Find и grep в linux как инструмент для администрирования
Содержание:
- Examples
- Рассмотрим ещё один пример поиска фрагментов из нескольких строк
- Пример использования
- Regular expressions
- Grep AND
- Опции — расширения GNU
- Поиск через графический интерфейс
- Команда sed в Linux
- Выражения в квадратных скобках и Классы символов
- Basic Usage
- Популярные теги
- Разница между grep, egrep, fgrep, pgrep, zgrep
- Параметры grep
- Примеры использования регулярных выражений
Examples
Tip
If you haven’t already seen our section, we suggest reviewing that section first.
grep chope /etc/passwd
Search /etc/passwd for user chope.
grep "May 31 03" /etc/httpd/logs/error_log
Search the Apache error_log file for any error entries that happened on May 31st at 3 A.M. By adding quotes around the string, this allows you to place spaces in the grep search.
grep -r "computerhope" /www/
Recursively search the directory /www/, and all subdirectories, for any lines of any files which contain the string «computerhope«.
grep -w "hope" myfile.txt
Search the file myfile.txt for lines containing the word «hope«. Only lines containing the distinct word «hope» are matched. Lines where «hope» is part of a word (e.g., «hopes») are not be matched.
grep -cw "hope" myfile.txt
Same as previous command, but displays a count of how many lines were matched, rather than the matching lines themselves.
grep -cvw "hope" myfile.txt
Inverse of previous command: displays a count of the lines in myfile.txt which do not contain the word «hope».
grep -l "hope" /www/*
Display the file names (but not the matching lines themselves) of any files in /www/ (but not its subdirectories) whose contents include the string «hope«.
Рассмотрим ещё один пример поиска фрагментов из нескольких строк
Допустим имеется файл со следующим модержимым:
kkkkkkkkkkk jjjjjjjjjjjjjjjjjj gggggggggggg/CK JHGHHHHHHHH HJKHKKLKLLL JNBHBHJKJJLKKL JLKKKLLKJLKJ/D GGGGGGGGGGGGGG GGGGGGGGGGGGGG
Мне хочется, чтобы были выбраны строки начиная с CK с конца строки и поиск совпадений был остановлен, когда строка на конце имеет D.
То есть должно быть выведено:
gggggggggggg/CK JHGHHHHHHHH HJKHKKLKLLL JNBHBHJKJJLKKL JLKKKLLKJLKJ/D
Лучше использовать awk или sed:
awk '/CK$/,/D$/' file.txt
ИЛИ:
sed -n '/CK$/,/D$/p' file.txt
Если хочется именно grep, то для GNU grep это делается следующим образом:
grep -oPz '(?s)(?<=\n)\N+CK\n.*?D(?=\n)' file.txt
Здесь:
- -P активирует perl-regexp
- -z устанавливает разделитель строк на NUL. Это принуждает grep видеть весь файл как одну строку
- -o печать только совпадающей части
- (?s) активирует PCRE_DOTALL, поэтому . (точка) это любые символы или newline
- \N совпадает со всем, кроме newline
- .*? находит . в режиме nongreedy (не жадный)
- (?<=..) это look-behind (смотреть после) выражения
- (?=..) это look-ahead (смотреть до) выражения
Рассмотрим ещё пример.
Пример использования
Допустим, требуется быстро найти фразу «our products» в HTML-файлах на компьютере. Начнем с поиска в одном из них. В данном случае ШАБЛОН – это «our products», а ФАЙЛ – product-listing.html
$ grep "our products" product-listing.html <p>You will find that all of our products are impeccably designed and meet the highest manufacturing standards available <em>anywhere. </em> </p> $
Была найдена одна строка, содержащая указанный шаблон, и grep выводит всю соответствующую строку на терминал. Строка длиннее ширины окна терминала, поэтому текст переносится на следующие строки, но данный вывод соответствует ровно одной строке в файле.
Regular expressions
A regular expression is a pattern that describes a set of strings. Regular expressions are constructed analogously to arithmetic expressions, using various operators to combine smaller expressions.
grep understands three different versions of regular expression syntax: «basic» (BRE), «extended» (ERE) and «perl» (PRCE). In GNU grep, there is no difference in available functionality between basic and extended syntaxes. In other implementations, basic regular expressions are less powerful. The following description applies to extended regular expressions; differences for basic regular expressions are summarized afterwards. Perl regular expressions give additional functionality.
The fundamental building blocks are the regular expressions that match a single character. Most characters, including all letters and digits, are regular expressions that match themselves. Any metacharacter with special meaning may be quoted by preceding it with a backslash.
The period (.) matches any single character.
Grep AND
5. Grep AND using -E ‘pattern1.*pattern2’
There is no AND operator in grep. But, you can simulate AND using grep -E option.
grep -E 'pattern1.*pattern2' filename grep -E 'pattern1.*pattern2|pattern2.*pattern1' filename
The following example will grep all the lines that contain both “Dev” and “Tech” in it (in the same order).
$ grep -E 'Dev.*Tech' employee.txt 200 Jason Developer Technology $5,500
The following example will grep all the lines that contain both “Manager” and “Sales” in it (in any order).
$ grep -E 'Manager.*Sales|Sales.*Manager' employee.txt
Note: Using regular expressions in grep is very powerful if you know how to use it effectively.
6. Grep AND using Multiple grep command
You can also use multiple grep command separated by pipe to simulate AND scenario.
grep -E 'pattern1' filename | grep -E 'pattern2'
The following example will grep all the lines that contain both “Manager” and “Sales” in the same line.
$ grep Manager employee.txt | grep Sales 100 Thomas Manager Sales $5,000 500 Randy Manager Sales $6,000
Опции — расширения GNU
Опции
-A —after-context=ЧИСЛО_СТРОК
-B —before-context=ЧИСЛО_СТРОК
-C —context=ЧИСЛО_СТРОК
С этими тремя опциями мы уже познакомились в четвертой Хитрости, они позволяют посмотреть соседние строки. -A: количество строк после совпадения с ОБРАЗЦОМ,
-B: количество строк перед совпадением, и -C: количество строк вокруг совпадения.
Опция —colour
Выделяет найденные строки цветом. Значения КОГДА могут быть: never (никогда), always (всегда), или auto. Пример:
grep -o 'английскими' --color grep-ru.txt английскими
Опция -D ДЕЙСТВИЕ
—devices=ДЕЙСТВИЕ
Если исследуемый файл является файлом устройства, FIFO (именованным каналом) или сокетом, то следует применять эту опцию. ДЕЙСТВИЙ всего два: read (прочесть), и skip (пропустить). Если вы указываете ДЕЙСТВИЕ read (используется по умолчанию), то программа попытается прочесть специальный файл, как если бы он был обычным файлом; если указываете ДЕЙСТВИЕ skip, то файлы устройств, FIFO и сокеты будут молча проигнорированы.
Опция -d ДЕЙСТВИЕ
—directories=ДЕЙСТВИЕ
Если входной файл является директорией, то используйте эту опцию. ДЕЙСТВИЕ read (прочесть) попытается прочесть директорию как обычный файл (некоторые ОС и файловые системы запрещают это; тогда появятся соответствующие сообщения, либо директории молча пропустят). Если ДЕЙСТВИЕ skip (пропустить), то директории будут молча проигнорированы. Если ДЕЙСТВИЕ recurse (рекурсивно), то grep будет просматривать все файлы и субдиректории внутри заданного каталога рекурсивно. Это эквивалент опции -r, с которой мы уже познакомились.
—with-filename
Выдает имя файла для каждого совпадения с ОБРАЗЦОМ. Мы успешно делали это без всяких опций в Хитрости второй.
—no-filename
Подавляет вывод имен файлов, когда задано несколько файлов для исследования.
Опция -I
Обрабатывает бинарные файлы как не содержащие совпадений с ОБРАЗЦОМ; эквивалент опции —binary-files=without-match.
Опция —include=ОБРАЗЕЦ_имени_файла
При рекурсивном исследовании директорий обследовать только файлы, содержащие в своем имени ОБРАЗЕЦ_имени_файла.
Опция -m ЧИСЛО_СТРОК
—max-count=ЧИСЛО_СТРОК
Прекратить обработку файла после того, как количество совпадений с ОБРАЗЦОМ достигнет ЧИСЛА_СТРОК:
grep -m 2 'kot' kot.txt kot kotoroe
Опция -y
Синоним опции -i (не различать верхний и нижний регистр символов).
Опции -U и -u применяются только под MS-DOS и MS-Windows, тут нечего о них говорить.
Опция —mmap
Использует системный вызов mmap вместо системного вызова read. Может дать лучшую производительность, а может привести к ошибкам. Это для продвинутых пользователей.
Опция -Z
—null
Если в выводе программы имена файлов (например при опции -l), то опция -Z после каждого имени файла выводит нулевой байт вместо символа новой строки (как обычно происходит). Это делает вывод однозначным, даже если имена файлов содержат символы новой строки. Эта опция может быть использована совместно с такими командами как: find -print0, perl -0, sort -z, xargs -0 для обработки файловых имен, составленных необычно, даже содержащих символы новой строки.
(Хотел бы я знать, как можно включить символ новой строки в имя файла. Если кто знает, не поленитесь — сообщите мне.)
Опция -z
—null-data
Рассматривает ввод как набор строк, каждая из которых заканчивается не символом новой строки, а нулевым байтом. Как и предыдущая опция, используется совместно с вышеперечисленными командами для обработки экзотических имен файлов.
Поиск через графический интерфейс
Главное меню
С помощью главного меню ОС вы можете не только искать и запускать программы, но также и выполнять поиск файлов. Подобный функционал присутствует во многих окружениях рабочего стола (, , и пр.). Например, в KDE это представлено следующим образом:
При этом стоит отметить, что такой вариант поиска ориентирован больше на поиск программ, нежели на поиск файлов, поэтому выполняется он только в домашнем каталоге и не уходит вглубь файловой системы.
Файловые менеджеры
Многие файловые менеджеры также предоставляют возможности поиска файлов. Например, в Dolphin для запуска поиска достаточно просто нажать кнопку со значком лупы, а затем ввести имя файла (или папки) в строку поиска. При этом вы можете выбрать папку, в которой будет выполняться поиск, а также указать дополнительные параметры (поиск по содержимому и пр.). Помимо этого в качестве поискового запроса допускается применять символы и :
Поиск по содержимому в Dolphin:
KFind
В KDE, помимо вышеупомянутых инструментов поиска, также есть замечательная утилита под названием KFind. С её помощью вы можете точно настроить параметры поиска (указать имя файла, его тип и путь поиска, обычный текстовый поиск или мета-поиск, дату изменения, размер, пользователя, группу и пр.). Она также позволяет сохранять результаты поиска в виде простого текстового списка URL-адресов найденных файлов:
SearchMonkey
SearchMonkey позволяет выполнять поиск файла, как по имени, так и по его содержимому, по диапазону дат и пр. Но главное преимущество SearchMonkey — это возможность везде применять регулярные выражения.
Поиск с применением регулярного выражения в SearchMonkey:
Recoll
Recoll — это приложение (поисковый движок) для полнотекстового поиска, выполняющее поиск ваших данных по содержимому, а не по внешним атрибутам (например, по имени файла). Вам не нужно запоминать, в каком файле или сообщении электронной почты вы хранили ту или иную информацию. Необходимо лишь указать слова (или выражения), которые должны или не должны присутствовать в искомом тексте, и взамен вы получите список соответствующих документов, упорядоченных таким образом, что первыми идут наиболее релевантные из них (подобно поисковым системам Интернета).
Установить программу можно из официальных репозиториев через командную строку:
Или через графический интерфейс:
Сразу же после запуска утилита предложит вам создать индекс документов, которые присутствуют в вашем домашнем каталоге. После создания индекса вы сможете выполнять по нему поиск. Для этого достаточно ввести какой-нибудь запрос, например, , и вы увидите все файлы, которые содержат это слово с примерами вхождений, отсортированные по релевантности:
Это может быть очень удобно при работе с большим объемом текстовых данных. Программа поддерживает такие форматы файлов, как: .pdf, .djvu, .doc, .docx, .odf. А также умеет находить перечисленные файлы в архивах.
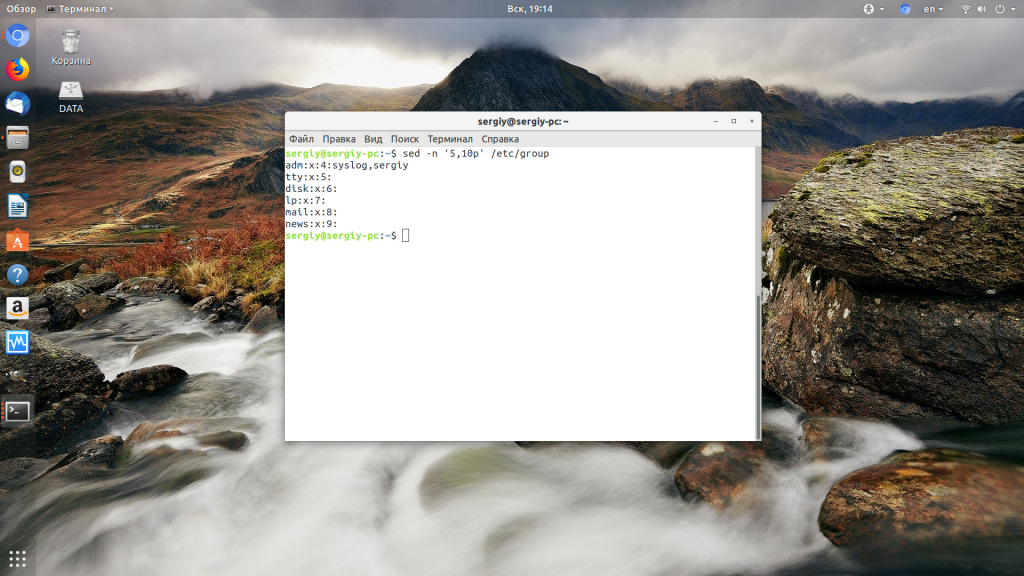
Команда sed в Linux
Сначала рассмотрим синтаксис команды:
$ sed опции -e команды файл
А вот её основные опции:
- -n, —quiet — не выводить содержимое буфера шаблона в конце каждой итерации;
- -e — команды, которые надо выполнить для редактирования;
- -f — прочитать команды редактирования из файла;
- -i — сделать резервную копию файла перед редактированием;
- -l — указать свою длину строки;
- -r — включить поддержку расширенного синтаксиса регулярных выражений;
- -s — если передано несколько файлов, рассматривать их как отдельные потоки, а не как один длинный.
Я понимаю, что сейчас всё очень сложно, но к концу статьи всё прояснится.
1. Как работает sed
Теперь нужно понять как работает команда sed. У утилиты есть два буфера, это активный буфер шаблона и дополнительный буфер. Оба изначально пусты. Программа выполняет заданные условия для каждой строки в переданном ей файле.
sed читает одну строку, удаляет из неё все завершающие символы и символы новой строки и помещает её в буфер шаблона. Затем выполняются переданные в параметрах команды, с каждой командой может быть связан адрес, это своего рода условие и команда выполняется только если подходит условие.
Когда всё команды будут выполнены и не указана опция -n, содержимое буфера шаблона выводится в стандартный поток вывода перед этим добавляется обратно символ перевода строки. если он был удален. Затем запускается новая итерация цикла для следующей строки.
Если не используются специальные команды, например, D, то после завершения одной итерации цикла содержимое буфера шаблона удаляется. Однако содержимое предыдущей строки хранится в дополнительном буфере и его можно использовать.
2. Адреса sed
Каждой команде можно передать адрес, который будет указывать на строки, для которых она будет выполнена:
- номер — позволяет указать номер строки, в которой надо выполнять команду;
- первая~шаг — команда будет выполняется для указанной в первой части сроки, а затем для всех с указанным шагом;
- $ — последняя строка в файле;
- /регулярное_выражение/ — любая строка, которая подходит по регулярному выражению. Модификатор l указывает, что регулярное выражение должно быть не чувствительным к регистру;
- номер, номер — начиная от строки из первой части и заканчивая строкой из второй части;
- номер, /регулярное_выражение/ — начиная от сроки из первой части и до сроки, которая будет соответствовать регулярному выражению;
- номер, +количество — начиная от номера строки указанного в первой части и еще плюс количество строк после него;
- номер, ~число — начиная от строки номер и до строки номер которой будет кратный числу.
Если для команды не был задан адрес, то она будет выполнена для всех строк. Если передан один адрес, команда будет выполнена только для строки по этому адресу. Также можно передать диапазон адресов. Тогда адреса разделяются запятой и команда будет выполнена для всех адресов диапазона.
3. Синтаксис регулярных выражений
Вы можете использовать такие же регулярные выражения, как и для Bash и популярных языков программирования. Вот основные операторы, которые поддерживают регулярные выражения sed Linux:
- * — любой символ, любое количество;
- \+ — как звездочка, только один символ или больше;
- \? — нет или один символ;
- \{i\} — любой символ в количестве i;
- \{i,j\} — любой символ в количестве от i до j;
- \{i,\} — любой символ в количестве от i и больше.
4. Команды sed
Если вы хотите пользоваться sed, вам нужно знать команды редактирования. Рассмотрим самые часто применяемые из них:
- # — комментарий, не выполняется;
- q — завершает работу сценария;
- d — удаляет буфер шаблона и запускает следующую итерацию цикла;
- p — вывести содержимое буфера шаблона;
- n — вывести содержимое буфера шаблона и прочитать в него следующую строку;
- s/что_заменять/на_что_заменять/опции — замена символов, поддерживаются регулярные выражения;
- y/символы/символы — позволяет заменить символы из первой части на соответствующие символы из второй части;
- w — записать содержимое буфера шаблона в файл;
- N — добавить перевод строки к буферу шаблона;
- D — если буфер шаблона не содержит новую строку, удалить его содержимое и начать новую итерацию цикла, иначе удалить содержимое буфера до символа перевода строки и начать новую итерацию цикла с тем, что останется;
- g — заменить содержимое буфера шаблона, содержимым дополнительного буфера;
- G — добавить новую строку к содержимому буфера шаблона, затем добавить туда же содержимое дополнительного буфера.
Утилите можно передать несколько команд, для этого их надо разделить точкой с запятой или использовать две опции -e. Теперь вы знаете всё необходимое и можно переходить к примерам.
Выражения в квадратных скобках и Классы символов
В дополнение к совпадению любого символа в заданной позиции в нашем регулярном выражении, мы также, используя выражения в квадратных скобках, можем задать совпадение единичного символа из указанного набора символов. С выражениями в квадратных скобках мы можем указать набор символов для соответствия (включая символы, которые в противном случае были бы истолкованы как метасимволы). В этом примере, используя набор из двух символов:
grep -h 'zip' dirlist*.txt bzip2 bzip2recover gzip
мы найдём любые строчки, содержащие строки «bzip» или «gzip».
Набор может содержать любое количество символов, а метасимволы теряют своё специальное значение, когда помещаются внутрь квадратных скобок. Тем не менее, есть два случая в которых метасимволы, используемые внутри квадратных скобок, имеют различные значения. Первый – это каретка (^), которая используется для указания отрицания; второй – это тире (-), которое используется для указания диапазона символов.
Отрицание
Если первым символом выражения в квадратных скобках является каретка (^), то остальные символы принимаются как набор символов, которые не должны присутствовать в заданной позиции символа. Сделаем это изменив наш предыдущий пример:
grep -h 'zip' dirlist*.txt bunzip2 gunzip funzip gpg-zip mzip p7zip preunzip prezip prezip-bin unzip unzipsfx
С активированным отрицанием, мы получили список файлов, которые содержат строку «zip», перед которой идёт любой символ, кроме «b» или «g»
Обратите внимание, что zip не был найден. Отрицаемый набор символов всё равно требует символ на заданной позиции, но символ не должен быть членом инвертированного набора.
Символ каретки вызывает отрицание только если он является первым символом внутри выражения в квадратных скобках; в противном случае, он теряет своё специальное назначение и становится обычным символом из набора.
Традиционные диапазоны символов
Если мы хотим сконструировать регулярное выражение, которое должно найти каждый файл из нашего списка, начинающийся на заглавную букву, мы можем сделать следующее:
grep -h '^' dirlist*.txt MAKEDEV GET HEAD POST VBoxClient X X11 Xorg ModemManager NetworkManager VBoxControl VBoxService
Суть в том, что мы разместили все 26 заглавных букв в выражение внутри квадратных скобок. Но мысль печатать их все не вызывает энтузиазма, поэтому есть другой путь:
grep -h '^' dirlist*.txt
Используя трёхсимвольный диапазон, мы можем сократить запись из 26 букв. Таким способом можно выразить любой диапазон символов, включая сразу несколько диапазонов, такие, как это выражение, которое соответствует всем именам файлов, начинающихся с букв и цифр:
grep -h '^' dirlist*.txt
В диапазонах символов мы видим, что символ чёрточки трактуется особым образом, поэтому как мы можем включить символ тире в выражение внутри квадратных скобок? Сделав его первым символом в выражении. Рассмотрим два примера:
grep -h '' dirlist*.txt
Это будет соответствовать каждому имени файла, содержащему заглавную букву. При этом:
grep -h '' dirlist*.txt
будет соответствовать каждому имени файла, содержащему тире, или заглавную «A», или заглавную «Z».
Классы символов POSIX
Подробнее о POSIX вы можете почитать в Википедии.
В POSIX имеются свои классы символов, которые вы можете использовать в регулярных выражениях:
| Класс символов | Описание |
|---|---|
| Алфавитно-цифровые символы. В ASCII эквивалентно: | |
| То же самое, что и , с дополнительным символом подчёркивания (_). | |
| Алфавитные символы. В ASCII эквивалентно: | |
| Включает символы пробела и табуляции. | |
| Управляющие коды ASCII. Включает ASCII символы с 0 до 31 и 127. | |
| Цифры от нуля до девяти. | |
| Видимые символы. В ASCII сюда включены символы с 33 по 126. | |
| Буквы в нижнем регистре. | |
| Символы пунктуации. В ASCII эквивалентно: [-!»#$%&'()*+,./:;?@_`{|}~] | |
| Печатные символы. Все символы в плюс символ пробела. | |
| Символы белых пробелов, включающих пробел, табуляцию, возврат каретки, новую строку, вертикальную табуляцию и разрыв страницы. В ASCII эквивалентно: | |
| Символы в верхнем регистре. | |
| Символы, используемые для выражения шестнадцатеричных чисел. В ASCII эквивалетно: |
В этих выражениях квадратные скобки и двоеточия являются частью записи класса символов (диапазонов).
Внимание: в зависимости от настроек локали, , , и другие буквенные диапазоны могут включать буквы вашего алфавита, например, русского. Т.е
может соответствовать не , а .
Basic Usage
In this tutorial, you’ll use to search the GNU General Public License version 3 for various words and phrases.
If you’re on an Ubuntu system, you can find the file in the folder. Copy it to your home directory:
If you’re on another system, use the command to download a copy:
You’ll also use the BSD license file in this tutorial. On Linux, you can copy that to your home directory with the following command:
If you’re on another system, create the file with the following command:
Now that you have the files, you can start working with .
In the most basic form, you use to match literal patterns within a text file. This means that if you pass a word to search for, it will print out every line in the file containing that word.
Execute the following command to use to search for every line that contains the word :
The first argument, , is the pattern you’re searching for, while the second argument, , is the input file you wish to search.
The resulting output will be every line containing the pattern text:
On some systems, the pattern you searched for will be highlighted in the output.
Common Options
By default, will search for the exact specified pattern within the input file and return the lines it finds. You can make this behavior more useful though by adding some optional flags to .
If you want to ignore the “case” of your search parameter and search for both upper- and lower-case variations, you can specify the or option.
Search for each instance of the word (with upper, lower, or mixed cases) in the same file as before with the following command:
The results contain: , , and :
If there was an instance with , that would have been returned as well.
If you want to find all lines that do not contain a specified pattern, you can use the or option.
Search for every line that does not contain the word in the BSD license with the following command:
You’ll see this output:
Since you did not specify the “ignore case” option, the last two items were returned as not having the word .
It is often useful to know the line number that the matches occur on. You can do this by using the or option. Re-run the previous example with this flag added:
You’ll see the following text:
Now you can reference the line number if you want to make changes to every line that does not contain . This is especially handy when working with source code.
Популярные теги
ubuntu
linux
ubuntu_18_04
settings
debian
setup
ubuntu_16_04
error
macos
redhat
mint
problems
windows
install
server
android
bash
ubuntu_18_10
hardware
desktop
update
wifi
files
убунту
web
rhel
docker
kali
network
security
windows_10
nvidia
ustanovka
software
apt
filesystem
python
stretch
issues
kde
password
shell
apache2
manjaro
mysql
wine
program
video_card
disk
ubuntu_20_04
package-management
apt-get
drivers
partition
performance
vpn
gnome
keyboard
terminal
kubuntu
usb
virtualbox
video
driver
games
wi_fi
nginx
macbook
kernel
installation
display
sound
delete
user
command-line
disk_space
freebsd
dual_boot
ubuntu_17_10
cron
fedora
lubuntu
oshibka
chrome
boot
for
scripting
ssh
mail
os
centos
zorin_os
firewall
git
zorin
bluetooth
hotkeys
kvm
mount
backup
Разница между grep, egrep, fgrep, pgrep, zgrep
Различные переключатели grep исторически были включены в различные двоичные файлы. В современных системах Linux вы найдете эти переключатели доступными в команде base grep, но часто дистрибутивы поддерживают и другие команды.
Со страницы руководства для grep:
egrep является эквивалентом grep -E
Этот переключатель будет интерпретировать шаблон как расширенное регулярное выражение . Есть множество разных вещей, которые вы можете сделать с этим, но вот пример того, как выглядит использование регулярного выражения с grep.
Давайте найдем в текстовом документе строки, которые содержат две последовательные буквы «р»:
$ egrep p\{2} fruits.txt
или
$ grep -E p\{2} fruits.txt
fgrep является эквивалентом grep -F
Этот переключатель будет интерпретировать шаблон как список фиксированных строк и попытаться сопоставить любую из них. Это полезно, когда вам нужно искать символы регулярного выражения. Это означает, что вам не нужно экранировать специальные символы, как если бы вы использовали обычный grep.
$ fgrep $ License.txt There is a $100 free for commercial use.
pgrep — это команда для поиска имени запущенного процесса в вашей системе и возврата соответствующих идентификаторов процесса. Например, вы можете использовать его, чтобы найти идентификатор процесса демона SSH:
$ pgrep sshd
По функциям это похоже на простую передачу вывода команды ‘ps’ в grep.
Вы можете использовать эту информацию, чтобы убить работающий процесс или устранить проблемы со службами, работающими в вашей системе.
zgrep используется для поиска сжатых файлов по шаблону. Это позволяет вам искать файлы внутри сжатого архива без необходимости сначала распаковывать этот архив, в основном экономя вам дополнительный шаг или два.
$ zgrep apple fruits.txt.gz
zgrep также работает с tar-файлами, но кажется, что он говорит только о том, удалось ли найти совпадение.
$ zgrep apple fruits.tar.gz
Мы упоминаем об этом, потому что файлы, сжатые с помощью gzip, обычно являются архивами tar.
Параметры grep
Опция -r
—recursive
Еще больше увеличит зону поисков опция -r, которая заставит команду grep рекурсивно обследовать все дерево указанной директории, то есть субдиректории, субдиректории субдиректорий, и так далее вплоть до файлов. Например:
grep -r menu /boot /boot/grub/grub.txt:Highlight the menu entry you want to edit and press 'e', then
/boot/grub/grub.txt:Press the key to return to the GRUB menu.
/boot/grub/menu.lst:# GRUB configuration file ‘/boot/grub/menu.lst’.
/boot/grub/menu.lst:gfxmenu (hd0,3)/boot/message
Опция -i
—ignore-case
Приказывает команде игнорировать регистр символов, таким образом, поиск будет производиться как среди заглавных, так и среди строчных букв.
Опция -c
—count
Эта опция не выводит строки, а подсчитывает количество строк, в которых обнаружен ОБРАЗЕЦ. Например:
grep -c root /etc/group 8
То есть в восьми строках файла /etc/group встречается сочетание символов root.
—line-number
При использовании этой опции вывод команды grep будет указывать номера строк, содержащих ОБРАЗЕЦ:
Опция -v
—invert-match
Выполняет работу, обратную обычной — выводит строки, в которых ОБРАЗЕЦ не встречается:
grep -v print /etc/printcap # # # for you (at least initially), such as apsfilter # (/usr/share/apsfilter/SETUP, used in conjunction with the # LPRng lpd daemon), or with the web interface provided by the # (if you use CUPS).
Опция -w
—word-regexp
Заставит команду grep искать только строки, содержащие все слово или фразу, составляющую ОБРАЗЕЦ. Например:
grep -w "длинная ко" example/*
Не дает вывода, то есть не находит строк, содержащих выражение «длинная ко». А вот команда:
grep -w "длинная коса" example/* example/alice.txt:длинная коса!
находит точное соответствие в файле alice.txt.
Опция -x
—line-regexp
Еще более строгая. Она отберет только те строки исследуемого файла или файлов, которые полностью совпадают с ОБРАЗЦОМ.
grep -x "1234" example/* example/123.txt:1234
Внимание: Мне попадались (на собственном компьютере) версии grep (например, GNU 2.5), в которых опция -x работала неадекватно. В то же время, другие версии (GNU 2.5.1) работали прекрасно
Если что-то не ладится с этой опцией, попробуйте другую версию, или обновите свою.
Опция -l
—files-with-matches
Команда grep с этой опцией не возвращает строки, содержащие ОБРАЗЕЦ, но сообщает лишь имена файлов, в которых данный образец найден:
grep -l 'Алиса' example/* example/alice.txt
Замечу, что сканирование каждого из заданных файлов продолжается только до первого совпадения с ОБРАЗЦОМ.
Опция -L
—files-without-match
Наоборот, сообщает имена тех файлов, где не встретился ОБРАЗЕЦ:
grep -L 'Алиса' example/* example/123.txt example/ast.txt
Как мы имели случай заметить, команда grep, в поисках соответствия ОБРАЗЦУ, просматривает только содержимое файлов, но не их имена. А так часто нужно найти файл по его имени или другим параметрам, например времени модификации! Тут нам придет на помощь простейший программный канал (pipe). При помощи знака программного канала — вертикальной черты (|) мы можем направить вывод команды ls, то есть список файлов в текущей директории, на ввод команды grep, не забыв указать, что мы, собственно, ищем (ОБРАЗЕЦ). Например:
ls | grep grep grep/ grep-ru.txt
Находясь в директории Desktop, мы «попросили» найти на Рабочем столе все файлы, в названии которых есть выражение «grep». И нашли одну директорию grep/ и текстовой файл grep-ru.txt, который я в данный момент и пишу.
Если мы хотим искать по другим параметрам файла, а не по его имени, то следует применить команду ls -l, которая выводит файлы со всеми параметрами:
ls -l | grep 2008-12-30 -rw-r--r-- 1 ya users 27 2008-12-30 08:06 123.txt drwxr-xr-x 2 ya users 4096 2008-12-30 08:49 example/ -rw-r--r-- 1 ya users 11931 2008-12-30 14:59 grep-ru.txt
И вот мы получили список всех файлов, модифицированных 30 декабря 2008 года.
Команда grep незаменима при просмотре логов и конфигурационных файлов. Классически примером использования команды grep стал программный канал с командой dmesg. Команда dmesg выводит те самые сообщения ядра, которые мы не успеваем прочесть во время загрузки компьютера. Допустим, мы подключили через USB порт новый принтер, и теперь хотим узнать, как ядро «окрестило» его. Дадим такую команду:
dmesg | grep -i usb
Опция -i необходима, так как usb часто пишется заглавными буквами. Проделайте этот пример самостоятельно — у него длинный вывод, который не укладывается в рамки данной статьи.
Примеры использования регулярных выражений
Теперь, когда мы рассмотрели основы и вы знаете как все работает, осталось закрепить полученные знания про регулярные выражения linux grep на практике. Два очень полезные спецсимвола — это ^ и $, которые обозначают начало и конец строки. Например, мы хотим получить всех пользователей, зарегистрированных в нашей системе, имя которых начинается на s. Тогда можно применить регулярное выражение «^s». Вы можете использовать команду egrep:
Если мы хотим отбирать строки по последнему символу в строке, что для этого можно использовать $. Например, выберем всех системных пользователей, без оболочки, записи о таких пользователях заканчиваются на false:
Чтобы вывести имена пользователей, которые начинаются на s или d используйте такое выражение:
Такой же результат можно получить, использовав символ «|». Первый вариант более пригоден для диапазонов, а второй чаще применяется для обычных или/или:
Теперь давайте выберем всех пользователей, длина имени которых составляет не три символа. Имя пользователя завершается двоеточием. Мы можем сказать, что оно может содержать любой буквенный символ, который должен быть повторен три раза, перед двоеточием: