слова
«скотина». Это явно не то, что мы хотели. Если же мы добавим
условие границы слова в регулярку: , то теперь
искаться будет только отдельно стоящее слово «кот».
preg_match()
Функция preg_match() ищет в заданной строке совпадение для шаблона. Если совпадение найдено, возвращается TRUE, в противном случае возвращается FALSE.
Синтаксис функции preg_match():
int pregjnatch(string шаблон, string строка [, array совпадения})
При передаче необязательного параметра совпадения массив заполняется совпадениями различных подвыражений, входящих в основное регулярное выражение. В следующем примере функция preg_match() используется для проведения поиска без учета регистра:
$linе = "Vi is the greatest word processor ever created!";
// Выполнить поиск слова "Vi" без учета регистра символов:
if(preg_match("/\bVi\b\i", $line, $matcn)) :
print "Match found!";
endif;
// Команда if в этом примере возвращает TRUE
МетаСимволы
Для указания регулярных выражений используются метасимволы. В приведенном выше примере ( ) является метасимволом.
Метасимволы — это символы, которые интерпретируются особым образом механизмом RegEx. Вот список метасимволов:
[]. ^ $ * +? {} () \ |
— Квадратные скобки
Квадратные скобки указывают набор символов, которые вы хотите сопоставить.
| Выражение | Строка | Совпадения |
|---|---|---|
| 1 совпадение | ||
| 2 совпадения | ||
| Не совпадает | ||
| 5 совпадений |
Здесь будет соответствовать, если строка, которую вы пытаетесь сопоставить, содержит любой из символов , или .
Вы также можете указать диапазон символов, используя дефис в квадратных скобках.
то же самое, что и .
то же самое, что и .
то же самое, что и .
Вы можете дополСтрока (инвертировать) набор символов, используя символ вставки в начале квадратной скобки.
означает любой символ, кроме или или .
означает любой нецифровой символ.
— Точка
Точка соответствует любому одиночному символу (кроме новой строки ).
| Выражение | Строка | Совпадения |
|---|---|---|
| Не совпадает | ||
| 1 совпадение | ||
| 1 совпадение | ||
| 2 совпадения (содержит 4 символа) |
— Каретка
Символ каретки используется для проверки того, начинается ли строка с определенного символа.
| Выражение | Строка | Совпадения |
|---|---|---|
| 1 совпадение | ||
| 1 совпадение | ||
| Не совпадает | ||
| 1 совпадение | ||
| Нет совпадений (начинается с , но не сопровождается ) |
— доллар
Символ доллара используется для проверки того, заканчивается ли строка определенным символом.
| Выражение | Строка | Совпадения |
|---|---|---|
| 1 совпадение | ||
| 1 совпадение | ||
| Не совпадает |
— Звездочка
Символ звездочки соответствует предыдущему символу повторенному 0 или более раз. Эквивалентно {0,}.
| Выражение | Строка | Совпадения |
|---|---|---|
| 1 совпадение | ||
| 1 совпадение | ||
| 1 совпадение | ||
| Нет совпадений ( не следует ) | ||
| 1 совпадение |
— Плюс
Символ плюс соответствует предыдущему символу повторенному 1 или более раз. Эквивалентно {1,}.
| Выражение | Строка | Совпадения |
|---|---|---|
| Нет совпадений (нет символа) | ||
| 1 совпадение | ||
| 1 совпадение | ||
| Нет совпадений ( не следует ) | ||
| 1 совпадение |
— Вопросительный знак
Знак вопроса соответствует нулю или одному вхождению предыдущего символа. То же самое, что и {0,1}. По сути, делает символ необязательным.
| Выражение | Строка | Совпадения |
|---|---|---|
| 1 совпадение (0 вхождений а) | ||
| 1 совпадение | ||
| Нет совпадений (более одного символа) | ||
| Нет совпадений ( не следует ) | ||
| 1 совпадение |
— Фигурные скобки
Рассмотрим следующий код: . Это означает, по крайней мере , и не больше повторений предыдущего символа. При m=n=1 пропускается..
| Выражение | Строка | Совпадения |
|---|---|---|
| Не совпадает | ||
| 1 совпадение (в ) | ||
| 2 совпадения (при и ) | ||
| 2 совпадения (при и ) |
Посмотрим еще один пример. Это RegEx соответствует как минимум 2 цифрам, но не более 4-х цифр.
| Выражение | Строка | Совпадения |
|---|---|---|
| 1 совпадение (совпадение в ) | ||
| 3 совпадения ( , , ) | ||
| Не совпадает |
— Альтернация (или)
Альтернация (вертикальная черта) – термин в регулярных выражениях, которому в русском языке соответствует слово «ИЛИ». (оператор ).
Например: gr(a|e)y означает точно то же, что и gry.
| Выражение | Строка | Совпадения |
|---|---|---|
| Не совпадает | ||
| 1 совпадение (совпадение в ) | ||
| 3 совпадения (в ) |
Здесь сопоставьте любую строку, содержащую либо, либо
Чтобы примеСтрока альтернацию только к части шаблона, можно заключить её в скобки:
- найдёт или .
- найдёт или .
— Скобочные группы
Круглые скобки используются для группировки подшаблонов. Так, например, соответствует любой строке, которая соответствует либо или или с последующим
| Выражение | Строка | Совпадения |
|---|---|---|
| Не совпадает | ||
| 1 совпадение (совпадение в ) | ||
| 2 совпадения (в ) |
— обратная косая черта
Обратная косая черта используется для экранирования различных символов, включая все метасимволы. Например,
соответствует, если строка содержит , за которым следует . Здесь механизм RegEx не интерпретирует особым образом.
Если вы не уверены, имеет ли символ особое значение или нет, вы можете экранировать его косой чертой . Это гарантирует, что экранированный символ не будет компилироваться по-особенному.
Регулярные выражения PHP
PHP содержит встроенные функции, которые позволяют работать с регулярными выражениями. Теперь рассмотрим часто используемые функции регулярных выражений PHP.
- preg_match — используется для выполнения сопоставления с шаблоном строки. Она возвращает true, если совпадение найдено, и false, если совпадение не найдено;
- preg_split — используется для разбивки строки по шаблону, результат возвращается в виде числового массива;
- preg_replace – используется для поиска по шаблону и замены на указанную строку.
Ниже приведен синтаксис функций регулярных выражений, таких как preg_match, preg_split или PHP regexp replace:
<?php
имя_функции('/шаблон/',объект);
?>
, где
«имя_функции» — это либо preg_match, либо preg_split, либо preg_replace.«/…/» — косые черты обозначают начало и конец регулярного выражения.«‘/шаблон/’» — шаблон, который нам нужно сопоставить.«объект» — строка, с которой нужно сопоставлять шаблон.
Теперь рассмотрим практические примеры использования упомянутых выше функций.
Preg match PHP
В первом примере функция preg_match используется для выполнения простого сопоставления шаблоном для слова guru в заданном URL-адресе.
В приведенном ниже коде показан вариант реализации данного примера:
<?php
$my_url = "www.guru99.com";
if (preg_match("/guru/", $my_url))
{
echo "the url $my_url contains guru";
}
else
{
echo "the url $my_url does not contain guru";
}
?>
«preg_match (‘/ guru /’, $ my_url)»
Здесь:
«preg_match(…)» — функция PHP match regexp.«‘/Guru/’» — шаблон регулярного выражения.«$My_url» — переменная, содержащая текст, с которым нужно сопоставить шаблон.
Preg split PHP
Рассмотрим другой пример, в котором используется функция preg_split.
Мы возьмем фразу и разобьем ее на массив; шаблон предназначен для поиска единичного пробела:
<?php
$my_text="I Love Regular Expressions";
$my_array = preg_split("/ /", $my_text);
print_r($my_array );
?>
Preg replace PHP
Рассмотрим функцию preg_replace, которая выполняет сопоставление с шаблоном и заменяет найденный результат другой строкой.
Приведенный ниже код ищет в строке слово guru. Он заменяет его кодом css, который задает цвет фона:
<?php
$text = "We at Guru99 strive to make quality education affordable to the masses. Guru99.com";
$text = preg_replace("/Guru/", '<span style="background:yellow">Guru</span>', $text);
echo $text;
?>
Отличие «preg_match» от «preg_match_all»
Функция «preg_match» осуществляет поиск только до первого соответсвия с маской. Как только что-то найдено — поиск останавливается и возвращается одномерный массив.
if (preg_match('|<title>(.+)</title>|isU', $sContent, $arr))
return $arr; else return false;
Здесь нулевой элемент массива «$arr» содержит найденное совпадение вместе с тегами «title», а первый элемент — «$arr» только текст между этими тегами. Если в строке несколько тегов «title», это не значит что остальные значения будут записаны в «$arr» и так далее. Элемент «$arr» окажется не пуст если в маске указано несколько правил, но об этом в следующий раз.
Задачка на проверку телефонов
Задачу надо проверить на большом числе телефонов,
чтобы убедиться что твой код правильный. Для этого давай добавим в программу
тесты, чтобы сразу было видно, верно все работает или нет.
Сделай 2 списка номеров (правильные и нет), добавь их в программу и напиши цикл,
который их по очереди прогоняет через регулярку и проверяет,
что они определяются как надо (если нет — надо вывести, какой именно номер
не распознается правильно).
Вот список номеров:
// Правильные: $correctNumbers = ; // Неправильные: $incorrectNumbers = [ '02', '84951234567 позвать люсю', '849512345', '849512345678', '8 (409) 123-123-123', '7900123467', '5005005001', '8888-8888-88', '84951a234567', '8495123456a', '+1 234 5678901', /* неверный код страны */ '+8 234 5678901', /* либо 8 либо +7 */ '7 234 5678901' /* нет + */ ];
Подсказка: не надо строить сложных выражений и предусматривать все
возможные комбинации символов. Достаточно написать:

Скобочные группы ― ()
a(bc) создаём группу со значением bc -> тестa(?:bc)* оперетор ?: отключает группу -> тестa(?<foo>bc) так, мы можем присвоить имя группе -> тест
Этот оператор очень полезен, когда нужно извлечь информацию из строк или данных, используя ваш любимый язык программирования. Любые множественные совпадения, по нескольким группам, будут представлены в виде классического массива: доступ к их значениям можно получить с помощью индекса из результатов сопоставления.
Если присвоить группам имена (используя ), то можно получить их значения, используя результат сопоставления, как словарь, где ключами будут имена каждой группы.
Использование нумирации в заменах и другие продвинутые возможности
Теперь немного о продвинутых возможностях функции «preg_replace_callback». Ранее я упоминал что у неё есть два необязательных параметра. Первый (по умолчанию равен «-1») содержит максимальное количество замен, которое должна произвести функция. Второй — переменная, в которую будет записано количество произведенных замен.
$sContent = preg_replace_callback('|(<xx>)(.+)(</xx>)|iU',
function($matches){ //тут код }
,$sContent,2,$count);
Задав эти два параметра в предыдущем примере, замена главной буквы будет произведена только у первых двух имён. Соответственно, переменная «$count» будет содержать — 2. Если установить первый дополнительный параметр в «-1», то «$count» будет — 3.
И в конце о том, как узнать какая по счету замена происходит в данный момент. Это может потребоваться если появилась необходимость произвести замену между пятым и десятым найденным элементом строки или требуется для каких-то тегов прописать уникальные идентификаторы.
Для реализации может быть использована глобальная или статическая переменная. Использование глобальных переменных может быть отключено в PHP, поэтому рассмотрим пример со статической переменной. Присвоим всем тегам h2 уникальный идентификатор.
<?php
$str = '<h2>Марина</h2> <b>Алёша</b> <h2>Наташа</h2> <h2>Катя</h2>';
$str = preg_replace_callback('|<h2>(.+)</h2>|iU', function($matches){
static $id = 0;
$id++;
return '<h2 id="uniq-'.$id.'">'.$matches.'</h2>';
}, $str,-1,$count);
echo $str.' Количество замен: '.$count;
?>
Объявляя статическую переменную нужно помнить что она сохраняет своё значение между вызовами функции, поэтому идеально подходит для решения нашей задачи.
Строковые методы, поиск и замена
Следующие методы работают с регулярными выражениями из строк.
Все методы, кроме replace, можно вызывать как с объектами типа regexp в аргументах, так и со строками, которые автоматом преобразуются в объекты RegExp.
Так что вызовы эквивалентны:
var i = str.search(/\s/)
var i = str.search("\\s")
При использовании кавычек нужно дублировать \ и нет возможности указать флаги. Если регулярное выражение уже задано строкой, то бывает удобна и полная форма
var regText = "\\s" var i = str.search(new RegExp(regText, "g"))
Возвращает индекс регулярного выражения в строке, или -1.
Если Вы хотите знать, подходит ли строка под регулярное выражение, используйте метод (аналогично RegExp-методы ). Чтобы получить больше информации, используйте более медленный метод (аналогичный методу ).
Этот пример выводит сообщение, в зависимости от того, подходит ли строка под регулярное выражение.
function testinput(re, str){
if (str.search(re) != -1)
midstring = " contains ";
else
midstring = " does not contain ";
document.write (str + midstring + re.source);
}
Если в regexp нет флага , то возвращает тот же результат, что .
Если в regexp есть флаг , то возвращает массив со всеми совпадениями.
Чтобы просто узнать, подходит ли строка под регулярное выражение , используйте .
Если Вы хотите получить первый результат — попробуйте r.
В следующем примере используется, чтобы найти «Chapter», за которой следует 1 или более цифр, а затем цифры, разделенные точкой. В регулярном выражении есть флаг , так что регистр будет игнорироваться.
str = "For more information, see Chapter 3.4.5.1"; re = /chapter (\d+(\.\d)*)/i; found = str.match(re); alert(found);
Скрипт выдаст массив из совпадений:
- Chapter 3.4.5.1 — полностью совпавшая строка
- 3.4.5.1 — первая скобка
- .1 — внутренняя скобка
Следующий пример демонстрирует использование флагов глобального и регистронезависимого поиска с . Будут найдены все буквы от А до Е и от а до е, каждая — в отдельном элементе массива.
var str = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"; var regexp = //gi; var matches = str.match(regexp); document.write(matches); // matches =
Метод replace может заменять вхождения регулярного выражения не только на строку, но и на результат выполнения функции. Его полный синтаксис — такой:
var newString = str.replace(regexp/substr, newSubStr/function)
- Объект RegExp. Его вхождения будут заменены на значение, которое вернет параметр номер 2
- Строка, которая будет заменена на .
- Строка, которая заменяет подстроку из аргумента номер 1.
- Функция, которая может быть вызвана для генерации новой подстроки (чтобы подставить ее вместо подстроки, полученной из аргумента 1).
Метод не меняет строку, на которой вызван, а просто возвращает новую, измененную строку.
Чтобы осуществить глобальную замену, включите в регулярное выражение флаг .
Если первый аргумент — строка, то она не преобразуется в регулярное выражение, так что, например,
var ab = "a b".replace("\\s","..") // = "a b"
Вызов replace оставил строку без изменения, т.к искал не регулярное выражение , а строку «\s».
В строке замены могут быть такие спецсимволы:
| Pattern | Inserts |
| Вставляет «$». | |
| Вставляет найденную подстроку. | |
| Вставляет часть строки, которая предшествует найденному вхождению. | |
| Вставляет часть строки, которая идет после найденного вхождения. | |
| or | Где или — десятичные цифры, вставляет подстроку вхождения, запомненную -й вложенной скобкой, если первый аргумент — объект RegExp. |
Если Вы указываете вторым параметром функцию, то она выполняется при каждом совпадении.
В функции можно динамически генерировать и возвращать строку подстановки.
Первый параметр функции — найденная подстрока. Если первым аргументом является объект , то следующие параметров содержат совпадения из вложенных скобок. Последние два параметра — позиция в строке, на которой произошло совпадение и сама строка.
Например, следующий вызов возвратит XXzzzz — XX , zzzz.
function replacer(str, p1, p2, offset, s)
{
return str + " - " + p1 + " , " + p2;
}
var newString = "XXzzzz".replace(/(X*)(z*)/, replacer)
Как видите, тут две скобки в регулярном выражении, и потому в функции два параметра , .
Если бы были три скобки, то в функцию пришлось бы добавить параметр .
Следующая функция заменяет слова типа на :
function styleHyphenFormat(propertyName)
{
function upperToHyphenLower(match)
{
return '-' + match.toLowerCase();
}
return propertyName.replace(//, upperToHyphenLower);
}
Операторы повторения
Иногда мы хотим указать, что какой-нибудь символ повторяется определенное число раз. Когда мы знаем это число точно, то просто пишем (‘#aaaa#’). Но как поступить, если мы желаем повторить один либо больше раз?
Вопрос решается с помощью операторов повторения (квантификаторов): плюс ‘+’ (один и больше раз), потом звездочка ‘*’ (ноль и больше раз), а затем вопрос ‘?’ (ноль либо один раз, то есть может быть, а может и не быть).
Эти операторы действуют на символ, который непосредственно стоит перед ними.
Для наилучшего понимания стоит рассмотреть пример:

В коде выше шаблон поиска выглядит следующим образом: буква ‘x’, потом ‘a’ один либо больше раз, потом ‘x’.
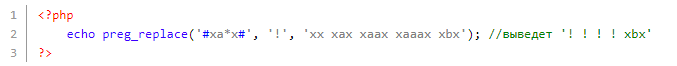
В этом случае шаблон поиска будет выглядеть следующим образом: буква ‘x’, буква ‘a’ ноль либо больше раз, буква ‘x’. То есть буквы ‘a’ либо нет, либо она повторяется один и больше раз.
Кроме самого очевидного варианта xax xaax xaaax, также подпадает подстрока ‘xx’, ведь там не существует буквы ‘a’ вообще (то есть ноль раз).
Также под шаблон не подпал и ‘xbx’. Это связано с тем, что отсутствует ‘a’, однако есть ‘b’ (ее не разрешали).

Здесь шаблон поиска выглядит следующим образом: буква ‘x’, далее ‘a’ может быть либо не быть, далее ‘x’.
В теории формальных языков
Основная статья: Регулярный язык
Регулярные выражения состоят из констант и операторов, которые определяют множества строк и множества операций на них соответственно.
На данном конечном алфавите Σ определены следующие константы:
- (пустое множество) ∅.
- (пустая строка) ε обозначает строку, не содержащую ни одного символа. Эквивалентно «».
- (символьный литерал) «a», где «a» — символ алфавита Σ.
- (множество) из символов, либо из других множеств.
и следующие операции:
- (сцепление, конкатенация) RS обозначает множество {αβ | α ∈ R & β ∈ S}. Например, {«boy», «girl»}{«friend», «cott»} = {«boyfriend», «girlfriend», «boycott», «girlcott»}.
- (дизъюнкция, чередование) R|S обозначает объединение R и S. Например, {«ab», «c»}|{«ab», «d», «ef»} = {«ab», «c», «d», «ef»}.
- (замыкание Клини, звезда Клини) R* обозначает минимальное надмножество множества R, которое содержит ε и замкнуто относительно конкатенации. Это есть множество всех строк, полученных конкатенацией нуля или более строк из R. Например, {«Run», «Forrest»}* = {ε, «Run», «Forrest», «RunRun», «RunForrest», «ForrestRun», «ForrestForrest», «RunRunRun», «RunRunForrest», «RunForrestRun», …}.
Нечёткие регулярные выражения
В некоторых случаях регулярные выражения удобно применить для анализа текстовых фрагментов на естественном языке, то есть написанных людьми, и, возможно, содержащих опечатки либо нестандартные варианты употреблений слов. Например, если проводить опрос (допустим, на веб-сайте) «какой станцией метро вы пользуетесь», может оказаться, что «Невский проспект» посетители могут указать как:
- Невский
- Невск. просп.
- Нев. проспект
- наб. Канала Грибоедова («Канал Грибоедова» — это название второго выхода ст. м. Невский проспект)
Здесь обычные регулярные выражения неприменимы, в первую очередь из-за того, что входящие в образцы слова могут совпадать не очень точно (нечётко), но, тем не менее, было бы удобно описывать регулярными выражениями структурные зависимости между элементами образца,
например, в нашем случае, указать, что совпадение может быть с образцом «Невский проспект» ИЛИ «Канал Грибоедова», притом «проспект» может быть сокращено до «пр» или отсутствовать, а перед «Канал» может находиться сокращение «наб.»
Эта задача сродни полнотекстовому поиску, отличаясь в том, что здесь короткий фрагмент должен сравниваться с набором образцов, а при полнотекстовом поиске, наоборот, образец обычно один, в то время как фрагмент текста очень большой, или задаче разрешения лексической многозначности, которая, однако, не позволяет задать структурирующие отношения между элементами образца.
Существует небольшое количество библиотек, реализующих механизм регулярных выражений с возможностью нечёткого сравнения:
- TRE — бесплатная библиотека на С, использующая синтаксис регулярных выражений, похожий на POSIX (стабильный проект);
- FREJ — open-source библиотека на Java, использующая Lisp-образный синтаксис и лишённая многих возможностей обычных регулярных выражений, но сосредоточенная на различного рода автоматических заменах фрагментов текста (бета-версия).
Регулярные выражения в PHP
PHP имеет встроенные функции, которые позволяют нам работать с регулярными выражениямии. Давайте теперь посмотрим на часто используемые функции регулярных выражений в PHP.
— эта функция используется для сопоставления с образцом в строке. Она возвращает истину, если совпадение найдено, и ложь, если совпадение не найдено. — эта функция используется для сопоставления с образцом в строке, а затем разбивает результаты в числовой массив. — эта функция используется для сопоставления с образцом строки и затем замены совпадения указанным текстом.Ниже приведен синтаксис функции регулярного выражения, такой как , или :
<?php
function_name('/pattern/',subject);
?>
«function_name (…)» это либо , , либо . «/…/» Косая черта обозначает начало и конец нашего регулярного выражения. «/ pattern /» — это шаблон, который нам нужен. «subject» — текстовая строка, с которой нужно сопоставить.
Давайте теперь посмотрим на практические примеры, которые реализуют вышеупомянутые функции регулярных выражений в PHP.
Классы символовCharacter Classes
Класс символов соответствует какому-либо одному набору символов.A character class matches any one of a set of characters. Классы символов состоят из языковых элементов, приведенных в следующей таблице.Character classes include the language elements listed in the following table. Дополнительные сведения см. в разделе Классы символов.For more information, see Character Classes.
| Класс знаковCharacter class | ОписаниеDescription | ШаблонPattern | Число соответствийMatches |
|---|---|---|---|
| character_group character_group | Соответствует любому одиночному символу, входящему в character_group.Matches any single character in character_group. По умолчанию при сопоставлении учитывается регистр.By default, the match is case-sensitive. | в in , в , in | |
| character_group character_group | Отрицание: соответствует любому одиночному символу, не входящему в character_group.Negation: Matches any single character that is not in character_group. По умолчанию символы в character_group чувствительны к регистру.By default, characters in character_group are case-sensitive. | , , в , , in | |
| first last first last | Диапазон символов: соответствует одному символу в диапазоне от первого до последнего.Character range: Matches any single character in the range from first to last. | , в , in | |
| Подстановочный знак: соответствует любому одиночному символу, кроме \n.Wildcard: Matches any single character except \n.Для сопоставления символа точки (.To match a literal period character (. или ) перед ней нужно поставить дополнительную обратную косую черту ().or ), you must precede it with the escape character (). | в in в in | ||
| имя name | Соответствует любому одиночному символу в общей категории Юникода или в именованном блоке, указанном в параметре имя.Matches any single character in the Unicode general category or named block specified by name. | , в , in , в , in | |
| имя name | Соответствует любому одиночному символу, не входящему в общую категорию Юникода или в именованный блок, указанный в параметре имя.Matches any single character that is not in the Unicode general category or named block specified by name. | , , в , , in , в , in | |
| Соответствует любому алфавитно-цифровому знаку.Matches any word character. | , , , , в , , , , in | ||
| Соответствует любому символу, который не является буквенно-цифровым знаком.Matches any non-word character. | , в , in | ||
| Соответствует любому знаку пробела.Matches any white-space character. | в in | ||
| Соответствует любому знаку, не являющемуся пробелом.Matches any non-white-space character. | в in | ||
| Соответствует любой десятичной цифре.Matches any decimal digit. | в in | ||
| Соответствует любому символу, не являющемуся десятичной цифрой.Matches any character other than a decimal digit. | , , , , в , , , , in |