Файл robots.txt
Содержание:
Зачем нужен файл robots.txt
Представьте себе, что ваш сайт – это дом. В каждом доме есть разные служебные помещения, типа котельной, кладовки, погреба, в некоторых комнатах есть потаенные уголки (сейф). Все эти тайные пространства гостям видеть не нужно, они предназначены только для хозяев.
Аналогичным образом, каждый сайт имеет свои служебные помещения (разделы), а поисковые роботы – это гости. Так вот, задача правильного robots.txt – закрыть на ключик все служебные разделы сайта и пригласить поисковые системы только в те блоки, которые созданы для внешнего мира.
Примерами таких служебных зон являются – админка сайта, папки с темами оформления, скриптами и т.д.
Вторая функция этого файла – это избавление поисковой выдачи от дублированного контента. Если говорить о WordPress, то, часто, мы можем по разным URL находить одни и те же статьи или их части. Допустим, анонсы статей в разделах с архивами и рубриках идентичны друг другу (только комбинации разные), а страница автора обычного блога на 100% копирует весь контент.
Поисковики интернета могут просто запутаться во всем многообразии таких страниц и неверно понять – что нужно показывать в поисковой выдаче. Закрыв одни разделы, и открыв другие, мы дадим однозначную рекомендацию роботам по правильной индексации сайта, и в поиске окажутся те страницы, которые мы задумывали для пользователей.
Есть у него еще пара функций, о них я расскажу по ходу.
Когда используются правила robots.txt
На самом деле веб-сайтам не стоит полагаться на robots.txt в целях контроля краулинга. В первую очередь стоит позаботиться об архитектуре сайта и о том, чтобы сделать его более доступным для поисковых роботов, очистив от всего лишнего. Тем не менее, если на сайте работают плохо оптимизированные разделы, которые лучше скрыть от глаз пользователей, и эти проблемы не устранимы в обозримой перспективе, robots.txt будет правильным решением.
Google рекомендует использовать данный файл только в целях оптимизации работы поискового робота. Иногда чтение плохо индексируемых разделов затягивается.
Вот некоторые примеры страниц и разделов, индексация которых нежелательна:
- Страницы категорий с нестандартной сортировкой могут повлечь создание дублей основной страницы;
- Пользовательский контент, не подлежащий модерации;
- Страницы с конфиденциальной информацией;
- Внутренние поисковые страницы, которых может насчитываться бесконечное множество.
Где находится robots txt, как увидеть его?
Думаю, многие новички задают себе вопрос – где находится robots txt? Находится файл в корневой папке сайта, в папке public_html, его можно увидеть достаточно просто. Вы можете зайти на хостинг, открыть папку своего сайта и посмотреть есть там этот файл или нет. В прилагаемом ниже видео, показано, как это сделать. Можно посмотреть файл и с помощью Яндекс вебмастера и Google webmaster, но об этом поговорим позже.
Есть вариант еще проще, который позволяет посмотреть не только свой robots txt, но и robots любого сайта, Вы можете robots скачать к себе на компьютер, а затем адаптировать его к себе и использовать на своём сайте (блоге). Делается это так – Вы открываете нужный Вам сайт (блог), и через слэш дописываете robots.txt (смотрите скрин)
и нажимаете Enter, открывается файл robots txt. В данном случае, Вы не можете видеть, где находится robots txt, но можете его посмотреть и скачать.
Добавить с помощью Yoast SEO
Знаменитый плагин Yoast SEO предоставляет возможность добавить и изменить robots.txt из панели WordPress. Причем созданный файл появляется на сервере (а не виртуально) и находится в корне сайта, то есть после удаления или деактивации роботс остается. Переходим в Инструменты > Редактор.
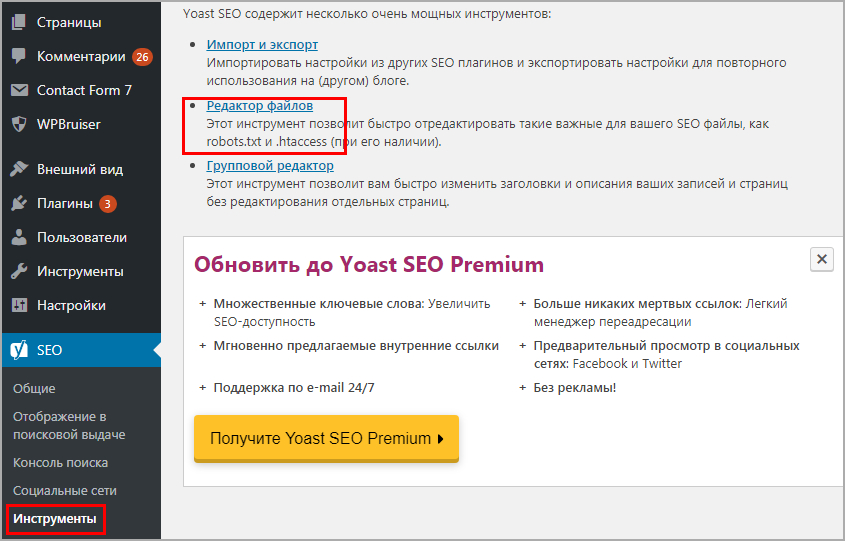 Yoast SEO редактор файлов
Yoast SEO редактор файлов
Если robots есть, то отобразится на странице, если нет есть кнопка “создать”, нажимаем на нее.
 Кнопка создания robots
Кнопка создания robots
Выйдет текстовая область, записываем, имеющийся текст из универсальной конфигурации и сохраняем. Можно проверить по FTP соединению документ появится.
Что такое файл Robots.txt?
Robots.txt – это файл, который указывает поисковым роботам (например, Googlebot и Bingbot), какие страницы сайта не должны сканироваться.
Чем полезен файл Robots.txt?
Файл robots.txt сообщает роботам системам, какие страницы могут быть просканированы. Но не может контролировать их поведение и скорость сканирования сайта. Этот файл, по сути, представляет собой набор инструкций для поисковых роботов о том, к каким частям сайта доступ ограничен.
Но не все поисковые системы выполняют директивы файла robots.txt. Если у вас остались вопросы насчет robots.txt, ознакомьтесь с часто задаваемыми вопросами о роботах.
Как создать файл Robots.txt?
По умолчанию файл robots.txt выглядит следующим образом:
Можно создать свой собственный файл robots.txt в любом редакторе, который поддерживает формат .txt. С его помощью можно заблокировать второстепенные веб-страницы сайта. Файл robots.txt – это способ сэкономить лимиты, которые могут пойти на сканирование других разделов сайта.
Директивы для сканирования поисковыми системами
User-Agent: определяет поискового робота, для которого будут применяться ограничения в сканировании URL-адресов. Например, Googlebot, Bingbot, Ask, Yahoo.
Disallow: определяет адреса страниц, которые запрещены для сканирования.
Allow: только Googlebot придерживается этой директивы. Она разрешает анализировать страницу, несмотря на то, что сканирование родительской веб-страницы запрещено.
Sitemap: указывает путь к файлу sitemap сайта.
Правильное использование универсальных символов
В файле robots.txt символ (*) используется для обозначения любой последовательности символов.
Директива для всех типов поисковых роботов:
User-agent:*
Также символ * можно использовать, чтобы запретить все URL-адреса кроме родительской страницы.
User-agent:*
Disallow: /authors/*
Disallow: /categories/*
Это означает, что все URL-адреса дочерних страниц авторов и страниц категорий заблокированы за исключением главных страниц этих разделов.
Ниже приведен пример правильного файла robots.txt:
User-agent:* Disallow: /testing-page/ Disallow: /account/ Disallow: /checkout/ Disallow: /cart/ Disallow: /products/page/* Disallow: /wp/wp-admin/ Allow: /wp/wp-admin/admin-ajax.php Sitemap: yourdomainhere.com/sitemap.xml
После того, как отредактируете файл robots.txt, разместите его в корневой директории сайта. Благодаря этому поисковый робот увидит файл robots.txt сразу после захода на сайт.
Как проверить работу robots.txt
Стандартный способ проверить через сервис yandex webmaster. Для лучшего анализа нужно зарегистрировать и установить на сайт сервис. Вверху видим загрузившийся robots, нажимаем проверить.
Проверка документа в yandex
Ниже появится блок с ошибками, если их нет то переходим к следующему шагу, если неверно отображается команда, то исправляем и снова проверяем.
Отсутствие ошибок в валидаторе
Проверим правильно ли Яндекс обрабатывает команды, спускаемся чуть ниже, введем два запрещенных и разрешенных адреса, не забываем нажать проверить. На снимке видим что инструкция сработала, красным помечено что вход запрещен, а зеленой галочкой, что индексирование записей разрешена.
Проверка папок и страниц в яндексе
Проверили, все срабатывает, перейдем к следующему способу это настройка robots с помощью плагинов. Если процесс не понятен, то смотрите наше видео.
Как создать и редактировать robots.txt
Вручную
Данный файл всегда можно найти, подключившись к FTP сайта или в файлом редакторе хостинг-провайдера в корневой папке сайта (как правило, public_html):
Далее открываем сам файл и можно его редактировать.
Если его нет, то достаточно создать новый файл.
После вводим название документа и сохраняем.
Через модули/дополнения/плагины
Чтобы управлять данный файлом прямо в административной панели сайта следует установить дополнительный модуль:
Для 1С-Битрикс;
https://dev.1c-bitrix.ru/learning/course/?COURSE_ID=139&LESSON_ID=5814
WordPress;
Для Opencart;
https://opencartforum.com/files/file/5141-edit-robotstxt/
Webasyst.
https://support.webasyst.ru/shop-script/149/shop-script-robots-txt/
X-Robots-Tag
Тег x-robots позволяет вам управлять индексированием страницы в заголовке HTTP-ответа страницы. Данный тег похож на тег meta robots и также не позволяет роботам сканировать определенные виды контента, например, изображения, но уже на этапе обращения к файлу, не скачивая его, и, таким образом, не затрачивая ценный краулинговый ресурс.
Для настройки X-Robots-Tag необходимо иметь минимальные навыки программирования и доступ к файлам .php или .htaccess вашего сайта. Директивы тега meta robots также применимы к тегу x-robots.
<?
header("X-Robots-Tag: noindex, nofollow");
?>
Примечание: X-Robots-Tag эффективнее, если вы хотите запретить сканирование изображений и медиа-файлов. Применимо к контенту лучше выбирать запрет через мета-теги. Noindex и X-Robots Tag это директивы, которым поисковые роботы четко следуют, это не рекомендации как robots.txt, которые по определению можно не соблюдать.
Файл robots.txt для WordPress
WordPress robots.txt где лежит/находится? По умолчанию WordPress автоматически создает виртуальный файл robots.txt для вашего сайта. Таким образом, даже если вы ни чего не делали, на вашем сайте ВордПресс уже должен быть файл robots.txt. Вы можете проверить, так ли это, добавив /robots.txt в конец вашего доменного имени. Например, так https://ваш сайт/robots.txt
Виртуальный файл robots.txt в WordPress
Поскольку этот файл является виртуальным, вы не можете его редактировать. Однако, если вы хотите отредактировать свой файл robots.txt WordPress как надо, вам необходимо создать физический файл на вашем хостинге. Создайте свой правильный robots.txt для WordPress, который вы сможете легко редактировать по мере необходимости.
Создание и редактирование robots.txt
- Если у вас еще нет файла, то нужно создать его с нуля. Откройте самый простой текстовый редактор (но не MS Word, т.к. нам нужен именно простой текстовый формат), к примеру, Блокнот (Windows) или TextEdit (Mac).
Примечания:
- Если, например, сайт реализован на CMS WordPress, то по умолчанию, вы не сможете найти его в корне сайта, так как «из коробки» его наличие не предусмотрено. Поэтому для редактирования его придется создать заново.
- Регистр имени файла важен! Название robots.txt указывается исключительно строчными буквами. Также убедитесь, что вы написали корректное название, НЕ «Robots» или «robot» – это наиболее частые ошибки при создании файла.
Как создать и редактировать robots.txt
Вручную
Данный файл всегда можно найти, подключившись к FTP сайта или в файлом редакторе хостинг-провайдера в корневой папке сайта (как правило, public_html):
Далее открываем сам файл и можно его редактировать.
Если его нет, то достаточно создать новый файл.
После вводим название документа и сохраняем.
Через модули/дополнения/плагины
Чтобы управлять данный файлом прямо в административной панели сайта следует установить дополнительный модуль:
Для 1С-Битрикс;
https://dev.1c-bitrix.ru/learning/course/?COURSE_ID=139&LESSON_ID=5814
WordPress;
Для Opencart;
https://opencartforum.com/files/file/5141-edit-robotstxt/
Webasyst.
https://support.webasyst.ru/shop-script/149/shop-script-robots-txt/
Robots.txt: что это
Ответ на вопрос о том, что такое robots.txt находится в его названии. Это текстовый файл, т.е. документ в формате .txt
Этот файл является так же важнейшим инструментом во внутреннем СЕО-продвижении сайта, но многие недооценивают его важность и значение. В файле robots.txt содержаться инструкции, для того чтобы проиндексировать конкретный сайт.
Простыми словами, файл указывает, какие страницы нужно проиндексировать, а какие нет. Это требуется, потому что не вся информация, которая есть на сайте, нужна поисковым роботам. Существуют дубликаты страниц или системные файлы, которые совсем не обязательно индексировать.
Если вебмастер неправильно составляет файл robots.txt, то поисковые роботы, придя на Ваш сайт, начинают индексировать всё подряд. В этом случае, Ваша новейшая статья, например, о ценах разработки сайта-визитки может быть проиндексирована далеко, не в первую очередь, и сама индексация сайта будет затянута на продолжительное время.
Проверка файла robots txt
После закачки файла robots txt, нужно проверить его наличие и работу. Для этого можем посмотреть файл с браузера, как показано выше в разделе «Где находится robots txt, как увидеть». А проверить работу файла можно с помощью Яндекс вебмастера и Google webmaster. Помним, что для этого должны быть подтверждены права на управление сайтом, как в Яндексе, так и в Google.
Для проверки в Яндексе заходим в наш аккаунт Яндекс вебмастера, выбираем сайт, если у Вас их несколько. Выбираем «Настройка индексирования», «Анализ robots.txt», а дальше следуем инструкциям.
В Google вебмастер делаем аналогично, заходим в наш аккаунт, выбираем нужный сайт (если их несколько), нажимаем кнопку «Сканирование» и выбираем «Инструмент проверки файла robots.txt». Откроется файл robots txt, Вы можете его исправить или проверить.
На этой же странице находятся отличные инструкции по работе с файлом robots txt, можете с ними ознакомиться. В заключении привожу видео, где показано что представляет собой файл robots txt, как его найти, как его посмотреть и скачать, как работать с генератором файла, как составить robots txt и адаптировать под себя, показана другая информация:
Что такое robots.txt?
Robots.txt (ещё его называют стандарт исключений) — текстовый файл, содержащий в себе свод правил (требований), адресованных к ботам-поисковикам. Простыми словами: в нём прописываются указания — какие страницы рекомендованы к обработке, а какие не рекомендованы.
Важно понимать, что это руководство не воспринимается в качестве обязательной к выполнению команды, а в большей степени носит рекомендательный характер. Файл кодируется в UTF-8, функционирует для протоколов FTP, http, https
Его нужно вставить в корневой каталог веб-ресурса. Попадая на сайт, бот разыскивает robots.txt, считывает его и в дальнейшем, как правило, действует согласно прописанным рекомендациям
Файл кодируется в UTF-8, функционирует для протоколов FTP, http, https. Его нужно вставить в корневой каталог веб-ресурса. Попадая на сайт, бот разыскивает robots.txt, считывает его и в дальнейшем, как правило, действует согласно прописанным рекомендациям.
А если робот не найдёт данный файл? Он продолжит свою работу на ресурсе, но начнёт скачивание и анализ всех его страниц. В ряде случаев это совершенно не нужно.
Дополнительные директивы
Кроме регулярных выражений Яндекс и Google разрешают использование директивы Allow, которая является противоположностью Disallow, то-есть указывает какие страницы можно индексировать. В следующем примере Яндексу запрещено индексировать все, кроме адресов страниц начинающихся с /articles:
В данном примере директиву Allow нужно прописывать перед Disallow, иначе Яндекс поймет это как полный запрет индексации сайта. Пустая директива Allow также полностью запрещает индексирование сайта:
равнозначно
Нестандартные директивы нужно указывать только для тех поисковиков, которые их поддерживают. В противном случае робот не понимающий данную запись может неправильно обработать ее или весь файл robots.txt. Более подробно о дополнительных директивах и вообще о понимании команд файла robots.txt отдельным роботом можно узнать на сайте соответствующей поисковой системы.
Как редактировать и загружать robots.txt
Есть несколько способов создать файл robots.txt — либо сделать его вручную в текстовом редакторе и разместить в корневом каталоге (папка самого верхнего уровня на сервере), либо воспользоваться специальными плагинами для настройки файла.
Как создать robots.txt в Блокноте
Самый простой способ создать файл robots.txt — написать его в блокноте и загрузить на сервер в корневой каталог.
Лучше не использовать стандартное приложение — воспользуйтесь специальными редакторы текста, например, Notepad++ или Sublime Text, которые поддерживают сохранение файла в конкретной кодировке. Дело в том, что поисковые роботы, например, Яндекс и Google, читают только файлы в UTF-8 с определенными переносами строк — стандартный Блокнот Windows может добавлять ненужные символы или использовать неподдерживаемые переносы.
Говорят, что это давно не так, но чтобы быть уверенным на 100%, используйте специализированные приложения.
Рассмотрим создание robots.txt на примере Sublime Text. Откройте редактор и создайте новый файл. Внесите туда нужные настройки, например:
Где mysite.ru — домен вашего сайта.
После того, как вы записали настройки, выберите в меню File ⟶ Save with Encoding… ⟶ UTF-8 (или Файл ⟶ Сохранить с кодировкой… ⟶ UTF-8).
Назовите файл “robots.txt” (обязательно с маленькой буквы).
Файл готов к загрузке.
Загрузить robots.txt через FTP
Для того, чтобы загрузить созданный robots.txt на сервер через FTP, нужно для начала включить доступ через FTP в настройках хостинга.
После этого скопируйте настройки доступа по FTP: сервер, порт, IP-адрес, логин и пароль (не совпадают с логином и паролем для доступа на хостинг, будьте внимательны!).
Чтобы загрузить файл robots.txt вы можете воспользоваться специальным файловым менеджером, например, FileZilla или WinSCP, или же сделать это просто в стандартном Проводнике Windows. Введите в поле поиска “ftp://адрес_FTP_сервера”.
После этого Проводник попросит вас ввести логин и пароль.
Введите данные, которые вы получили от хостинг-провайдера на странице настроек доступа FTP. После этого в Проводнике откроются файлы и папки, расположенные на сервере. Скопируйте файл robots.txt в корневую папку. Готово.
Загрузить или создать robots.txt на хостинге
Если у вас уже есть готовый файл robots.txt, вы можете просто загрузить его на хостинг. Зайдите в файловый менеджер панели управления вашим хостингом, нажмите на кнопку «Загрузить» и следуйте инструкциям (подробности можно узнать в поддержке у вашего хостера.
Многие хостинги позволяют создавать текстовые файлы прямо в панели управления хостингом. Для этого нажмите на кнопку «Создать файл» и назовите его “robots.txt” (с маленькой буквы).
После этого откройте его во встроенном текстовом редакторе хостера. Если вам предложит выбрать кодировку для открытия файла — выбирайте UTF-8.
Добавьте нужные директивы и сохраните изменения.
Директивы в Robots.txt
Disallow
Disallow запрещает индексацию отдельной страницы или группы (в том числе всего сайта). Чаще всего используется для того, чтобы скрыть технические страницы, динамические или временные страницы.
# Полностью закрывает весь сайт от индексации
User-agent: *
Disallow: /
# Блокирует для скачивания все страницы раздела /category1/, например, /category1/page1/ или caterogy1/page2/
Disallow: /category1/
# Блокирует для скачивания страницу раздела /category2/
User-agent: *
Disallow: /category1/$
# Дает возможность сканировать весь сайт просто оставив поле пустым
User-agent: *
Disallow:
Важно! Следует понимать, что регистр при использовании правил имеет значение, например, Disallow: /Category1/ не запрещает посещение страницы /category1/
Allow
Директива Allow указывает на то, что роботу можно сканировать содержимое страницы/раздела, как правило, используется, когда в полностью закрытом разделе, нужно дать доступ к определенному документу.
# Дает возможность роботу скачать файл site.ru//feed/turbo/ несмотря на то, что скрыт раздел site.ru/feed/.
Disallow: */feed/*
Allow: /feed/turbo/
# разрешает скачивание файла doc.xml
# разрешает скачивание файла doc.xml
Allow: /doc.xml
Sitemap
Директива Sitemap указывает на карту сайта, которая используется в SEO для вывода списка URL, которые нужно проиндексировать в первую очередь.
Важно понимать, что в отличие от стандартных директив у нее есть особенности в записи:
- Следует указывать полный URL, когда относительный адрес использовать запрещено;
- На нее не распространяются остальные правила в файле robots.txt;
- XML-карта сайта должна иметь в URL-адресе домен сайта.
# Указывает карту сайта
Sitemap: https://serpstat.com/sitemap.xml
Clean-param
Используется когда нужно указать Яндексу (в Google она не работает), что страница с GET-параметрами (например, site.ru?param1=2¶m2=3) и метками (в том числе utm) не влияющие на содержимое сайта, не должна быть проиндексирована.
#для адресов вида:
www.example1.com/forum/showthread.php?s=681498b9648949605&t=8243
www.example1.com/forum/showthread.php?s=1e71c4427317a117a&t=8243
#robots.txt будет содержать:
User-agent: Yandex
Disallow:
Clean-param: s /forum/showthread.php
#для адресов вида:
www.example2.com/index.php?page=1&sid=2564126ebdec301c607e5df
www.example2.com/index.php?page=1&sid=974017dcd170d6c4a5d76ae
#robots.txt будет содержать:
User-agent: Yandex
Disallow:
Clean-param: sid /index.php
Подробнее о данной директиве можно прочитать здесь:
https://serpstat.com/ru/blog/obrabotka-get-parametrov-v-robotstxt-s-pomoshhju-direktivy-clean-param/
Crawl-delay
Важно! Данная директива не поддерживается в Яндексе с 22 февраля 2019 года и в Google 1 сентября 2019 года, но работает с другими роботами. Настройки скорости скачивания можно найти в Яндекс.Вебмастер и Google Search Console
Crawl-delay указывает временной интервал в секундах, в течение которого роботу разрешается делать только 1 сканирование. Как правило, необходима лишь в случаях, когда у сайта наблюдается большая нагрузка из-за сканирования.
Дополнительные директивы robots.txt
-
Clean-Param: указывается параметр URL (можно несколько), страницы с которым нужно исключить из индекса и не индексировать
Данная директива используется только для User-agent: Yandex ! В Google параметр URL можно указать в Search Console или же использовать канонические ссылки (rel=»canonical»).
Clean-Param позволит избавиться от дублей страниц, которые возникают в результате генерации динамических URL (реферальные ссылки, сессии пользователей, идентификаторы и т.д.).
К примеру, если у вас на сайте появилось много страниц такого типа:И вы хотите, чтобы робот индексировал только www.mywebsite.com/testdir/index.php
Создаем правило для очистки параметров «id», «catid» и «Itemid», например:
Можно так же создать правило очистки параметров URL не только для определенной страницы, но и для всего сайта. Например, создать правило очистки UTM-меток: -
Crawl-delay: указывается время задержки в секундах между сканированием страниц
Данная директива полезна, если у вас большой сайт на слабом сервере и каждый день добавляется большое количество материалов. Поисковики при этом сразу же начинают индексировать сайт и создают нагрузку на сервер. Чтобы сайт не упал, задаем тайм-аут в несколько секунд для поисковиков — то есть задержка для перехода от одной к следующей странице.
Пример:
Таким образом, только через три секунды краулер перейдет к индексированию следующей страницы.
-
Sitemap: указываетcя полный путь к XML карте сайта
Данная директива сообщает ботам, что у сайта есть карта сайта, что поможет ботам быстро обнаруживать новые страницы при индексации. Если сайт часто наполняется, это особенно актуально, так как ускорит и улучшит индексацию (напомню, вы можете проверить индексацию страницы в нашем сервисе).
Пример: -
Host: указывается главное «зеркало» сайта, то есть его предпочтительная версия
Например, сайт доступен по http и https версии, чтобы краулер не запутался в “зеркалах” при индексации и не наделал дублей, указываем главный домен в директиве Host.Данная директива используется только для User-agent: Yandex
Пример:
Если сайт не на https, тогда указываем домен без протокола http: mywebsite.comПримечание: 20 марта 2018 года Яндекс заявил, что директива Host не обязательна, и вместо нее можно теперь использовать 301-й редирект.
Как проверить работу файла robots.txt
В Яндекс.Вебмастер
В Яндекс.Вебмастер в разделе «Инструменты→ Анализ robots.txt» можно увидеть используемый поисковиком свод правил и наличие ошибок в нем.
Также можно скачать другие версии файла или просто ознакомиться с ними.
Чуть ниже имеется инструмент, который дает возможно проверить сразу до 100 URL на возможность сканирования.
В нашем случае мы проверяем эти правила.
Как видим из примера все работает нормально.
Также если воспользоваться сервисом «Проверка ответа сервера» от Яндекса также будет указано, запрещен ли для сканирования документ при попытке обратиться к нему.
В Google Search Console
В случае с Google можно воспользоваться инструментом проверки Robots.txt, где потребуется в первую очередь выбрать нужный сайт.
Важно! Ресурсы-домены в этом случае выбирать нельзя. Теперь мы видим:
Теперь мы видим:
- Сам файл;
- Кнопку, открывающую его;
- Симулятор для проверки сканирования.
Если в симуляторе ввести заблокированный URL, то можно увидеть правило, запрещающее сделать это и уведомление «Недоступен».
Однако, если ввести заблокированный URL в страницу поиска в новой Google Search Console (или запросить ее индексирование), то можно увидеть, что страница заблокирована в файле robots.txt.
Подписывайтесь на наши социальные сети
Что такое robots.txt и для чего он нужен
Robots.txt — это обычный текстовый файл с расширением .txt, который содержит директивы и инструкции индексирования сайта, его отдельных страниц или разделов для роботов поисковых систем.
Давайте рассмотрим самый простой пример содержимого robots.txt, которое разрешает поисковым системам индексировать все разделы сайта:
User-agent: * Allow: /
Данная инструкция дословно говорит: всем роботам, читающим данную инструкцию (User-agent: *) разрешаю индексировать весь сайт (Allow: /).
Зачем все эти сложности с инструкциями для роботов, и почему нельзя открывать сайт для индексации полностью?
Представьте, что вы поисковый робот, которому нужно просмотреть миллиарды страниц по всем интернету, потом определить для каждой страницы запросы, которым они могут соответствовать и в конце проранжировать эту массу в поисковой выдаче. Согласитесь, задача не из легких. Для работы поисковых алгоритмов используются колоссальные ресурсы, которые, разумеется, ограничены.
Если помимо страниц, которые содержат полезный контент, и которые по задумке владельца сайта должны участвовать в выдаче, роботу придется просматривать еще кучу технических страниц, которые не представляют никакой ценности для пользователей, его ресурсы будут тратиться впустую. Вы только представьте, что только один единственный сайт может генерировать тысячи страниц результатов поиска по сайту, дублирующихся страниц или страниц, не содержащих контента вообще. А если этот объем масштабировать на всю сеть, то получатся гигантские цифры и соответствующие ресурсы, которые необходимо тратить поисковикам.
Наличие огромного количества бесполезного контента на вашем сайте может негативно сказаться на его представлении в поиске. Как бы вы отнеслись к человеку, который дал вам мешок орехов, но внутри оказалась только скорлупа и всего 2-3 орешка? Не трудно представить и позицию поисковиков при аналогии данной ситуации с вашим сайтом.
Кроме того, существует такое понятие, как краулинговый бюджет. Условно, это объем страниц, который может участвовать в поисковой выдаче от одного сайта. Этот объем, естественно, ограничен, но по мере роста проекта и повышения его качества, краулинговый бюджет может увеличиваться, но сейчас не об этом. Главное идея в том, в выдаче должны участвовать только страницы, которые содержат полезный контент, а весь технический «мусор» не должен засорять выдачу поисковым спамом.
Что такое файл robots txt, зачем он нужен и за что он отвечает
Файл robots txt, это текстовый файл, который содержит инструкции для поисковых роботов. Перед обращением к страницам Вашего блога, робот ищет первым делом файл robots, поэтому он так важен. Файл robots txt это стандарт для исключения индексации роботом тех или иных страниц. От файла robots txt будет зависеть попадание в выдачу Ваших конфиденциальных данных. Правильный robots txt для сайта поможет в его продвижении, поскольку он является важным инструментов во взаимодействии Вашего сайта и поисковых роботов.
Не зря файл robots txt называют важнейшим инструментом SEO, этот маленький файл напрямую влияет на индексацию страниц сайта и сайта в целом. И наоборот, неправильный robots txt может исключить некоторые страницы, разделы или сайт в целом из поисковой выдачи. В этом случае можно иметь и 1000 статей на блоге, а посетителей на сайте просто не будет, будут чисто случайные прохожие.
На Яндекс вебмастере есть обучающее видео, в котором Яндекс сравнивает файл роботс тхт с коробкой Ваших личных вещей, которые Вы не хотите никому показывать. Чтобы посторонние не заглядывали в эту коробку, Вы её заклеиваете скотчем и пишете на ней – «Не открывать».
Роботы, как воспитанные личности, эту коробку не открывают и другим не смогут рассказать, что там находится. Если файла robots txt нет, то робот поисковой системы считает, что все файлы доступные, он откроет коробку, всё посмотрит и другим расскажет, что лежит в коробке. Чтобы робот не лазил в этот ящик, надо запретить ему туда лазить, делается это с помощью директивы Disallow, что переводится с английского – запретить, а Allow – разрешить.
Это обычный txt файл, который составляется в обычном блокноте или программе NotePad++, файл, который предлагает роботам не индексировать определённые страницы на сайте. Для чего это нужно:
- правильно составленный файл robots txt не позволяет роботам индексировать всякий мусор и не забивать поисковую выдачу ненужным материалом, а также не плодить дубли страниц, что является очень вредным явлением;
- не позволяет роботам индексировать информацию, которая нужна для служебного пользования;
- не позволяет роботам шпионам воровать конфиденциальные данные и использования их для отправки спама.
Это не означает, что мы что-то хотим спрятать от поисковиков, что-то тайное, просто эта информация не несёт ценности ни для поисковиков, ни для посетителей. Например, страница логина, RSS ленты и т.д. Кроме того, файл robots txt указывает зеркало сайта, а также карту сайта. По умолчанию на сайте, который делается на WordPress, файла robots txt нет. Поэтому нужно создать robots txt файл и залить его в корневую папку Вашего блога, в данной статье мы рассмотрим robots txt для WordPress, его создание, корректировку и заливку на сайт. Итак, сначала мы узнаем, где находится файл robots txt?
Заключение
Файл robots.txt очень важен для SEO-оптимизации вашего сайта. Подходите к его настройке со всей ответственностью, потому как при неправильной реализации все может пойти прахом.
Учитывайте все инструкции, которыми я поделился в этой статье, и не забывайте, что вам не обязательно точь-в-точь копировать мои варианты роботс. Вполне возможно, что вам придется дополнительно разбираться в каждой из директив, подстраивая файл под свой конкретный случай.
А если вы хотите более глубоко разобраться в robots.txt и создании сайтов на WordPress, то я приглашаю вас на курс Василия Блинова “Как создать блог”. На нем вы узнаете, как можно без особого труда создать сайт, не забыв оптимизировать его для поисковиков.