Объект string
Содержание:
- Обратные символьные классы
- infexOf и lastIndexOf
- Строки могут быть объектами
- Поиск совпадений: метод exec
- Некоторые другие методы
- Работа с подстроками
- Сравнение строк
- Циклы for
- Поиски замена строковых значений
- Как сделать Object и простые объекты итерируемыми
- Доступ к символам
- Перевод других типов данных в строку
- Улучшена поддержка юникода
- includes, startsWith, endsWith
- Функции шаблонизации
- search()
- slice()
- Большинство методов поддерживают «thisArg»
- Итого
Обратные символьные классы
Для каждого символьного класса существует «обратный класс», обозначаемый той же буквой, но в верхнем регистре.
«Обратный» означает, что он соответствует всем другим символам, например:
- Не цифра: любой символ, кроме , например буква.
- Не пробел: любой символ, кроме , например буква.
- Любой символ, кроме , то есть не буквы из латиницы, не знак подчёркивания и не цифра. В частности, русские буквы принадлежат этому классу.
Мы уже видели, как сделать чисто цифровой номер из строки вида : найти все цифры и соединить их.
Альтернативный, более короткий путь – найти нецифровые символы и удалить их из строки:
infexOf и lastIndexOf
Данный метод
выполняет поиск подстроки substr, начиная с позиции pos:
str.indexOf(substr)
возвращает
позицию, на которой располагается совпадение, либо -1 если совпадений не
найдено.
let str = '<span class="clock">12:34</span>';
let indx1 = str.indexOf("clock"); // 13
let indx2 = str.indexOf("span", 2); // 27
let indx3 = str.indexOf("div"); // -1
console.log(indx1, indx2, indx3);
Обратите
внимание, данный метод находит только одно первое совпадение, дальше поиск не
продолжается. Если нужно найти все совпадения, то можно реализовать такой
простой алгоритм:
let indx = -1;
while(true) {
indx = str.indexOf("span", indx+1);
if(indx == -1) break;
console.log(indx);
}
Другой похожий метод
str.lastIndexOf(substr,
position)
ищет подстроку с
конца строки к началу. Он используется тогда, когда нужно получить самое
последнее вхождение:
let indx = str.lastIndexOf("span");
console.log(indx);
Строки могут быть объектами
Обычно строки JavaScript являются примитивными значениями, созданными из литералов:
Но строки также могут быть определены как объекты с ключевым словом :
Пример
var x = «John»;
var y = new String(«John»);
// typeof x вернёт строку// typeof y вернёт объект
Не создавайте строки как объекты. Это замедляет скорость выполнения.
Ключевое слово усложняет код. Это может привести к неожиданным результатам:
При использовании оператора одинаковые строки равны:
Пример
var x = «John»;
var y = new String(«John»);
// (x == y) верно, потому что х и у имеют равные значения
При использовании оператора одинаковые строки не равны, поскольку оператор ожидает равенства как по типу, так и по значению.
Пример
var x = «John»;
var y = new String(«John»);
// (x === y) является false (неверно), потому что x и y имеют разные типы (строка и объект)
Или даже хуже. Объекты нельзя сравнивать:
Пример
var x = new String(«John»);
var y = new String(«John»);
// (x == y) является false (неверно), потому что х и у разные объекты
Пример
var x = new String(«John»);
var y = new String(«John»);
// (x === y) является false (неверно), потому что х и у разные объекты
Обратите внимание на разницу между и .Сравнение двух JavaScript объектов будет всегда возвращать
Поиск совпадений: метод exec
Метод возвращает массив и ставит свойства регулярного выражения.
Если совпадений нет, то возвращается null.
Например,
// Найти одну d, за которой следует 1 или более b, за которыми одна d
// Запомнить найденные b и следующую за ними d
// Регистронезависимый поиск
var myRe = /d(b+)(d)/ig;
var myArray = myRe.exec("cdbBdbsbz");
В результате выполнения скрипта будут такие результаты:
| Объект | Свойство/Индекс | Описания | Пример |
| Содержимое . | |||
| Индекс совпадения (от 0) | |||
| Исходная строка. | |||
| Последние совпавшие символы | |||
| Совпадения во вложенных скобках, если есть. Число вложенных скобок не ограничено. | |||
| Индекс, с которого начинать следующий поиск. | |||
| Показывает, что был включен регистронезависимый поиск, флаг «». | |||
| Показывает, что был включен флаг «» поиска совпадений. | |||
| Показывает, был ли включен флаг многострочного поиска «». | |||
| Текст паттерна. |
Если в регулярном выражении включен флаг «», Вы можете вызывать метод много раз для поиска последовательных совпадений в той же строке. Когда Вы это делаете, поиск начинается на подстроке , с индекса . Например, вот такой скрипт:
var myRe = /ab*/g;
var str = "abbcdefabh";
while ((myArray = myRe.exec(str)) != null) {
var msg = "Found " + myArray + ". ";
msg += "Next match starts at " + myRe.lastIndex;
print(msg);
}
Этот скрипт выведет следующий текст:
Found abb. Next match starts at 3 Found ab. Next match starts at 9
В следующем примере функция выполняет поиск по input. Затем делается цикл по массиву, чтобы посмотреть, есть ли другие имена.
Предполагается, что все зарегистрированные имена находятся в массиве А:
var A = ;
function lookup(input)
{
var firstName = /\w+/i.exec(input);
if (!firstName)
{
print(input + " isn't a name!");
return;
}
var count = 0;
for (var i = 0; i < A.length; i++)
{
if (firstName.toLowerCase() == A.toLowerCase())
count++;
}
var midstring = (count == 1) ? " other has " : " others have ";
print("Thanks, " + count + midstring + "the same name!")
}
Некоторые другие методы
У строковых переменных
есть еще пара полезных и часто используемых методов, это:
str.trim()
убирает пробелы
в начале и конце строки:
let str = " string "; console.log( str.trim() );
И
str.repeat(n)
для повторения
строки n раз:
let str = "Abc"; console.log( str.repeat(5) );
Это, конечно, не
все методы строк. По мере использования JavaScript вы познакомитесь
со многими другими, но для начала этого будет достаточно. Также отдельно стоит
тема регулярных выражений – мощнейший инструмент для поиска, замены и проверки различных
строковых шаблонов, но об этом мы будем говорить на отдельном занятии.
Видео по теме
JavaScipt #1: что это такое, с чего начать, как внедрять и запускать
JavaScipt #2: способы объявления переменных и констант в стандарте ES6+
JavaScript #3: примитивные типы number, string, Infinity, NaN, boolean, null, undefined, Symbol
JavaScript #4: приведение типов, оператор присваивания, функции alert, prompt, confirm
JavaScript #5: арифметические операции: +, -, *, /, **, %, ++, —
JavaScript #6: условные операторы if и switch, сравнение строк, строгое сравнение
JavaScript #7: операторы циклов for, while, do while, операторы break и continue
JavaScript #8: объявление функций по Function Declaration, аргументы по умолчанию
JavaScript #9: функции по Function Expression, анонимные функции, callback-функции
JavaScript #10: анонимные и стрелочные функции, функциональное выражение
JavaScript #11: объекты, цикл for in
JavaScript #12: методы объектов, ключевое слово this
JavaScript #13: клонирование объектов, функции конструкторы
JavaScript #14: массивы (array), методы push, pop, shift, unshift, многомерные массивы
JavaScript #15: методы массивов: splice, slice, indexOf, find, filter, forEach, sort, split, join
JavaScript #16: числовые методы toString, floor, ceil, round, random, parseInt и другие
JavaScript #17: методы строк — length, toLowerCase, indexOf, includes, startsWith, slice, substring
JavaScript #18: коллекции Map и Set
JavaScript #19: деструктурирующее присваивание
JavaScript #20: рекурсивные функции, остаточные аргументы, оператор расширения
JavaScript #21: замыкания, лексическое окружение, вложенные функции
JavaScript #22: свойства name, length и методы call, apply, bind функций
JavaScript #23: создание функций (new Function), функции setTimeout, setInterval и clearInterval
Работа с подстроками
Рассмотрим javascript функции для работы с подстроками.
-
slice(start, ) — возвращает символы, между конкретных позиций.
let s = '0123456789'; let s_new = s.slice(0, 4); console.log(s_new); // 0123
Если второй параметр не указан, то вернет всё до конца строки.
-
substring(start, ) — работает аналогично. Отличие от «slice» в 2 моментах. Если стартовое значение больше конечного, то первая функция вернет пустую строку.
let s = '0123456789'; console.log(s.slice(6, 4)); // '' console.log(s.substring(6, 4)); // 45
Ещё различие в подходе при неверных параметрах.
let s = '0123456789'; console.log(s.slice(-4, -2)); // 67 console.log(s.substring(-4, -2)); // ''
Функция «slice()» конвертирует отрицательные значения в положительные, отталкиваясь от длины строки, а «substring()» просто устанавливает их в ноль, поэтому возвращает пустую строку.
-
substr(start, ) — возвращает подстроку, начиная с определенной позиции и определенной длины.
let s = '0123456789'; let s_new = s.substr(4, 3); console.log(s_new); // 456
Сравнение строк
В JavaScript для сравнения строк можно использовать операторы меньше и больше:
В JavaScript строки сравниваются посимвольно в алфавитном порядке. Сначала сравниваются первые символы строк, затем вторые, третьи… И как только какой-то символ оказывается меньше, строка считается меньше, даже если в строке больше символов. Если у какой-то строки заканчиваются символы, то она считается меньше, а если символы закончились у обоих строк одновременно – они одинаковые.
Но стоит отметить, что строки имеют внутреннюю кодировку Юникод – каждому символу соответствует свой числовой код.
Есть метод для получения символа по его коду String.fromCharCode():
Выполнить код »
Скрыть результаты
А вот метод charCodeAt() наоборот возвращает числовое значение Unicode символа, индекс которого был передан методу в качестве аргумента:
Выполнить код »
Скрыть результаты
А теперь давайте выведем интервал символов Unicode с кодами от 1025 до 1105:
Выполнить код »
Скрыть результаты
Как видите, не все символы в Юникоде соответствуют их месту в алфавите. Есть некоторые исключения. Строчные буквы идут после заглавных, поэтому они всегда больше. А буква ‘ё’, имеет код, больший чем ‘я’, поэтому ‘ё’(код 1105) > ‘я’(код 1103).
Для правильного сравнения строк используйте метод str1.localeCompare(str2), который сравнивает одну строку с другой и возвращает одно из трех значений:
- Если строка str1 должна располагаться по алфавиту перед str2, возвращается -1.
- Если строка str1 равна str2, возвращается .
- Если строка str1 должна располагаться по алфавиту после str2, возвращается 1.
Циклы for
Цикл for может использовать до трех опциональных выражений для повторного выполнения блока кода.
Рассмотрим синтаксис цикла.
- Инициализация (если указано) запускает счетчик и объявляет переменные.
- Далее обрабатывается условие. Если оно истинно, программа выполнит последующий код; если оно ложно, цикл прервется.
- Затем обрабатывается код, который нужно выполнить.
- Если указано финальное выражение, оно обновляется, после чего цикл возвращается к обработке условия.
Чтобы понять, как это работает, рассмотрим базовый пример.
Если запустить этот код, вы получите такой результат:
В приведенном выше примере цикл for начинается с переменной let i = 0, которая запустит цикл со значения 0. В цикле задано условие i < 4, а это означает, что до тех пор, пока значение i меньше 4, цикл будет продолжать работу. Финальное выражение i++ определяет счетчик для каждой итерации цикла. console.log(i) выводит числа, начиная с 0, и останавливается, как только i равняется 4.
Без цикла код, выполняющий те же действия, был бы таким:
Без цикла блок кода состоит из большего количества строк. Чтобы увеличить количество чисел, пришлось бы внести в код еще больше строк.
Давайте рассмотрим каждое выражение в цикле.
Инициализация
Первое выражение в цикле – инициализация.
Оно объявляет переменную i с помощью ключевого слова let (также можно использовать ключевое слово var) и присваивет ей значение 0. Вы можете использовать в циклах любые имена переменных, но переменная i ассоциируется со словом «итерация» (iteration) и не перегружает код.
Условие
Как и циклы while и do…while, циклы for обычно имеют условие. В данном примере это:
Это значит, что выражение оценивается как истинное, пока значение i меньше 4.
Финальное выражение
Это выражение, которое выполняется в конце каждого цикла. Чаще всего оно используется для увеличения или уменьшения значения переменной, но его можно использовать и для других целей.
В данном примере цикл увеличивает переменную на единицу. Выражение i++ делает то же самое, что и i = i + 1.
В отличие от начала и условия, финальное выражение не заканчивается точкой с запятой.
Тело цикла
Теперь вы знаете все компоненты цикла for. Взглянем на код еще раз.
Первое выражение задает исходное значение переменной (0), второе определяет условие (цикл выполняется, пока i меньше 4), а третье – задает шаг каждой итерации (в данном случае значение будет увеличиваться на 1).
Консоль будет выводить значения: 0, 1, 2 и 3. Затем цикл прервется.
Поиски замена строковых значений
С помощью метода replace() можно осуществлять поиск строки и её замену новым значением. В качестве первого параметра методу следует передать значение для поиска, а вторым – значения для замены.
constoriginalString = "How are you?"
// Заменяем первое вхождение строки "How" на "Where"
constnewString = originalString.replace("How", "Where");
console.log(newString);
Вывод
Where are you?
Также можно использовать регулярные выражения. Например, метод replace() затрагивает только первое вхождение искомой строки. Но мы можем использовать флаг g (глобальный), чтобы найти все вхождения, и флаг i (независимый от регистра), чтобы игнорировать регистр.
constoriginalString = "Javascript is a programming language. I'm learning javascript." // Ищемвсевхождениястроки"javascript" изаменяемеёна"JavaScript" constnewString = originalString.replace(/javascript/gi, "JavaScript"); console.log(newString); Вывод JavaScript is a programming language. I'm learning JavaScript.
Как сделать Object и простые объекты итерируемыми
Простые объекты не являются итерируемыми, как и объекты из .
Однако этот момент можно обойти, добавив @@iterator к Object.prototype с пользовательским итератором.
Переменная содержит свойства объекта, полученного с помощью вызова . В функции next возвращается каждое значение из переменной properties и обновляется count, чтобы получить следующее значение из переменной properties, используя переменную count в качестве индекса. Когда count будет равен длине properties, устанавливаем значение true, чтобы остановить итерацию.
Тестирование с помощью Object:
Работает!!!
С простыми объектами:
Та-дам!!
Стоить добавить этот способ в качестве полифилла, чтобы использовать for..of с любыми объектами в приложении.
Использование for…of с классами ES6
Можно использовать for..of для итерации по списку данных в экземпляре класса.
Класс Profiles обладает свойством , которое содержит массив пользователей. Возможно, потребуется отобразить эти данные в приложении с помощью for…of. Пробуем:
Очевидно, for…of не сработает
Вот несколько правил, чтобы сделать итерируемым:
- Объект должен иметь свойство .
- Функция должна возвращать итератор.
- должен реализовывать функцию .
Свойство @@iterator определяется с помощью константы .
Запускаем:
Свойство profiles отображено.
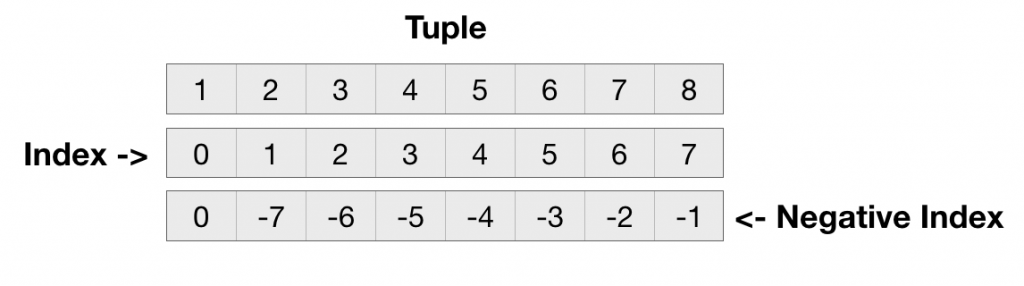
Доступ к символам
Продемонстрируем, как получить доступ к символам и индексам строки How are you?
"How are you?";
Используя квадратные скобки, можно получить доступ к любому символу строки.
"How are you?"; Вывод r
Мы также можем использовать метод charAt(), чтобы вернуть символ, передавая индекс в качестве параметра.
"Howareyou?".charAt(5); Вывод r
Также можно использовать indexOf(), чтобы вернуть индекс первого вхождения символа в строке.
"How are you?".indexOf("o");
Вывод
1
Несмотря на то, что символ «o» появляется в строке How are you? дважды, indexOf() вернёт позицию первого вхождения.
lastIndexOf() используется, чтобы найти последнее вхождение.
"How are you?".lastIndexOf("o");
Вывод
9
Оба метода также можно использовать для поиска нескольких символов в строке. Они вернут индекс первого символа.
"How are you?".indexOf("are");
Вывод
4
А вот метод slice() вернёт символы между двумя индексами.
"How are you?".slice(8, 11); Вывод you
Обратите внимание на то, что 11– это ?, но? не входит в результирующую строку. slice() вернёт всё, что между указанными значениями индекса
Если второй параметр опускается, slice() вернёт всё, начиная от первого параметра до конца строки.
"How are you?".slice(8); Вывод you?
Методы charAt() и slice() помогут получить строковые значения на основании индекса. А indexOf() и lastIndexOf() делают противоположное, возвращая индексы на основании переданной им строки.
Перевод других типов данных в строку
Для того чтобы перевести в строку такие типы данных как (целое число), (массив), (логический тип), а также другие типы, нужно всего лишь сложить значение любого типа с пустой строкой.
//Перевод целого числа в строку
var num = 454; //В переменной num хранится число — 454
num = num + «»; //Переопределение num, теперь в ней хранится строка — «454»
//Перевод массива в строку
var arr = ; //В arr сейчас хранится массив Array
arr += «»; //После переопределения arr содержит строку «one, two, three»
|
1 |
//Перевод целого числа в строку varnum=454;//В переменной num хранится число — 454 num=num+»»;//Переопределение num, теперь в ней хранится строка — «454» //Перевод массива в строку vararr=’one’,’two’,’three’;//В arr сейчас хранится массив Array arr+=»»;//После переопределения arr содержит строку «one, two, three» |
Улучшена поддержка юникода
Внутренняя кодировка строк в JavaScript – это UTF-16, то есть под каждый символ отводится ровно два байта.
Но под всевозможные символы всех языков мира 2 байт не хватает. Поэтому бывает так, что одному символу языка соответствует два юникодных символа (итого 4 байта). Такое сочетание называют «суррогатной парой».
Самый частый пример суррогатной пары, который можно встретить в литературе – это китайские иероглифы.
Заметим, однако, что не всякий китайский иероглиф – суррогатная пара. Существенная часть «основного» юникод-диапазона как раз отдана под китайский язык, поэтому некоторые иероглифы – которые в неё «влезли» – представляются одним юникод-символом, а те, которые не поместились (реже используемые) – двумя.
Например:
В тексте выше для первого иероглифа есть отдельный юникод-символ, и поэтому длина строки , а для второго используется суррогатная пара. Соответственно, длина – .
Китайскими иероглифами суррогатные пары, естественно, не ограничиваются.
Ими представлены редкие математические символы, а также некоторые символы для эмоций, к примеру:
В современный JavaScript добавлены методы String.fromCodePoint и str.codePointAt – аналоги и , корректно работающие с суррогатными парами.
Например, считает суррогатную пару двумя разными символами и возвращает код каждой:
…В то время как возвращает его Unicode-код суррогатной пары правильно:
Метод корректно создаёт строку из «длинного кода», в отличие от старого .
Например:
Более старый метод в последней строке дал неверный результат, так как он берёт только первые два байта от числа и создаёт символ из них, а остальные отбрасывает.
Есть и ещё синтаксическое улучшение для больших Unicode-кодов.
В JavaScript-строках давно можно вставлять символы по Unicode-коду, вот так:
Синтаксис: , где – четырёхзначный шестнадцатиричный код, причём он должен быть ровно четырёхзначным.
«Лишние» цифры уже не войдут в код, например:
Чтобы вводить более длинные коды символов, добавили запись , где – максимально восьмизначный (но можно и меньше цифр) код.
Например:
Во многих языках есть символы, которые получаются как сочетание основного символа и какого-то значка над ним или под ним.
Например, на основе обычного символа существуют символы: . Самые часто встречающиеся подобные сочетания имеют отдельный юникодный код. Но отнюдь не все.
Для генерации произвольных сочетаний используются несколько юникодных символов: основа и один или несколько значков.
Например, если после символа идёт символ «точка сверху» (код ), то показано это будет как «S с точкой сверху» .
Если нужен ещё значок над той же буквой (или под ней) – без проблем. Просто добавляем соответствующий символ.
К примеру, если добавить символ «точка снизу» (код ), то будет «S с двумя точками сверху и снизу» .
Пример этого символа в JavaScript-строке:
Такая возможность добавить произвольной букве нужные значки, с одной стороны, необходима, а с другой стороны – возникает проблемка: можно представить одинаковый с точки зрения визуального отображения и интерпретации символ – разными сочетаниями Unicode-кодов.
Вот пример:
В первой строке после основы идёт сначала значок «верхняя точка», а потом – нижняя, во второй – наоборот. По кодам строки не равны друг другу. Но символ задают один и тот же.
С целью разрешить эту ситуацию, существует юникодная нормализация, при которой строки приводятся к единому, «нормальному», виду.
В современном JavaScript это делает метод str.normalize().
Забавно, что в данной конкретной ситуации приведёт последовательность из трёх символов к одному: \u1e68 (S с двумя точками).
Это, конечно, не всегда так, просто в данном случае оказалось, что именно такой символ в юникоде уже есть. Если добавить значков, то нормализация уже даст несколько символов.
Для большинства практических задач информации, данной выше, должно быть вполне достаточно, но если хочется более подробно ознакомиться с вариантами и правилами нормализации – они описаны в приложении к стандарту юникод Unicode Normalization Forms.
includes, startsWith, endsWith
Следующие три
метода позволяют проверять: есть ли в строке искомая подстрока. Первый метод
имеет ожидаемый синтаксис:
str.includes(substr)
он возвращает true, если подстрока
substr была найдена в
строке str и false в противном
случае. Второй необязательный параметр pos указывает
начальный индекс для поиска. Вот примеры использования данного метода:
let str = '<span class="clock">12:34</span>';
console.log( str.includes("span") );
console.log( str.includes("<span>") );
console.log( str.includes("clock", 20) );
Следующие два
метода startsWith и endsWith проверяют, соответственно, начинается ли и
заканчивается ли строка определённой строкой:
console.log( str.startsWith("span") ); //false
console.log( str.startsWith("<span") ); //true
console.log( str.endsWith("span>") ); //true
Функции шаблонизации
Можно использовать свою функцию шаблонизации для строк.
Название этой функции ставится перед первой обратной кавычкой:
Эта функция будет автоматически вызвана и получит в качестве аргументов строку, разбитую по вхождениям параметров и сами эти параметры.
Например:
В примере выше видно, что строка разбивается по очереди на части: «кусок строки» – «параметр» – «кусок строки» – «параметр».
- Участки строки идут в первый аргумент-массив .
- У этого массива есть дополнительное свойство . В нём находятся строки в точности как в оригинале. Это влияет на спец-символы, например в символ – это перевод строки, а в – это именно два символа .
- Дальнейший список аргументов функции шаблонизации – это значения выражений в , в данном случае их три.
Зачем ?
В отличие от , в содержатся участки строки в «изначально введённом» виде.
То есть, если в строке находится или или другое особое сочетание символов, то оно таким и останется.
Это нужно в тех случаях, когда функция шаблонизации хочет произвести обработку полностью самостоятельно (свои спец. символы?). Или же когда обработка спец. символов не нужна – например, строка содержит «обычный текст», набранный непрограммистом без учёта спец. символов.
Как видно, функция имеет доступ ко всему: к выражениям, к участкам текста и даже, через – к оригинально введённому тексту без учёта стандартных спец. символов.
Функция шаблонизации может как-то преобразовать строку и вернуть новый результат.
В простейшем случае можно просто «склеить» полученные фрагменты в строку:
Функция в примере выше делает то же самое, что обычные обратные кавычки. Но, конечно, можно пойти намного дальше. Например, генерировать из HTML-строки DOM-узлы (функции шаблонизации не обязательно возвращать именно строку).
Или можно реализовать интернационализацию. В примере ниже функция осуществляет перевод строки.
Она подбирает по строке вида шаблон перевода (где – место для вставки параметра) и возвращает переведённый результат со вставленным именем :
Итоговое использование выглядит довольно красиво, не правда ли?
Разумеется, эту функцию можно улучшить и расширить. Функция шаблонизации – это своего рода «стандартный синтаксический сахар» для упрощения форматирования и парсинга строк.
search()
Отдаёт расположение первого совпадения строки в заданной строке.
Этот метод отдаёт индекс начала упоминания или , если такого не было найдено.
Вы можете использовать регулярные выражения (и на самом деле, даже если вы передаёте строку, то внутренне оно тоже применяется как регулярное выражение).
slice()
Отдает новую строку, которая является частью строки на которой применялся метод, от позиций до .
Оригинальная строка не изменяется.
опциональна.
Если вы выставите первым параметром отрицательное число, то начальный индекс будет считаться с конца и второй параметр тоже должен быть отрицательным, всегда ведя отсчет с конца:
Большинство методов поддерживают «thisArg»
Почти все методы массива, которые вызывают функции – такие как , , , за исключением метода , принимают необязательный параметр .
Этот параметр не объяснялся выше, так как очень редко используется, но для наиболее полного понимания темы мы обязаны его рассмотреть.
Вот полный синтаксис этих методов:
Значение параметра становится для .
Например, вот тут мы используем метод объекта как фильтр, и передаёт ему контекст:
Если бы мы в примере выше использовали просто , то вызов был бы в режиме отдельной функции, с . Это тут же привело бы к ошибке.
Вызов можно заменить на , который делает то же самое. Последняя запись используется даже чаще, так как функция-стрелка более наглядна.
Итого
Существуют следующие символьные классы:
- – цифры.
- – не цифры.
- – пробельные символы, табы, новые строки.
- – все, кроме .
- – латиница, цифры, подчёркивание .
- – все, кроме .
- – любой символ, если с флагом регулярного выражения , в противном случае любой символ, кроме перевода строки .
…Но это не всё!
В кодировке Юникод, которую JavaScript использует для строк, каждому символу соответствует ряд свойств, например – какого языка это буква (если буква), является ли символ знаком пунктуации, и т.п.
Можно искать, в том числе, и по этим свойствам. Для этого нужен флаг , который мы рассмотрим в следующей главе.