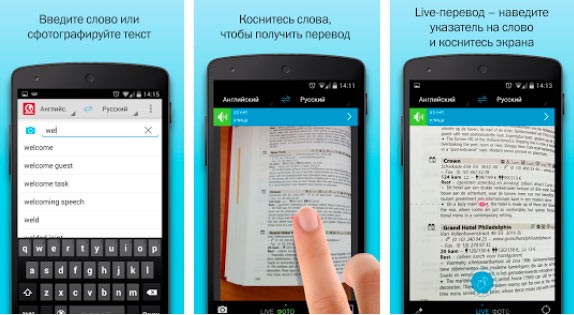
Переводчик с фото онлайн: для компьютера и смартфона (перевод того, что попало в камеру/объектив телефона)
Содержание:
- Как в «Ворде» сделать из текста картинку: простейший метод
- Определить участки изображения, в которых присутствует текст, используя MSER
- Camera to PDF – бесплатный сканер документов
- ABBYY Screenshot Reader
- Что такое OCR?
- Что такое OCR в антиплагиате?
- Особенности
- Извлечение текста с помощью OneNote
- Суть процедуры
- Как подготовить изображения для распознавания
- Как извлечь текст из изображений с помощью ABBY FineReader
- Text Scanner распознаватель текста
- Программы для преобразования текста с фото в Word
- Перевод текста с фото на IPhone
- Шаг 1: разобрать данные
- Сканирование фотографий
- Что делать с рукописным вводом?
- Текст извлечен с помощью OCR – что это значит?
- Раздел ИСТОРИЯ для пакетного экспорта текста
- (a9t9) Бесплатное приложение для распознавания Windows
- Вывод печатных форм с запросом данных в форму «Печать документов» из подсистемы БСП «Печать».
Как в «Ворде» сделать из текста картинку: простейший метод
Таким образом, сразу же возникают вопросы, связанные с преобразованием всего текста. В редакторе Word для этого имеется достаточно простой встроенный инструмент. Как многие уже, наверное, догадались, речь идет о том, чтобы произвести сохранение вордовского документа в другом, отличном от стандартного, формате. В данном случае имеется в виду экспорт в универсальный формат PDF, поскольку он большей частью является графическим, хотя четкой границы между его отнесением и к графике, и к тексту на сегодняшний день не существует. Как сделать картинку из текста?
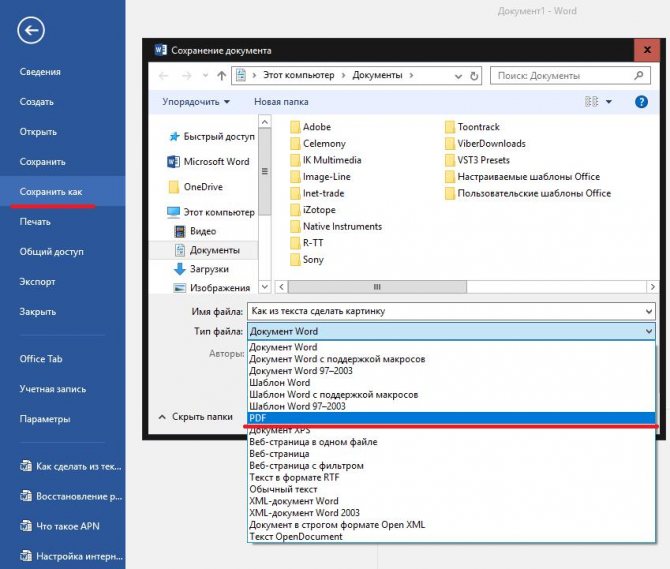
Просто в файловом меню выберите пункт «Сохранить как…», а в поле типа документа установите формат PDF.
Но и тут следует четко понимать, что при наличии необходимых программ отредактировать такой материал тоже можно. А вот если под рукой таких средств не имеется, просмотр содержимого файла будет производиться либо в любом приложении для просмотра графики, либо в самом обычном веб-браузере без возможности изменения текста.
Определить участки изображения, в которых присутствует текст, используя MSER
В функции MSER детектор хорошо работает для поиска регионов с содержанием текстовых символов. Она неплохо выполняет свою работу, поскольку последовательные цвет и высокая контрастность текста приводит к прочным профилям интенсивности.
Используя функцию detectMSERFeatures найдем образы и сюжет всех регионов
Обратите внимание, что функция также выделяет много нетекстовых областей:
colorImage = imread('handicapSign.jpg');
I = rgb2gray(colorImage);
% Detect MSER regions.
= detectMSERFeatures(I, ...
'RegionAreaRange',,'ThresholdDelta',4);
figure
imshow(I)
hold on
plot(mserRegions, 'showPixelList', true,'showEllipses',false)
title('MSER regions')
hold off
Camera to PDF – бесплатный сканер документов
Простейшее приложение, которое на основе снимков с камеры смартфона или из галереи создает файл PDF. Пакетный режим как таковой отсутствует, но при создании нового документа допускается добавление очередных снимков.
Все действие разбивается на три этапа. Первый: выбор снимка из галереи или при помощи собственного приложения для камеры, беззвучного и с полностью отсутствующими настройками. При необходимости в текущий документ таким же образом добавляются новые страницы.
Второй этап — создание файла формата PDF. Файл сохраняется на карте памяти по следующему адресу: mnt/sdcard/Android/data/com.thomasgravina.pdfscanner/files. Опции редактирования пути нет.
Третий этап является опциональным: отправка документа при помощи обычного «send to». Какой-либо обработки изображения не предусмотрено. Поэтому вряд ли приложение сможет заинтересовать как серьезный «сканер» для работы с документами.
ABBYY Screenshot Reader
ABBYY Screenshot Reader — программа для распознавания текста на графических изображениях и скриншотах. Полученный файл можно сохранить в любом удобном для пользователей формате. Всего утилита распознает тексты на 179 языках.
Приложение имеет полную совместимость с операционной системой Windows (32/64 бит). Для загрузки доступна полностью русская версия. Чтобы установит и запустить утлиту требуется ОС Windows 7 и новее. Модель распространения ABBYY Screenshot Reader — условно-бесплатная. Чтобы получить полную версию программы, необходимо купить лицензию стоимостью 490 рублей. Для тестирования основных возможностей доступна бесплатная демо-версия приложения. Срок действия ознакомительной версии утилиты — 15 дней.
После запуска программы ABBYY Screenshot Reader откроется небольшое окно, в котором выполняется управление основными функциями.
Здесь пользователи могут выбрать формат снимков: определенная область экрана, захват только открытого окна приложения, снимок всего экрана, захват экрана с отсрочкой. Также здесь можно выбрать язык текста, который используется на изображении. В строке передать пользователям нужно выбрать, какое действие выполнит программа: поместит текст в буфер обмена, в файл Microsoft Word, в таблицу и т.д.
Чтобы сделать снимок экрана с текстом, необходимо воспользоваться сочетанием клавиш «Alt + Enter». Захват будет выполнен в зависимости от того, какой формат был выбран пользователями. После того, как снимок сделан, текст с изображения будет добавлен в буфер обмена. На этом этапе пользователям необходимо открыть любой редактор (стандартный блокнот Windows, Word и т.д.) и вставить туда текст.
Преимущества ABBYY Screenshot Reader:
- простой и удобный интерфейс на русском языке;
- возможность захвата нужной области экрана для распознавания текста;
- поддерживается возможность передачи текста в текстовый редактор сразу после создания снимка.
Недостатки:
не поддерживается возможность работы со сканером.
Что такое OCR?
OCR (англ. optical character recognition, оптическое распознавание символов) — это технология автоматического анализа текста и превращения его в данные, которые может обрабатывать компьютер. Когда человек читает текст, он распознает символы с помощью глаз и мозга. У компьютера в роли глаз выступает камера сканера, которая создает графическое изображение текстовой страницы (например, в формате JPG). Для компьютера нет разницы между фотографией текста и фотографией дома: и то, и другое — набор пикселей.
Именно OCR превращает изображение текста в текст. А с текстом уже можно делать что угодно.
Что такое OCR в антиплагиате?
Давайте теперь поподробнее разберем, что такое OCR в антиплагиате. На самом деле, сам механизм распознавания текста остался неизменным, но приобрел новое значение. С помощью OCR система Антиплагиат уже не просто сканирует исходный машинописный текст, а сначала трансформирует его в изображение, делая своего рода фотографию, а уже потом производит оптическое распознавание. Распознанный текст в конечном итоге и подвергается проверке на уникальность. Звучит достаточно сложно, так зачем же такие трудности?
Еще одной фишкой модуля OCR является то, что теперь распознаваться будут изображения и таблицы, включенные в документ. Если раньше таблицы и изображения системой не распознавались и воспринимались антиплагиатом как уникальный текст, то теперь дела обстоят иначе – проверке будут подвергаться все элементы курсовой или дипломной работы.
Конечно, как и любые другие поисковые модули, модуль OCR не бесплатный. Доступен он только в системе Антиплагиат.ВУЗ или же его можно подключить на одну проверку в Антиплагиат.ру, минимальная цена которой 270 рублей.
Для использования OCR во время проверки работы необходимо поставить галочку напротив «Использовать распознавание текста (OCR)».
Разработчики антиплагиата предупреждают, что при проверке документа с помощью распознавания текста, скорость обработки файла может значительно увеличится.
Особенности
Каждая программа способна работать только с теми символами, которые были занесены в ее базу, только их она распознает.
В программу может быть внесено несколько алфавитов, как уже писалось выше, поэтому, при выборе подходящего софта проверьте, что бы он работал с языком, на котором напечатан текст на вашей картинке.
Если речь идет о не слишком популярных и визуально нестандартных языках, то найти подходящий софт может быть непросто.
Чем сложнее форматирование или расположение букв на фотографии, тем сложнее программе правильно распознать текст, и тем больше будет ошибок.
Ведь иногда в таком случае неточности могут возникнуть уже на стадии определения местоположения печатных символов на картинке.
Распознавание текста, напечатанного на нестандартном языке, происходит с ошибками. Причем, часто чем сложнее этот текст, тем больше ошибок может быть, так как алгоритмы распознавания могут в этом случае работать неточно.
При определении буквы программа использует определенный «алгоритм» сравнений с ее основными чертами – расположением и размером элементов (некоторые утилиты также учитывают соседние распознанные буквы и лексическую сочетаемость).
Благодаря этой особенности, даже если небольшая часть буквы стерлась или изменена, она все еще может быть распознана.
Единственный минус данного способа в том, что когда букву не удается распознать, задействуются все алфавиты из базы для определения, и в результате может быть обнаружено больше сходств с буквой, например, английского алфавита, хотя текст напечатан на русском.
Перед началом процесса распознавания, обратите внимание на качество фото. Лучше всего определяется текст с отсканированных изображений документов, скриншотов
Лучше всего определяется текст с отсканированных изображений документов, скриншотов.
Более или менее нормально может быть определен и сфотографированный на камеру текст.
Хуже всего распознаются материалы с фото плохого качества, сделанного под углом, особенно если имеет место сложное форматирование.
Художественные шрифты не распознаются.
<Рис. 3 Онлайн-сервис>
Извлечение текста с помощью OneNote
OneNote OCR уже на протяжении нескольких лет остается одной из самых лучших программ для распознавания текста. Однако, распознавание это одна из тех менее известных функций, которые пользователи редко используют, но как только вы начнете ее использовать, вы будете удивлены тем, насколько быстрой и точной она может быть. Действительно, способность извлекать текст — одна из особенностей, которая делает OneNote лучше Evernote.
Это стандартная программа, скорее всего вам не придется устанавливать ее самостоятельно. Найдите ее на компьютере в папке Microsoft Office или же с помощью поиска на панели «Пуск». Запустите программу.
Инструкции по извлечению текста:
-
Шаг 1. Откройте любую страницу в OneNote, желательно пустую.
-
Шаг 2. Перейдите в меню «Вставка»> «Изображения» и выберите файл изображения и настройте язык распознавания.
- Шаг 3. Щелкните правой кнопкой мыши по вставленному изображению и выберите «Копировать текст с изображения». Он сохранится в буфере обмена.
Копируем текст с изображения
Теперь вы можете вставить его куда угодно. Удалите вставленное изображение, если оно вам больше не нужно.
Вставляем текст куда угодно
Суть процедуры
О каком же процессе в данном случае вообще идет речь? Обработка картинки или фото для того, чтобы текст, запечатленный на ней, автоматически был переведен в текстовый формат.
Тоесть, технически процесс происходит следующим образом: пользователь загружает картинку на сервер, либо переносит ее в программу, софт обрабатывает изображение, используя особые алгоритмы, и выдает в виде файла или в окне программы сфотографированный текст в печатном виде.
В настоящее время разработано достаточно много таких разнообразных программ.
Они отличаются по функционалу совсем незначительно, но могут существенно отличаться по качеству обработки.
Некоторые программы допускают достаточно много ошибок в распознаваемом тексте, тогда как другие – распознают все практически идеально.
Качество распознавания зависит от изначального качества фото, но при прочих равных условиях большую роль играют алгоритмы работу и обширность базы используемого приложения или онлайн-сервиса.
<Рис. 1 Особенности>
Важно! Такие программы могут быть представлены самостоятельным инсталлируемым софтом, простыми мобильными утилитами, способными работать с карты памяти, онлайн-сервиса, приложениями для смартфона и/или планшета. Распространяется такой софт платно или бесплатно, некоторые платные программы имеют ограниченные демо-версии.
Как подготовить изображения для распознавания
Теперь можно загрузить картинку (обязательно в формате JPG или PNG) в поле, расположенном под полем KEY CODE.
Если исходный документ — PDF, то сразу загружать его НЕЛЬЗЯ. Сначала нужно получить постраничные изображения в формате JPG с нужным качеством. Для этого откройте PDF в Adobe Acrobat, далее в меню Файл -> Экспорт в -> Изображение -> JPEG.
Теперь нужно один раз задать настройки для экспорта изображений. В дальнейшем весь экспорт из Acrobat будет выполняться с этими параметрами.
В открывшемся диалоговом окне в нижней его части есть кнопка «Настройки…». Кликните по ней. Откроется еще одно диалоговое окно, в котором установите параметры файла JPEG(высшее качество). В разделе «Преобразование» поставьте «В градациях серого» и подберите разрешение таким образом, чтобы размеры экспортируемых изображений не превышали 5000х5000 пикселей, а размер файлов не превышал 3 Мб. Нажмите Ok. Запустите экспорт, выбрав предварительно папку, в которою Acrobat разместит постраничные JPG. Полученные таким образом изображения можно загружать в MT-Recognition.


Если не удалось подобрать параметры так, чтобы эффективно сжать изображения, тогда воспользуйтесь Photoshop.
Откройте Photoshop. Перейдите в меню Файл -> Сценарии -> Обработчик изображений. Используя этот функционал можно пакетно преобразовывать изображения из выбранной папки, изменяя как количество пикселей по горизонтали и по вертикали, так и степень сжатия.
Как извлечь текст из изображений с помощью ABBY FineReader
Существует две версии этой программы. Одна работает в автоматическом режиме онлайн, другая же — десктопная, ее придется скачать и установить на компьютер. Обе — платные. Однако в онлайн-версии можно бесплатно распознать текст с не более 5 страниц, а в установленной программе первое время действует пробный бесплатный период. На сегодня это один из лучших инструментов для распознавания текста с картинки.
Онлайн версия
-
Шаг 1. Перейдите на сайт FineReader.
- Шаг 2. Загрузите изображение. Выберите нужный вам язык и нажмите на кнопку регистрации. Следуйте указаниям на сайте. Как только вы зарегистрируетесь, сайт перенаправит вас на другую страницу. Нажмите на кнопку «Распознать» и дождитесь окончания процесса.
Загружаем файл, выбираем язык, выбираем формат сохранения
Текст сохранится в формате docs. Скачайте его.
Десктопная версия
- Шаг 1. Запустите FreeReader и нажмите «Сканировать изображение», чтобы выбрать файл, содержащий текст. Он загрузится в программу, при необходимости их можно отредактировать, чтобы улучшить распознаваемость текста. Программа предложит вам выделить область, текст с которой нужно распознать.
-
Шаг 2. Извлечение текста. Нажмите «Распознать», чтобы извлечь текст из выделения. Выбранный текст будет отображаться в текстовом окне через несколько секунд.
Шаг 3. Проверка. В этой программе есть функция проверки. Нажав на эту кнопку, пользователь на экране будет видеть некорректно распознанные слова и фрагмент оригинала. На этом этапе можно быстро исправить практически все ошибки программы.
Шаг 4. Сохраните текст любым из предложенных способов.
Сохраняем текст
Обратите внимание:
- Во-первых, вам нужно убедиться, что исходное изображение четкое, хорошего качества.
- Во-вторых, выбор правильного механизма OCR важен, и вам нужно учитывать их сильные и слабые стороны.
- В-третьих, убедитесь, что ваши изображения масштабированы до нужного размера (не менее 300 DPI).
- Низкая контрастность приведет к плохому OCR, поэтому вам необходимо исправить это до распознавания.
- Удалите шумы и дефекты.
- Если изображение перекошено, отредактируйте его.
Text Scanner распознаватель текста
Еще одно несложное приложение, с помощью которого ваш смартфон станет и сканером, и переводчиком. Приложение поддерживает более 100 мировых языков, качественно распознает символы и тексты, поэтому оно так популярно.
Что мы получим с OCR Text Scanner:
- извлечение текста с картинками;
- обрезку и корректировку изображений для лучшего распознавания написанного;
- редактирование текста;
- возможность делиться текстом с другими пользователями;
- сохранение истории сканирования;
- извлечение телефонных номеров, электронных адресов, URL-ссылок с картинок.
Исходя из этого, чтобы преобразовать рукописный текст, его так же как и в предыдущем случае нужно сфотографировать камерой мобильного телефона на Android или iOS.
Итог выдается в том же расположении, что и оригинал, что уменьшает время на обработку текста.
Приложение подходит и для книжного формата и для небольших надписей.
Программы для преобразования текста с фото в Word
Перед переносом текста с фото в Word онлайн использование программ имеет некоторые преимущества. Так, наиболее мощные из них могут работать в оффлайн режиме, обладая при этом куда более широкими и гибкими настройками OCR. Кроме того, подобные приложения позволяют работать с документами Word напрямую, вставляя в них распознанный текст прямо из буфера обмена.
ABBYY Screenshot Reader
Пожалуй, самый удобный инструмент, позволяющий сконвертировать нераспознанный текст с фото в Word-документ, обычный текстовый файл или передать в буфер обмена для дальнейшего использования. Программой поддерживается около 200 естественных, специальных и формальных языков, захват может производиться целого экрана (с отсрочкой и без), окна и выделенной области. Пользоваться ABBYY Screenshot Reader очень просто.
Скачать: https://www.abbyy.com/ru/screenshot-reader/
- Запустите приложение и выберите область сканирования и язык распознавания;
- Укажите в окошке-панели, куда нужно передать распознанный текст;
- Нажмите в правой части кнопку запуска операции;
- Используйте полученный текст по назначению.
Readiris Pro
«Понимает» более 100 языков, умеет работать с PDF, DJVU и внешними сканерами, с разными типами графических файлов, в том числе многостраничными. Поддерживает интеграцию с популярными облачными сервисами, коррекцию перспективы страницы, позволяет настраивать форматирование. Посмотрим для примера, как скопировать текст с фото в Word в этой сложной на первый взгляд программе.
Скачать для Windows: https://www.irislink.com/EN-US/c1729/Readiris-17—the-PDF-and-OCR-solution-for-Windows-.aspx
Вариант A:
- Перетащите на окно изображение, после чего будет автоматически произведено распознавание имеющегося на нём текста;
- В меню «Выходной файл» выберите Microsoft Word DOCX и сохраните документ.
Вариант B:
- Кликните правой кнопкой мыши по изображению и выберите в контекстном меню Readiris → Convert to Word;
- Получите готовый файл в исходном каталоге.
- Функциональна и удобна.
- Интеграция с облачными сервисами.
- Позволяет конвертировать фото в текст Word через меню Проводника.
Платная, не лучшим образом справляется с изображениями с разноцветным фоном.
Microsoft OneNote
Если у вас установлен офисный пакет Microsoft, то среди приложений должна быть программа OneNote — записная книжка с поддержкой распознавания текста из картинок. Приложение также входит в состав всех версий Windows 10. Хорошо, взглянем, как перенести текст в Word с ее помощью.
- Запустите OneNote и перетащите на ее окно изображение с текстом;
- Выделив изображение, нажмите по нему правой кнопкой мыши и выберите в меню Поиск текста в рисунках → Свой язык;
- Вызовите контекстное меню для картинки повторно и на этот раз выберите в нём опцию «Копировать текст из рисунка»;
- Вставьте из буфера обмена распознанный текст из рисунка в Word или другой редактор.
- Высокое качество распознавания текста даже на цветном фоне.
- Работа в автономном режиме.
- Бесплатна.
- Не столь удобна, как две предыдущие программы.
- Текст вставляется в Word-документ только через буфер.
- Мало доступных языков (русский есть).
Перевод текста с фото на IPhone
Многие из указанных выше приложений подходят и для устройств, работающих под управлением операционной системы iOS. Однако мы составили отдельную подборку сервисов для IPhone, с которыми вы можете ознакомиться ниже.
Scan & Translate
Scan & Translate – удобный переводчик, позволяющий переводить текст только в онлайн-режиме. То есть без подключения к интернету выполнить перевод, к сожалению, не получится. Приложение неплохо распознает текст из вывесок, документов, книг и журналов. А сделать перевод можно на 90 популярных языков! Из основных возможностей программы можно выделить следующее:
- озвучивание переведенного текста на 44 языка;
- отправка текста на электронную почту или в социальные сети;
- наличие специального раздела с историей, куда сохраняются ранее переведенные тексты;
- удобный редактор текста;
- качественный перевод по фотографии.
Рассказывать о работе в приложении особого смысла нет, так интерфейс здесь простой и понятный. Достаточно открыть программу, нажать по иконке фотоаппарата и навести камеру на документ с текстом.
Переводчик Microsoft
Данное приложение доступно владельцам устройств как на Android, так и на iOS. Переводчик Microsoft позволят сканировать текст с изображений и скриншотов, причем весьма в хорошем качестве. Но на этом возможности программы не заканчиваются. Например, можно активировать опцию, которая будет отображать на экране ежедневно новое слово. Тем самым можно расширить словарный запас в практикуемом языке. Что касается перевода по фото, то это выполняется следующим образом:
- Соглашаемся с политикой конфиденциальности, нажав по соответствующей кнопке.
- Нажимаем по иконке фотоаппарата, расположенной на главном экране приложения. Предоставляем приложению разрешение на доступ к устройству.
- Наводим камеру на текст либо выбираем уже готовое изображение в галерее.
- На фотографии сразу же отобразится перевод на выбранный язык. Его кстати, можно изменить чуть ниже.
Microsoft Переводчик
Если подводить краткий итог, то рассмотреть функционал каждого из приложений можно в таблице ниже.
| Приложение | Офлайн-режим | Мгновенный перевод | Операционная система |
| Яндекс Переводчик | + | – | Андроид, iOS |
| Переводчик PROMT.One | + | – | Андроид |
| Google Переводчик | + | + | Андроид, iOS |
| Scan & Translate | – | – | iOS, Андроид |
| Переводчик Microsoft | + | – | Андроид, iOS |
Шаг 1: разобрать данные
Как ни крути, но нет «золотого» формата для представления данных в задачах обнаружения. Некоторые хорошо известные форматы: coco, via, pascal, xml. И это еще не все. Например, набор данных SVHN аннотирован неясным.матформат. К счастью для нас, этосутьобеспечивает пятноread_process_h5Скрипт для преобразования файла .mat в стандартный json, и вам нужно сделать один шаг вперед и преобразовать его в формат Паскаль, например так:
def json_to_pascal(json, filename): #filename is the .mat file # convert json to pascal and save as csv pascal_list = [] for i in json: for j in range(len(i)): pascal_list.append({'fname': i ,'xmin': int(i), 'xmax': int(i+i) ,'ymin': int(i), 'ymax': int(i+i) ,'class_id': int(i)}) df_pascal = pd.DataFrame(pascal_list,dtype='str') df_pascal.to_csv(filename,index=False)p = read_process_h5(file_path)json_to_pascal(p, data_folder+'pascal.csv')
Теперь мы должны иметьpascal.csvфайл, который является гораздо более стандартным и позволит нам прогрессировать
Если преобразование будет медленным, обратите внимание, что нам не нужны все образцы данных. ~ 10К будет достаточно
Сканирование фотографий
Photo Scan – это бесплатное приложение для оптического распознавания символов Windows 10, которое можно загрузить из Магазина Microsoft. Приложение, созданное Define Studios, поддерживает рекламу, но это не портит впечатления. Приложение представляет собой сканер для оптического распознавания символов и считыватель QR-кодов.
Укажите в приложении изображение или распечатку файла. Вы также можете использовать веб-камеру своего компьютера, чтобы на нее можно было посмотреть изображение. Распознанный текст отображается в соседнем окне.
Функция преобразования текста в речь является основным моментом. Нажмите на значок динамика, и приложение прочитает вслух то, что оно только что отсканировало.
Не очень хорошо с рукописным текстом, но распознавание печатного текста было адекватным. Когда все сделано, вы можете сохранить текст OCR в нескольких форматах, таких как текст, HTML, Rich Text, XML, формат журнала и т. Д.
Скачать: Сканирование фотографий (бесплатная покупка в приложении)
Что делать с рукописным вводом?
Человек способен догадаться о смысле предложения, даже если оно написано самым неразборчивым почерком (если речь не идет о рецепте на лекарства, конечно).
Задачу для компьютера иногда упрощают. Например, людей просят писать почтовый индекс в специальном месте на конверте специальным шрифтом. Формы, созданные для дальнейшей обработки компьютером, обычно имеют отдельные поля, которые просят заполнять печатными буквами.
Планшеты и смартфоны, которые поддерживают рукописный ввод, часто используют принцип выявления признаков. При написании буквы «А» экран «чувствует», что сначала пользователь написал одну линию под углом, затем вторую, и, наконец, провел горизонтальную черту между ними. Компьютеру помогает то, что все признаки появляются последовательно, один за другим, в отличие от варианта, когда весь текст уже записан от руки на бумаге.
Текст извлечен с помощью OCR – что это значит?
Нередко студенты сталкиваются с фразой, представленной в полных отчетах системы Антиплагиат.ВУЗ, «Текст извлечен с помощью OCR». Это значит, что перед проверкой работы преподаватель подключил модуль OCR – поставил галочку напротив «Использовать распознавание текста (OCR)». С помощью этого модуля в файле будут подвергаться проверке только видимые элементы, а это значит, что искусственное завышение уникальности с помощью скрытых символов в 90% случаев не сработает. Поскольку для того, чтобы использовать распознавание текста при проверке документа его сначала нужно подключить, многие преподаватели просто забывают о такой возможности, однако если же этот модуль действительно включен, информация об этом обязательно отобразиться в полном отчете о проверке.
После того как мы разобрали принципы распознавания текста OCR и что это в антиплагиате, стоит подробней остановиться на способах повышения уровня оригинальности текста и на том, как можно обойти модуль OCR.
Раздел ИСТОРИЯ для пакетного экспорта текста

- Выделить все распознанные картинки
- Выделить отдельную картинку
- Удалить картинку и распознанные на ней формулы и текст из истории
- Один клик по изображению — открыть распознанные формулы и текст в окне справа
- Очистить всю историю
- Сортировать изображения
- Окно с распознанным текстом и формулами TeX
- Пакетный экспорт текста, распознанного на выделенных изображениях
- Режим MathJax — предпросмотр формул в формате MathType
- Сохранить текст и формулы в Clipboard
В MT-Recognition есть также раздел «ИСТОРИЯ», в котором отображаются все загруженные и распознанные изображения.
Если кликнуть по изображению (по центральной части изображения) (4) в блоке «ИСХОДНЫЕ ИЗОБРАЖЕНИЯ», то справа в блоке «РАСПОЗНАННЫЙ ТЕКСТ С ФОРМУЛАМИ» (7) появится ранее распознанный текст, который был сохранен в истории сервиса. Вы также можете его скопировать в буфер обмена и передать в Word (10).
Если изображения были распознаны, значит в разделе ИСТОРИЯ они будут отображаться, а над блоком «ИСХОДНЫЕ ИЗОБРАЖЕНИЯ» появятся четыре кнопки.
Первая кнопка (1) выбирает или отменяет выбор сразу всех изображений в истории для того, чтобы передавать текст не по одной странице, а наборами страниц.
Вторая кнопка (5) полностью очищает всю историю. Для очищения всей истории не нужно ничего выделять дополнительно. Эта кнопка сама удаляет всё из истории.
Третья и четвертая кнопки (6) меняют порядок сортировки изображений по времени их загрузки и обработки (от первого к последнему или наоборот).
На каждом изображении также есть по две кнопки.
Вверху слева — пустой белый квадрат. Клик по нему выделяет изображение, а пустой квадрат изменятся на квадрат с галочкой.
Вверху справа — красный крестик. Это кнопка для удаления из истории только этого изображения.
Если выделено одно или несколько изображений (вместо белых квадратов отображаются квадраты с галочками), то справа в шапке блока «РАСПОЗНАННЫЙ ТЕКСТ С ФОРМУЛАМИ» появится кнопка «EXPORT ALL SELECTED ITEMS».
Клик по ней передает в блок «РАСПОЗНАННЫЙ ТЕКСТ С ФОРМУЛАМИ» текст (и формулы) сразу со всех выделенных слева изображений в порядке их следования сверху вниз.
Часть текста, соответствующая изображению, при распознавании которого она была получена отделяется от другого текста набором дефисов и названием файла с исходным изображением.
Чтобы изменить порядок следования распознанных текстовых блоков, сначала выберите соответствующий порядок следования изображений в блоке «ИСХОДНЫЕ ИЗОБРАЖЕНИЯ» с помощью кнопок (6) , а затем еще раз дайте команду на передачу текста в блок «РАСПОЗНАННЫЙ ТЕКСТ С ФОРМУЛАМИ» (то есть нажмите кнопку «EXPORT ALL SELECTED ITEMS»).
(a9t9) Бесплатное приложение для распознавания Windows
(a9t9) Бесплатное программное обеспечение OCR – это универсальное приложение для платформы Windows. Таким образом, вы можете использовать его с любым устройством Windows, которое у вас есть. Существует также онлайн-аналог OCR, использующий тот же API.
(a9t9) поддерживает 21 язык для анализа ваших изображений и PDF в текст. Приложение также можно бесплатно использовать, а поддержку рекламы можно удалить с помощью покупки в приложении. Как и большинство бесплатных программ распознавания текста, это идея для печатных документов, а не для рукописного текста.
Скачать: a9t9 Бесплатное распознавание текста (бесплатная покупка в приложении)
Вывод печатных форм с запросом данных в форму «Печать документов» из подсистемы БСП «Печать».
Все не раз видели, как в типовых конфигурациях, построенных на основе БСП (Библиотека стандартных подсистем), печатные формы, построенные на основе Табличного документа, выводятся в специальную форму «ПечатьДокументов». Эта форма входит в состав подсистемы «Печать» из БСП. При разработке своих печатных форм, иногда необходимо запросить у пользователя дополнительные данные необходимые для печати. Тут встает вопрос, как в этом случае вывести печатную форму в форму «Печать документа». В этой статье я рассмотрю, как реализовать вывод печатной формы в упомянутую форму из подсистемы «Печать», в случае если мы хотим перед выводом печатной формы запросить у пользователя дополнительные данные. Здесь будут рассмотрены два случая: когда реализуется печатная форма с использованием подсистемы «Дополнительные отчеты и обработки» и когда печатная форма добавляется в конфигурацию в режиме конфигуратора, т.е. вносятся изменения в типовую конфигурацию.
1 стартмани