Select
Содержание:
- Introduction to MySQL ORDER BY clause
- Сортировка записей по заданному списку значений
- Внешнее соединение
- Синтаксис
- Типы данных Access
- Синтаксис
- Пример — сортировка результатов по возрастанию
- SQL Справочник
- Синтаксис
- Пример — сортировка результатов по убыванию
- SQL Учебник
- SQL Учебник
- Example — Sorting Results in Ascending Order
- INNER JOIN
- SQL Учебник
- Пример — использование атрибутов ASC и DESC
- Пример — сортировка по относительной позиции
- SQL Учебник
Introduction to MySQL ORDER BY clause
When you use the statement to query data from a table, the result set is not sorted. It means that the rows in the result set can be in any order.
To sort the result set, you add the clause to the statement. The following illustrates the syntax of the clause:
In this syntax, you specify the one or more columns which you want to sort after the clause.
The stands for ascending and the stands for descending. You use to sort the result set in ascending order and to sort the result set in descending order.
This clause sorts the result set in ascending order:
And this clause sorts the result set in descending order:
By default, the clause uses if you don’t explicitly specify any option.
Therefore, the following clauses are equivalent:
and
If you want to sort the result set by multiple columns, you specify a comma-separated list of columns in the clause:
It is possible to sort the result by a column in ascending order, and then by another column in descending order:
In this case, the clause:
- First, sort the result set by the values in the in ascending order.
- Then, sort the sorted result set by the values in the in descending order. Note that the order of values in the will not change in this step, only the order of values in the changes.
Note that the clause is always evaluated after the and clause.
Сортировка записей по заданному списку значений
Представьте, что у вас есть записи, которые каким-то образом связаны с временем года. И вы храните эту информацию в одном из столбцов таблицы.
Очевидно, что, используя стандартный вариант сортировки (по алфавиту), расположить сезоны порядке «весна», «лето», «осень», «зима» не получится. Естественно, можно каждому времени года присвоить свой код, но есть и другой вариант решения – использовать функцию .
SELECT * FROM articles ORDER BY FIELD(a_season, "весна","лето","осень","зима")
Эта функция ищет значение, указанное в первом параметре, среди значений, перечисленных в остальных параметрах, и возвращает его порядковый номер. При выполнении запроса в первый параметр функции будут передаваться значения из поля и, таким образом, записи будут отсортированы в заданном нами порядке.
Внешнее соединение
В предшествующих примерах естественного соединения, результирующий набор содержал только те строки с одной таблицы, для которых имелись соответствующие строки в другой таблице. Но иногда кроме совпадающих строк бывает необходимым извлечь из одной или обеих таблиц строки без совпадений. Такая операция называется внешним соединением (outer join).
В примере ниже показана выборка всей информации для сотрудников, которые проживают и работают в одном и том же городе. Здесь используется таблица EmployeeEnh, которую мы создали в статье «Инструкция SELECT: расширенные возможности» при обсуждении оператора UNION.
Результат выполнения этого запроса:
В этом примере получение требуемых строк осуществляется посредством естественного соединения. Если бы в этот результат потребовалось включить сотрудников, проживающих в других местах, то нужно было применить левое внешнее соединение. Данное внешнее соединение называется левым потому, что оно возвращает все строки из таблицы с левой стороны оператора сравнения, независимо от того, имеются ли совпадающие строки в таблице с правой стороны. Иными словами, данное внешнее соединение возвратит строку с левой таблицы, даже если для нее нет совпадения в правой таблице, со значением NULL соответствующего столбца для всех строк с несовпадающим значением столбца другой, правой, таблицы. Для выполнения операции левого внешнего соединения компонент Database Engine использует оператор LEFT OUTER JOIN.
Операция правого внешнего соединения аналогична левому, но возвращаются все строки таблицы с правой части выражения. Для выполнения операции правого внешнего соединения компонент Database Engine использует оператор RIGHT OUTER JOIN.
В этом примере происходит выборка сотрудников (с включением полной информации) для таких городов, в которых сотрудники или только проживают (столбец City в таблице EmployeeEnh), или проживают и работают. Результат выполнения этого запроса:
Как можно видеть в результате выполнения запроса, когда для строки из левой таблицы (в данном случае EmployeeEnh) нет совпадающей строки в правой таблице (в данном случае Department), операция левого внешнего соединения все равно возвращает эту строку, заполняя значением NULL все ячейки соответствующего столбца для несовпадающего значения столбца правой таблицы. Применение правого внешнего соединения показано в примере ниже:
В этом примере происходит выборка отделов (с включением полной информации о них) для таких городов, в которых сотрудники или только работают, или проживают и работают. Результат выполнения этого запроса:
Кроме левого и правого внешнего соединения, также существует полное внешнее соединение, которое является объединением левого и правого внешних соединений. Иными словами, результирующий набор такого соединения состоит из всех строк обеих таблиц. Если для строки одной из таблиц нет соответствующей строки в другой таблице, всем ячейкам строки второй таблицы присваивается значение NULL. Для выполнения операции полного внешнего соединения используется оператор FULL OUTER JOIN.
Любую операцию внешнего соединения можно эмулировать, используя оператор UNION совместно с функцией NOT EXISTS. Таким образом, запрос, показанный в примере ниже, эквивалентен запросу левого внешнего соединения, показанному ранее. В данном запросе осуществляется выборка сотрудников (с включением полной информации) для таких городов, в которых сотрудники или только проживают или проживают и работают:
Первая инструкция SELECT объединения определяет естественное соединение таблиц EmployeeEnh и Department по столбцам соединения City и Location. Эта инструкция возвращает все города для всех сотрудников, в которых сотрудники и проживают и работают. Дополнительно, вторая инструкция SELECT объединения возвращает все строки таблицы EmployeeEnh, которые не отвечают условию в естественном соединении.
Синтаксис
Окно определяется с помощью обязательной инструкции OVER(). Давайте рассмотрим синтаксис этой инструкции:
SELECT Название функции (столбец для вычислений) OVER ( PARTITION BY столбец для группировки ORDER BY столбец для сортировки ROWS или RANGE выражение для ограничения строк в пределах группы )
Теперь разберем как поведет себя множество строк при использовании того или иного ключевого слова функции. А тренироваться будем на простой табличке содержащей дату, канал с которого пришел пользователь и количество конверсий:
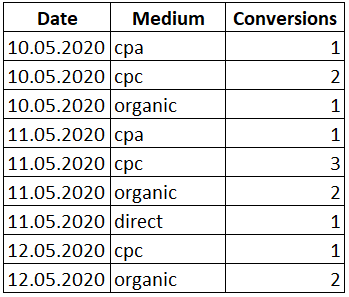
OVER()
Откроем окно при помощи OVER() и просуммируем столбец «Conversions»:
SELECT Date , Medium , Conversions , SUM(Conversions) OVER() AS 'Sum' FROM Orders
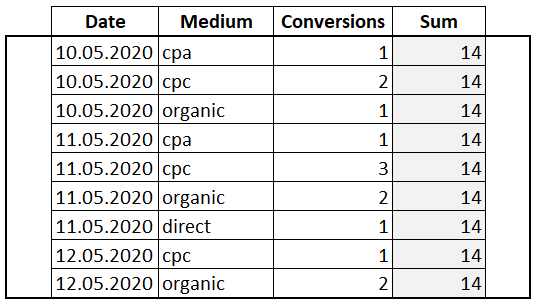
Мы использовали инструкцию OVER() без предложений. В таком варианте окном будет весь набор данных и никакая сортировка не применяется. Появился новый столбец «Sum» и для каждой строки выводится одно и то же значение 14. Это сквозная сумма всех значений колонки «Conversions».
PARTITION BY
Теперь применим инструкцию PARTITION BY, которая определяет столбец, по которому будет производиться группировка и является ключевой в разделении набора строк на окна:
SELECT Date , Medium , Conversions , SUM(Conversions) OVER(PARTITION BY Date) AS 'Sum' FROM Orders

Инструкция PARTITION BY сгруппировала строки по полю «Date». Теперь для каждой группы рассчитывается своя сумма значений столбца «Conversions».
ORDER BY
Попробуем отсортировать значения внутри окна при помощи ORDER BY:
SELECT Date , Medium , Conversions , SUM(Conversions) OVER(PARTITION BY Date ORDER BY Medium) AS 'Sum' FROM Orders
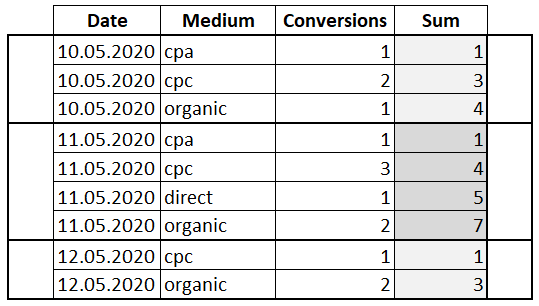
К предложению PARTITION BY добавилось ORDER BY по полю «Medium». Таким образом мы указали, что хотим видеть сумму не всех значений в окне, а для каждого значения «Conversions» сумму со всеми предыдущими. То есть мы посчитали нарастающий итог.
ROWS или RANGE
Инструкция ROWS позволяет ограничить строки в окне, указывая фиксированное количество строк, предшествующих или следующих за текущей.
Инструкция RANGE, в отличие от ROWS, работает не со строками, а с диапазоном строк в инструкции ORDER BY. То есть под одной строкой для RANGE могут пониматься несколько физических строк одинаковых по рангу.
Обе инструкции ROWS и RANGE всегда используются вместе с ORDER BY.
В выражении для ограничения строк ROWS или RANGE также можно использовать следующие ключевые слова:
- UNBOUNDED PRECEDING — указывает, что окно начинается с первой строки группы;
- UNBOUNDED FOLLOWING – с помощью данной инструкции можно указать, что окно заканчивается на последней строке группы;
- CURRENT ROW – инструкция указывает, что окно начинается или заканчивается на текущей строке;
- BETWEEN «граница окна» AND «граница окна» — указывает нижнюю и верхнюю границу окна;
- «Значение» PRECEDING – определяет число строк перед текущей строкой (не допускается в предложении RANGE).;
- «Значение» FOLLOWING — определяет число строк после текущей строки (не допускается в предложении RANGE).
Разберем на примере:
SELECT Date , Medium , Conversions , SUM(Conversions) OVER(PARTITION BY Date ORDER BY Conversions ROWS BETWEEN CURRENT ROW AND 1 FOLLOWING) AS 'Sum' FROM Orders

В данном случае сумма рассчитывается по текущей и следующей ячейке в окне. А последняя строка в окне имеет то же значение, что и столбец «Conversions», потому что больше не с чем складывать.
Комбинируя ключевые слова, вы можете подогнать диапазон работы оконной функции под вашу специфическую задачу.
Типы данных Access
Типы данных Access разделяются на следующие группы:
- Текстовый – максимально 255 байтов.
- Мемо — до 64000 байтов.
-
Числовой — 1,2,4 или 8 байтов.Для числового типа размер поля м.б. следующим:
- байт — целые числа от -0 до 255, занимает при хранении 1 байт
- целое — целые числа от -32768 до 32767, занимает 2 байта
- длинное целое — целые числа от -2147483648 до 2147483647, занимает 4 байта
- с плавающей точкой — числа с точностью до 6 знаков от –3,4*1038 до 3,4*1038, занимает 4 байта
- с плавающей точкой — числа с точностью от –1,797*10308 до 1,797*10308, занимает 8 байт
- Дата-время — 8 байтов
- Денежный — 8 байтов, данные о денежных суммах, хранящиеся с 4 знаками после запятой.
- Счетчик — уникальное длинное целое, генерируемое Access при создании каждой новой записи — 4 байта.
- Логический — логические данные 1бит.
- Поле объекта OLE — до 1 гигабайта, картинки, диаграммы и другие объекты OLE из приложений Windows. Объекты OLE могут быть связанными или внедренными.
- Гиперссылки — поле, в котором хранятся гиперссылки. Гиперссылка может быть либо типа UNC (стандартный формат для указания пути с включением сетевого сервера файлов), либо URL(адрес объекта, документа, страницы или объекта другого типа в Интернете или Интранете. Адрес URL определяет протокол для доступа и конечный адрес).
- Мастер подстановок — поле, позволяющее выбрать значение из другой таблицы Accesss или из списка значений, используя поле со списком. Чаще всего используется для ключевых полей. Имеет тот же размер, что и первичный ключ, являющийся также и полем подстановок, обычно 4 байта. (Первичный ключ – одно или несколько полей, комбинация значений которых однозначно определяет каждую запись в таблице Accesss. Не допускает неопределенных .Null. значений, всегда должен иметь уникальный индекс. Служит для связывания таблицы с вторичными ключами других таблиц).
Синтаксис
Синтаксис для предложения ORDER BY в PostgreSQL:
SELECT expressions
FROM tables
ORDER BY expression ;
Параметры или аргументы
- expressions
- Столбцы или вычисления, которые вы хотите получить.
- tables
- Таблицы, из которых вы хотите получить записи. В операторе FROM должна быть указана хотя бы одна таблица.
- WHERE conditions
- Необязательный. Условия, которые должны быть выполнены для записей, которые будут выбраны.
- ASC
- Необязательный. Он сортирует результирующий набор в порядке возрастания по expression (по умолчанию, если модификатор не указан).
- DESC
- Необязательный. Он сортирует результирующий набор в порядке убывания по expression.
- NULLS FIRST
- Необязательный. Если указано, все значения NULL сортируются перед значениями, отличных от NULL, в результирующем наборе.
- NULLS LAST
- Необязательный. Если указано, все значения NULL сортируются после значений, отличных от NULL, в результирующем наборе.
Пример — сортировка результатов по возрастанию
Чтобы отсортировать результаты в порядке возрастания, вы можете указать атрибут ASC. Если после поля в предложении ORDER BY не указано значение (ASC или DESC), порядок сортировки по умолчанию будет соответствовать возрастающему. Давайте рассмотрим это дальше.
В этом примере у нас есть таблица customers со следующими данными:
| customer_id | first_name | last_name | favorite_website |
|---|---|---|---|
| 4000 | Justin | Bieber | google.com |
| 5000 | Selena | Gomez | bing.com |
| 6000 | Mila | Kunis | yahoo.com |
| 7000 | Tom | Cruise | oracle.com |
| 8000 | Johnny | Depp | NULL |
| 9000 | Russell | Crowe | google.com |
Введите следующий SQL оператор.
PgSQL
SELECT *
FROM customers
ORDER BY last_name;
|
1 |
SELECT* FROMcustomers ORDERBYlast_name; |
Будет выбрано 6 записей. Вот результаты, которые вы должны получить.
| customer_id | first_name | last_name | favorite_website |
|---|---|---|---|
| 4000 | Justin | Bieber | google.com |
| 9000 | Russell | Crowe | google.com |
| 7000 | Tom | Cruise | oracle.com |
| 8000 | Johnny | Depp | NULL |
| 5000 | Selena | Gomez | bing.com |
| 6000 | Mila | Kunis | yahoo.com |
В этом примере будут возвращены все записи из таблицы customers, отсортированные по полю last_name в порядке возрастания, и будет эквивалентен следующему SQL предложению ORDER BY.
PgSQL
SELECT *
FROM customers
ORDER BY last_name ASC;
|
1 |
SELECT* FROMcustomers ORDERBYlast_nameASC; |
Большинство программистов пропускают атрибут ASC при сортировке в порядке возрастания.
SQL Справочник
SQL Ключевые слова
ADD
ADD CONSTRAINT
ALTER
ALTER COLUMN
ALTER TABLE
ALL
AND
ANY
AS
ASC
BACKUP DATABASE
BETWEEN
CASE
CHECK
COLUMN
CONSTRAINT
CREATE
CREATE DATABASE
CREATE INDEX
CREATE OR REPLACE VIEW
CREATE TABLE
CREATE PROCEDURE
CREATE UNIQUE INDEX
CREATE VIEW
DATABASE
DEFAULT
DELETE
DESC
DISTINCT
DROP
DROP COLUMN
DROP CONSTRAINT
DROP DATABASE
DROP DEFAULT
DROP INDEX
DROP TABLE
DROP VIEW
EXEC
EXISTS
FOREIGN KEY
FROM
FULL OUTER JOIN
GROUP BY
HAVING
IN
INDEX
INNER JOIN
INSERT INTO
INSERT INTO SELECT
IS NULL
IS NOT NULL
JOIN
LEFT JOIN
LIKE
LIMIT
NOT
NOT NULL
OR
ORDER BY
OUTER JOIN
PRIMARY KEY
PROCEDURE
RIGHT JOIN
ROWNUM
SELECT
SELECT DISTINCT
SELECT INTO
SELECT TOP
SET
TABLE
TOP
TRUNCATE TABLE
UNION
UNION ALL
UNIQUE
UPDATE
VALUES
VIEW
WHERE
MySQL Функции
Функции строк
ASCII
CHAR_LENGTH
CHARACTER_LENGTH
CONCAT
CONCAT_WS
FIELD
FIND_IN_SET
FORMAT
INSERT
INSTR
LCASE
LEFT
LENGTH
LOCATE
LOWER
LPAD
LTRIM
MID
POSITION
REPEAT
REPLACE
REVERSE
RIGHT
RPAD
RTRIM
SPACE
STRCMP
SUBSTR
SUBSTRING
SUBSTRING_INDEX
TRIM
UCASE
UPPER
Функции чисел
ABS
ACOS
ASIN
ATAN
ATAN2
AVG
CEIL
CEILING
COS
COT
COUNT
DEGREES
DIV
EXP
FLOOR
GREATEST
LEAST
LN
LOG
LOG10
LOG2
MAX
MIN
MOD
PI
POW
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SUM
TAN
TRUNCATE
Функции дат
ADDDATE
ADDTIME
CURDATE
CURRENT_DATE
CURRENT_TIME
CURRENT_TIMESTAMP
CURTIME
DATE
DATEDIFF
DATE_ADD
DATE_FORMAT
DATE_SUB
DAY
DAYNAME
DAYOFMONTH
DAYOFWEEK
DAYOFYEAR
EXTRACT
FROM_DAYS
HOUR
LAST_DAY
LOCALTIME
LOCALTIMESTAMP
MAKEDATE
MAKETIME
MICROSECOND
MINUTE
MONTH
MONTHNAME
NOW
PERIOD_ADD
PERIOD_DIFF
QUARTER
SECOND
SEC_TO_TIME
STR_TO_DATE
SUBDATE
SUBTIME
SYSDATE
TIME
TIME_FORMAT
TIME_TO_SEC
TIMEDIFF
TIMESTAMP
TO_DAYS
WEEK
WEEKDAY
WEEKOFYEAR
YEAR
YEARWEEK
Функции расширений
BIN
BINARY
CASE
CAST
COALESCE
CONNECTION_ID
CONV
CONVERT
CURRENT_USER
DATABASE
IF
IFNULL
ISNULL
LAST_INSERT_ID
NULLIF
SESSION_USER
SYSTEM_USER
USER
VERSION
SQL Server функции
Функции строк
ASCII
CHAR
CHARINDEX
CONCAT
Concat with +
CONCAT_WS
DATALENGTH
DIFFERENCE
FORMAT
LEFT
LEN
LOWER
LTRIM
NCHAR
PATINDEX
QUOTENAME
REPLACE
REPLICATE
REVERSE
RIGHT
RTRIM
SOUNDEX
SPACE
STR
STUFF
SUBSTRING
TRANSLATE
TRIM
UNICODE
UPPER
Функции чисел
ABS
ACOS
ASIN
ATAN
ATN2
AVG
CEILING
COUNT
COS
COT
DEGREES
EXP
FLOOR
LOG
LOG10
MAX
MIN
PI
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SQUARE
SUM
TAN
Функции дат
CURRENT_TIMESTAMP
DATEADD
DATEDIFF
DATEFROMPARTS
DATENAME
DATEPART
DAY
GETDATE
GETUTCDATE
ISDATE
MONTH
SYSDATETIME
YEAR
Функции расширений
CAST
COALESCE
CONVERT
CURRENT_USER
IIF
ISNULL
ISNUMERIC
NULLIF
SESSION_USER
SESSIONPROPERTY
SYSTEM_USER
USER_NAME
MS Access функции
Функции строк
Asc
Chr
Concat with &
CurDir
Format
InStr
InstrRev
LCase
Left
Len
LTrim
Mid
Replace
Right
RTrim
Space
Split
Str
StrComp
StrConv
StrReverse
Trim
UCase
Функции чисел
Abs
Atn
Avg
Cos
Count
Exp
Fix
Format
Int
Max
Min
Randomize
Rnd
Round
Sgn
Sqr
Sum
Val
Функции дат
Date
DateAdd
DateDiff
DatePart
DateSerial
DateValue
Day
Format
Hour
Minute
Month
MonthName
Now
Second
Time
TimeSerial
TimeValue
Weekday
WeekdayName
Year
Другие функции
CurrentUser
Environ
IsDate
IsNull
IsNumeric
SQL ОператорыSQL Типы данныхSQL Краткий справочник
Синтаксис
Синтаксис оператора ORDER BY в MySQL:
SELECT expressions
FROM tables
ORDER BY expression ;
Параметры или аргументы
expressions — столбцы или вычисления, которые вы хотите получить.
tables — таблицы, из которых вы хотите получить записи. Должна быть хотя бы одна таблица, перечисленная в операторе FROM.
WHERE conditions — необязательный. Условия, которые должны быть выполнены для выбранных записей.ASC — необязательный. Сортирует результирующий набор по expression в порядке возрастания (по умолчанию, если атрибут не указан).DESC — необязательный. Сортирует результирующий набор по expression в порядке убывания.
Пример — сортировка результатов по убыванию
При сортировке набора результатов в порядке убывания вы используете атрибут DESC в предложении ORDER BY. Давайте внимательнее посмотрим.
В этом примере у нас есть таблица suppliers со следующими данными:
| supplier_id | supplier_name | city | state |
|---|---|---|---|
| 100 | Yandex | Moscow | Russian |
| 200 | Lansing | Michigan | |
| 300 | Oracle | Redwood City | California |
| 400 | Bing | Redmond | Washington |
| 500 | Yahoo | Sunnyvale | Washington |
| 600 | DuckDuckGo | Paoli | Pennsylvania |
| 700 | Qwant | Paris | France |
| 800 | Menlo Park | California | |
| 900 | Electronic Arts | San Francisco | California |
Введите следующий SQL оператор.
PgSQL
SELECT *
FROM suppliers
WHERE supplier_id > 40
ORDER BY supplier_id DESC;
|
1 |
SELECT* FROMsuppliers WHEREsupplier_id>40 ORDERBYsupplier_idDESC; |
Будет выбрано 5 записей. Вот результаты, которые вы должны получить.
| supplier_id | supplier_name | city | state |
|---|---|---|---|
| 900 | Electronic Arts | San Francisco | California |
| 800 | Menlo Park | California | |
| 700 | Qwant | Paris | France |
| 600 | DuckDuckGo | Paoli | Pennsylvania |
| 500 | Yahoo | Sunnyvale | Washington |
В этом примере будет отсортирован набор результатов по полю supplier_id в порядке убывания.
SQL Учебник
SQL ГлавнаяSQL ВведениеSQL СинтаксисSQL SELECTSQL SELECT DISTINCTSQL WHERESQL AND, OR, NOTSQL ORDER BYSQL INSERT INTOSQL Значение NullSQL Инструкция UPDATESQL Инструкция DELETESQL SELECT TOPSQL MIN() и MAX()SQL COUNT(), AVG() и …SQL Оператор LIKESQL ПодстановочныйSQL Оператор INSQL Оператор BETWEENSQL ПсевдонимыSQL JOINSQL JOIN ВнутриSQL JOIN СлеваSQL JOIN СправаSQL JOIN ПолноеSQL JOIN СамSQL Оператор UNIONSQL GROUP BYSQL HAVINGSQL Оператор ExistsSQL Операторы Any, AllSQL SELECT INTOSQL INSERT INTO SELECTSQL Инструкция CASESQL Функции NULLSQL ХранимаяSQL Комментарии
SQL Учебник
SQL ГлавнаяSQL ВведениеSQL СинтаксисSQL SELECTSQL SELECT DISTINCTSQL WHERESQL AND, OR, NOTSQL ORDER BYSQL INSERT INTOSQL Значение NullSQL Инструкция UPDATESQL Инструкция DELETESQL SELECT TOPSQL MIN() и MAX()SQL COUNT(), AVG() и …SQL Оператор LIKESQL ПодстановочныйSQL Оператор INSQL Оператор BETWEENSQL ПсевдонимыSQL JOINSQL JOIN ВнутриSQL JOIN СлеваSQL JOIN СправаSQL JOIN ПолноеSQL JOIN СамSQL Оператор UNIONSQL GROUP BYSQL HAVINGSQL Оператор ExistsSQL Операторы Any, AllSQL SELECT INTOSQL INSERT INTO SELECTSQL Инструкция CASESQL Функции NULLSQL ХранимаяSQL Комментарии
Example — Sorting Results in Ascending Order
To sort your results in ascending order, you can specify the ASC attribute. If no value (ASC or DESC) is provided after a field in the ORDER BY clause, the sort order will default to ascending order. Let’s explore this further.
In this example, we have a table called customers with the following data:
| customer_id | last_name | first_name | favorite_website |
|---|---|---|---|
| 4000 | Jackson | Joe | techonthenet.com |
| 5000 | Smith | Jane | digminecraft.com |
| 6000 | Ferguson | Samantha | bigactivities.com |
| 7000 | Reynolds | Allen | checkyourmath.com |
| 8000 | Anderson | Paige | NULL |
| 9000 | Johnson | Derek | techonthenet.com |
Enter the following SQL statement:
Try It
SELECT * FROM customers ORDER BY last_name;
There will be 6 records selected. These are the results that you should see:
| customer_id | last_name | first_name | favorite_website |
|---|---|---|---|
| 8000 | Anderson | Paige | NULL |
| 6000 | Ferguson | Samantha | bigactivities.com |
| 4000 | Jackson | Joe | techonthenet.com |
| 9000 | Johnson | Derek | techonthenet.com |
| 7000 | Reynolds | Allen | checkyourmath.com |
| 5000 | Smith | Jane | digminecraft.com |
This example would return all records from the customers sorted by the last_name field in ascending order and would be equivalent to the following SQL ORDER BY clause:
Try It
SELECT * FROM customers ORDER BY last_name ASC;
INNER JOIN
Самый простой вид соединения INNER JOIN – внутреннее соединение. Этот вид джойна выведет только те строки, если условие соединения выполняется (является истинным, т.е. TRUE). В запросах необязательно прописывать INNER – если написать только JOIN, то СУБД по умолчанию выполнить именно внутреннее соединение.
Давайте соединим таблицы из нашего примера, чтобы ответить на вопрос, в каких отделах работают сотрудники (читайте комментарии в запросе для понимания синтаксиса).
SELECT
— Перечисляем столбцы, которые хотим вывести
Сотрудники.id,
Сотрудники.Имя,
Отделы.Наименование AS Отдел — выводим наименование отдела и переименовываем столбец через as
FROM
— таблицы для соединения перечисляем в предложении from
Сотрудники
— обратите внимание, что мы не указали вид соединения, поэтому выполнится внутренний (inner) джойн
JOIN Отделы
— условия соединения прописываются после ON
— условий может быть несколько, записанных через and, or и т.п.
ON Сотрудники.Отдел = Отделы.id
Получим следующий результат:
| id | Имя | Отдел |
|---|---|---|
| 1 | Юлия | Кухня |
| 2 | Федор | Бар |
| 4 | Светлана | Бар |
Из результатов пропал сотрудник Алексей (id = 3), потому что условие «Сотрудники.Отдел = Отделы.id» не будет истинно для этой сроки из таблицы «Сотрудники» с каждой строкой из таблицы «Отделы». По той же логике в результате нет отдела «Администрация». Попробую это визуализировать (зеленные линии – условие TRUE, иначе линия красная):
Если не углубляться в то, как внутреннее соединение работает под капотом СУБД, то происходит примерно следующее:
- Каждая строка из одной таблицы сравнивается с каждой строкой из другой таблицы
- Строка возвращается, если условие сравнения является истинным
Если для одной или нескольких срок из левой таблицы (в рассмотренном примере левой таблицей является «Сотрудники», а правой «Отделы») истинным условием соединения будут являться одна или несколько срок из правой таблицы, то строки умножат друг друга (повторятся). В нашем примере так произошло для отдела с id = 2, поэтому строка из таблицы «Отделы» повторилась дважды для Федора и Светланы.Перемножение таблиц проще ощутить на таком примере, где условие соединения будет всегда возвращать TRUE, например 1=1:
SELECT *
FROM
Сотрудники
JOIN Отделы
ON 1=1
В результате получится 12 строк (4 сотрудника * 3 отдела), где для каждого сотрудника подтянется каждый отдел.
Также хочу сразу отметить, что в соединении может участвовать сколько угодно таблиц, можно таблицу соединить даже саму с собой (в аналитических задачах это не редкость)
Какая из таблиц будет правой или левой не имеется значения для INNER JOIN (для внешних соединений типа LEFT JOIN или RIGHT JOIN это важно. Читайте далее)
Пример соединения 4-х таблиц:
SELECT *
FROM
Table_1
JOIN Table_2
ON Table_1.Column_1 = Table_2.Column_1
JOIN Table_3
ON
Table_1.Column_1 = Table_3.Column_1
AND Table_2.Column_1 = Table_3.Column_1
JOIN Table_1 AS Tbl_1 -- Задаем алиас для таблицы, чтобы избежать неоднозначности
-- Если в Table_1.Column_1 хранится порядковый номер какого-то объекта,
-- то так можно присоединить следующий по порядку объект
ON Table_1.Column_1 = Tbl_1.Column_1 + 1
Как видите, все просто, прописываем новый джойн после завершения условий предыдущего соединения
Обратите внимание, что для Table_3 указано несколько условий соединения с двумя разными таблицами, а также Table_1 соединяется сама с собой по условию с использованием сложения.Строки, которые выведутся запросом, должны совпасть по всем условиям. Например:
- Строка из Table_1 соединилась со строкой из Table_2 по условию первого JOIN. Давайте назовем ее «объединенной строкой» из двух таблиц;
- Объединенная строка успешно соединилась с Table_3 по условию второго JOIN и теперь состоит из трех таблиц;
- Для объединенной строки не нашлось строки из Table_1 по условию третьего JOIN, поэтому она не выводится вообще.
SQL Учебник
SQL ГлавнаяSQL ВведениеSQL СинтаксисSQL SELECTSQL SELECT DISTINCTSQL WHERESQL AND, OR, NOTSQL ORDER BYSQL INSERT INTOSQL Значение NullSQL Инструкция UPDATESQL Инструкция DELETESQL SELECT TOPSQL MIN() и MAX()SQL COUNT(), AVG() и …SQL Оператор LIKESQL ПодстановочныйSQL Оператор INSQL Оператор BETWEENSQL ПсевдонимыSQL JOINSQL JOIN ВнутриSQL JOIN СлеваSQL JOIN СправаSQL JOIN ПолноеSQL JOIN СамSQL Оператор UNIONSQL GROUP BYSQL HAVINGSQL Оператор ExistsSQL Операторы Any, AllSQL SELECT INTOSQL INSERT INTO SELECTSQL Инструкция CASESQL Функции NULLSQL ХранимаяSQL Комментарии
Пример — использование атрибутов ASC и DESC
При сортировке набора результатов с помощью SQL предложения ORDER BY вы можете использовать атрибуты ASC и DESC в одном операторе SELECT.
В этом примере давайте использовать ту же таблицу products, что и в предыдущем примере.
| product_id | product_name | category_id |
|---|---|---|
| 1 | Pear | 50 |
| 2 | Banana | 50 |
| 3 | Orange | 50 |
| 4 | Apple | 50 |
| 5 | Bread | 75 |
| 6 | Sliced Ham | 25 |
| 7 | Kleenex | NULL |
Теперь введите следующий SQL оператор.
PgSQL
SELECT *
FROM products
WHERE product_id <>
ORDER BY category_id DESC,
product_name ASC;
|
1 |
SELECT* FROMproducts WHEREproduct_id<> ORDERBYcategory_idDESC, product_nameASC; |
Будет выбрано 6 записей. Вот результаты, которые вы должны получить.
| product_id | product_name | category_id |
|---|---|---|
| 5 | Bread | 75 |
| 4 | Apple | 50 |
| 2 | Banana | 50 |
| 3 | Orange | 50 |
| 1 | Pear | 50 |
| 6 | Sliced Ham | 25 |
В этом примере возвращаются записи, отсортированные по полю category_id в порядке убывания, а вторичная сортировка — по полю product_name в порядке возрастания.
Пример — сортировка по относительной позиции
Вы также можете использовать SQLite оператор ORDER BY для сортировки по относительной позиции в результирующем наборе, где первое поле в наборе результатов равно 1. Следующее поле равно 2 и т.д.
Например:
PgSQL
SELECT employee_id,
last_name,
first_name
FROM employees
WHERE employee_id > 45
ORDER BY 3 DESC;
|
1 |
SELECTemployee_id, last_name, first_name FROMemployees WHEREemployee_id>45 ORDERBY3DESC; |
Этот SQLite пример ORDER BY будет возвращать результирующий набор, отсортированный по полю first_name в порядке убывания, поскольку поле first_name находится в позиции № 3 в результирующем наборе и будет эквивалентно следующему ORDER BY:
PgSQL
SELECT employee_id,
last_name,
first_name
FROM employees
WHERE employee_id > 45
ORDER BY first_name DESC;
|
1 |
SELECTemployee_id, last_name, first_name FROMemployees WHEREemployee_id>45 ORDERBYfirst_nameDESC; |
SQL Учебник
SQL ГлавнаяSQL ВведениеSQL СинтаксисSQL SELECTSQL SELECT DISTINCTSQL WHERESQL AND, OR, NOTSQL ORDER BYSQL INSERT INTOSQL Значение NullSQL Инструкция UPDATESQL Инструкция DELETESQL SELECT TOPSQL MIN() и MAX()SQL COUNT(), AVG() и …SQL Оператор LIKESQL ПодстановочныйSQL Оператор INSQL Оператор BETWEENSQL ПсевдонимыSQL JOINSQL JOIN ВнутриSQL JOIN СлеваSQL JOIN СправаSQL JOIN ПолноеSQL JOIN СамSQL Оператор UNIONSQL GROUP BYSQL HAVINGSQL Оператор ExistsSQL Операторы Any, AllSQL SELECT INTOSQL INSERT INTO SELECTSQL Инструкция CASESQL Функции NULLSQL ХранимаяSQL Комментарии


