Bulk testing pagespeed insights with the seo spider
Содержание:
- 2) Auditing Redirects In A Migration
- Аудит XML Sitemap в Spider SEO Screaming Frog
- 2) Site Structure Comparison
- 9) Canonicals & Pagination Tabs & Filters
- Other Updates
- 3) Изображения с высоким разрешением
- Small Update – Version 12.1 Released 25th October 2019
- Чек-лист по выбору парсера
- Small Update – Version 12.3 Released 28th November 2019
- Полное описание
- Other Updates
- Small Update – Version 10.1 Released 21st September 2018
- Viewing Crawl Data
- Установка программы
- 4) Configurable Accept-Language Header
- 4) AJAX Crawling
- What Is SEO?
- 5) Improved UX Bits
- 1) Near Duplicate Content
- Regex Examples
2) Auditing Redirects In A Migration
This is by some distance my personal favourite feature due to the amount of time it has saved.
I used to find it a pain to audit redirects in a site (and, or domain) migration, checking to ensure a client had set-up permanent 301 redirects from their old URLs, to the correct new destination.
Hence, we specifically built a feature which allows you to upload a list of your old URLs, crawl them and follow any redirect chains (with the ‘always follow redirects’ tickbox checked), until the final target URL is reached (with a no response, 2XX, 4XX or 5XX etc) and map them out in a single report to view.
This report does not just include URLs which have redirect chains, it includes every URL in the original upload & the response in a single export, alongside the number of redirects in a chain or whether there are any redirect loops.
Click on the tiny incomprehensible image below to view a larger version of the redirect mapping report, which might make more sense (yes, I set-up some silly redirects to show how it works!) –
You can read more about this feature in our ‘How to audit redirects in a site migration‘ guide.
Аудит XML Sitemap в Spider SEO Screaming Frog
Справа на вкладке Overviews, в разделе Sitemaps вы получите исчерпывающие данные о XML-карте сайта:
В результате мы получим данные по следующим фильтрам:
- URLs in Sitemap — веб-страницы, которые находятся на сайте и добавлены в XML-карту сайта. Сюда должны входить только оптимизированные канонические веб-страницы, открыты для индексации;
- URLs Not in Sitemap — веб-страницы, которые доступны на сайте, но не добавлены в XML-карту сайта. Например, скрытые от поиска страницы тегов и авторов в CMS WordPress;
- Orphan URLs — веб-страницы, которые доступны только в XML-карте сайта, но не проиндексированы поисковым ботом. Является ошибкой поисковой оптимизации;
- Non-Indexable URLs in Sitemap — веб-страницы, которые доступны в XML-карте сайта, но закрыты для поиска. Аналогично является ошибкой, т.к. карта сайта Sitemap не должна содержать страниц, закрытых от индекса;
- URLs In Multiple Sitemaps — веб-страницы, которые доступны в нескольких XML-картах одновременно. Как правило, веб-страница должна находится только в одной карте сайта;
- XML Sitemap With Over 50k URLs — показывает наличие крупніх XML-карт сайта с более 50 тыс. страниц;
- XML Sitemap With Over 50mb — аналогично, только с размером 50 Мб.
Приведенные выше фильтры помогут убедиться, что в XML Sitemap включены только качественные индексируемые канонические URL. Поисковые системы плохо переносят «грязь» в XML-файлах Sitemap, например, в тех, которые содержат ошибки, перенаправления или неиндексируемые URL-адреса. Таким сайтам поисковики доверяют при сканировании и индексировании
Поэтому важно поддерживать работоспособность всех веб-страниц, которые попадают в XML-файл
Также есть возможность просмотреть XML-карту сайта в режиме списка со множеством фильтров и показателей:
Список можете выгрузить с помощью кнопки «Export» в формате .xls. Присутствует режим просмотра в виде дерева каталогов:
Если выбрать из списка URL, то с помощью вкладки Inlinks можно посмотреть страницу донор и анкор:
Экспортировать все Inlinks в Excel можно с помощью меню Bulk Export -> Sitemaps:
2) Site Structure Comparison
The right-hand ‘Site Structure’ tab shows a directory tree overview of how the structure of a site has evolved. It allows you to identify which directories have new or missing pages, for example, you can see new files have been found within the /sites/, /fixture/ and /news/ directories below.
This can help provide more context to how a site is changing between crawls.
It aggregates data from the previous and current crawl to show where URLs have either been added to a directory or have been removed. You can click in and drill down to see which specific URLs have changed.
You’re also able to visualise how crawl depth has changed between current and previous crawls, which helps understand changes to internal linking and architecture.
9) Canonicals & Pagination Tabs & Filters
Canonicals and pagination were previously included under the directives tab. However, neither are directives and while they are useful to view in combination with each other, we felt they were deserving of their own tabs, with their own set of finely tuned filters, to help identify issues faster.
So, both have their own new tabs with updated and more granular filters. This also helps expose data that was only previously available within reports, directly into the interface. For example, the new now includes a ‘Non-Indexable Canonical’ filter which could only be seen previously by reviewing response codes, or viewing ‘Reports > Non-Indexable Canonicals’.
Pagination is something websites get wrong an awful lot, it’s nearly at hreflang levels. So, there’s now a bunch of useful ways to filter paginated pages under the to identify common issues, such as non-indexable paginated pages, loops, or sequence errors.
The more comprehensive filters should help make identifying and fixing common pagination errors much more efficient.
Other Updates
We have also performed other updates in the version 3.0 of the Screaming Frog SEO Spider, which include the following –
- You can now view the ‘Last-Modified’ header response within a column in the ‘Internal’ tab. This can be helpful for tracking down new, old, or pages within a certain date range. ‘Response time’ of URLs has also been moved into the internal tab as well (which used to just be in the ‘Response Codes’ tab, thanks to RaphSEO for that one).
- The parser has been updated so it’s less strict about the validity of HTML mark-up. For example, in the past if you had invalid HTML mark-up in the HEAD, page titles, meta descriptions or word count may not always be collected. Now the SEO Spider will simply ignore it and collect the content of elements regardless.
- There’s now a ‘mobile-friendly’ entry in the description prefix dropdown menu of the SERP panel. From our testing, these are not used within the description truncation calculations by Google (so you have the same amount of space for characters as pre there introduction).
- We now read the contents of robots.txt files only if the response code is 200 OK. Previously we read the contents irrespective of the response code.
- Loading of large crawl files has been optimised, so this should be much quicker.
- We now remove ‘tabs’ from links, just like Google do (again, as per internal testing). So if a link on a page contains the tab character, it will be removed.
- We have formatted numbers displayed in filter total and progress at the bottom. This is useful when crawling at scale! For example, you will see 500,000 rather than 500000.
- The number of rows in the filter drop down have been increased, so users don’t have to scroll.
- The default response timeout has been increased from 10 secs to 20 secs, as there appears to be plenty of slow responding websites still out there unfortunately!
- The lower window pane cells are now individually selectable, like the main window pane.
- The ‘search’ button next to the search field has been removed, as it was fairly redundant as you can just press ‘Enter’ to search.
- There’s been a few updates and improvements to the GUI that you may notice.
- (Updated) – The ‘Overview Report’ now also contains the data you can see in the right hand window pane ‘Response Times’ tab. Thanks to Nate Plaunt and I believe a couple of others who also made the suggestion (apologies for forgetting anyone).
We have also fixed a number of reported bugs, which include –
- Fixed a bug with ‘Depth Stats’, where the percentage didn’t always add up to 100%.
- Fixed a bug when crawling from the domain root (without www.) and the ‘crawl all subdomains’ configuration ticked, which caused all external domains to be treated as internal.
- Fixed a bug with inconsistent URL encoding. The UI now always shows the non URL encoded version of a URL. If a URL is linked to both encoded and unencoded, we’ll now only show the URL once.
- Fixed a crash in Configuration->URL Rewriting->Regex Replace, as reported by a couple of users.
- Fixed a crash for a bound checking issue, as reported by Ahmed Khalifa.
- Fixed a bug where unchecking the ‘Check External’ tickbox still checks external links, that are not HTML anchors (so still checks images, CSS etc).
- Fixed a bug where the leading international character was stripped out from SERP title preview.
- Fixed a bug when crawling links which contained a new line. Google removes and ignores them, so we do now as well.
- Fixed a bug where AJAX URLs are UTF-16 encoded using a BOM. We now derive encoding from a BOM, if it’s present.
Hopefully that covers everything! We hope the new features are helpful and we expect our next update to be significantly larger. If you have any problems with the latest release, do just pop through the details to support, and as always, we welcome any feedback or suggestions.
You can download the SEO Spider 3.0 now. Thanks to everyone for their awesome support.
3) Изображения с высоким разрешением
Поисковые системы не индексируют изображения, которые имеют слишком большой размер, высокое разрешение или долго грузятся. Размер изображения не должен превышать 100 КБ. Не забудьте добавить ключевое слово в альтернативный текст. Он должен подробно описывать изображение, чтобы, если оно не может быть загружено, посетитель сайта мог воспользоваться этим текстом. SEO Frog Spider находит на сайте изображения, которые не подходят, и их нужно сжимать. Также можно изучить исчерпывающий отчет об изображениях, размещенных на сайте. Если вы используете на ресурсе «неоригинальные изображения», инструмент предложит создать свои собственные картинки, чтобы повысить качество контента.
Small Update – Version 12.1 Released 25th October 2019
We have just released a small update to version 12.1 of the SEO Spider. This release is mainly bug fixes and small improvements –
- Fix bug preventing saving of .seospider files when PSI is enabled.
- Fix crash in database mode when crawling URLs with more than 2,000 characters.
- Fix crash when taking screenshots using JavaScript rendering.
- Fix issue with Majestic with not requesting data after a clear/pause.
- Fix ‘inlinks’ tab flickering during crawl if a URL is selected.
- Fix crash re-spidering a URL.
- Fix crash editing text input fields with special characters.
- Fix crash when renaming a crawl in database mode.
Чек-лист по выбору парсера
Краткий чек-лист, который поможет выбрать наиболее подходящий инструмент или сервис.
- Четко определите, для каких задач вам нужен парсер: анализ SEO конкурентов или мониторинг цен, сбор данных для наполнения каталога, съем позиций и т.д.
- Определите, какой объем данных и в каком виде нужно получать.
- Определите, как часто вам нужно собирать данные: единоразово или с определенной периодичностью (раз в день/неделю/месяц).
- Выберите несколько инструментов, которые подходят для решения ваших задач. Попробуйте демо-версии. Узнайте, предоставляется ли техническая поддержка (желательно даже протестировать ее — задать парочку вопросов и посмотреть, как быстро вы получите ответ и насколько он будет исчерпывающим).
- Выберите наиболее подходящий сервис по соотношению цена/качество.
Для крупных проектов, где требуется парсить большие объемы данных и производить сложную обработку, более выгодной может оказаться разработка собственного парсера под конкретные задачи.
Для большинства же проектов достаточно будет стандартных решений (возможно, вам может быть достаточно бесплатной версии любого из парсеров или пробного периода).
Small Update – Version 12.3 Released 28th November 2019
We have just released a small update to version 12.3 of the SEO Spider. This release is mainly bug fixes and small improvements –
- You can now use a URL regular expression to highlight nodes in tree and FDD visualisations i.e. show all nodes that contain foo/bar.
- PageSpeed Insights now show errors against URLs including error message details from the API.
- A (right click) re-spider of a URL will now re-request PSI data when connected to the API.
- Improve robustness of recovering crawls when OS is shutdown during running crawl.
- Fix major slow down of JavaScript crawls experienced by some macOS users.
- Fix windows installer to not allow install when the SEO Spider is running.
- Fix crash when editing database storage location.
- Fix crash using file dialogs experienced by some macOS users.
- Fix crash when sorting columns.
- Fix crash when clearing data.
- Fix crash when searching.
- Fix crash undoing changes in text areas.
- Fix crash adjusting sliders in visualisations.
- Fix crash removing/re-spidering duplicates titles/meta descritions after editing in SERP View.
- Fix crash in AHREFs API.
- Fix crash in SERP Panel.
- Fix crash viewing structured data.
Полное описание
Скриминг Фрог работает по принципу так называемого «паука», выполняет проверку веб-ресурса и сбор информации о его содержимом. После этого, оптимизатор сможет анализировать полученные данные, проводить быстрый аудит сайта, проверять страницы на предмет критических ошибок и так далее.
Рассмотрим перечень основных опций, встроенных в софт.
- Ищет битые страницы и редиректы;
- Работает через командную строку;
- Возможность извлекать данные при помощи XPath;
- Поддерживает Proxy;
- Умеет парсить все поддомены и внутренние ссылки по расписанию;
- Выгрузка всех картинок, удаление ненужных папок;
- Можно отфильтровать каждый столбец и колонку в таблице;
- Показывает недостающие ключевые слова, необходимые для оптимизации;
- Отображение анкоров, а также документов, на которых присутствуют урлы к этим страницам;
- Позволяет найти конкретные странички с дублирующими заголовками и метатегами Description;
- Может находить изображения с отсутствующими и длинными атрибутами alt и title тега img;
- Выводит сведения по meta тэгам, которые управляют поисковыми ботами (краулерами);
- Возможность указывать размеры заголовков в символах и пикселях;
- Генерирует карту сайта в файл sitemap xml с множеством дополнительных настроек;
- Анализирует скорость и время загрузки web-страниц;
- Проверка массового перенаправления, сканер URL-адресов для переадресации;
- Настройка максимального размера страницы для обхода (в килобайтах);
- Наличие вкладки In Links, в ней можно посмотреть список страниц, которые ссылаются на указанный URL;
- Работа с конфигурациями Robots.txt (итоговый вариант будет считаться каноничным для парсера).
Представленные выше функции, являются лишь небольшой частью интегрированного инструментария. Примечательно, что программное обеспечение SF API Access поддерживает интеграцию с разными статистическими сервисами, включая Google Analytics или Majestic, благодаря чему вы сможете увидеть и просмотреть еще больше всевозможных данных и параметров.
Other Updates
Version 11.0 also includes a number of smaller updates and bug fixes, outlined below.
- The ‘URL Info’ and ‘Image Info’ lower window tabs has been renamed from ‘Info’ to ‘Details’ respectively.
- ‘Auto Discover XML Sitemaps via robots.txt’ has been unticked by default for list mode (it was annoyingly ticked by default in version 10.4!).
- There’s now a ‘Max Links per URL to Crawl’ configurable limit under ‘Config > Spider > Limits’ set at 10k max.
- There’s now a ‘Max Page Size (KB) to Crawl’ configurable limit under ‘Config > Spider > Limits’ set at 50k.
- There are new tool tips across the GUI to provide more helpful information on configuration options.
- The HTML parser has been updated to fix an error with unquoted canonical URLs.
- A bug has been fixed where GA Goal Completions were not showing.
That’s everything. If you experience any problems with the new version, then please do just let us know via support and we can help. Thank you to everyone for all their feature requests, bug reports and general support, Screaming Frog would not be what it is, without you all.
Now, go and download version 11.0 of the Screaming Frog SEO Spider.
Small Update – Version 10.1 Released 21st September 2018
We have just released a small update to version 10.1 of the SEO Spider. This release is mainly bug fixes and small improvements –
- Fix issue with no URLs displaying in the UI when ‘Respect Next/Prev’ is ticked.
- Stop visualisations popping to the front after displaying pop-ups in the main UI.
- Allow configuration dialogs to be resized for users on smaller screens.
- Update include & exclude test tabs to show the encoded URL that the regular expressions are run against.
- Fix a crash when accessing GA/GSC via the scheduling UI.
- Fix crash when running crawl analysis with no results.
- Make tree graph and force-directed diagram fonts configurable.
- Fix issue with bold and italic buttons not resetting to default on graph config panels.
Viewing Crawl Data
Data from the crawl populates in real-time within the SEO Spider and is displayed in tabs. The ‘‘ tab includes all data discovered in a crawl for the website being crawled. You can scroll up and down, and to the right to see all the data in various columns.

The tabs focus on different elements and each have filters that help refine data by type, and by potential issues discovered.
The ‘Response Codes’ tab and ‘Client Error (4xx) filter will show you any 404 pages discovered for example.

You can click on URLs in the top window and then on the tabs at the bottom to populate the lower window pane.
These tabs provide more detail on the URL, such as their inlinks (the pages that link to them), outlinks (the pages they link out to), images, resources and more.

In the example above, we can see inlinks to a broken link discovered during the crawl.
Установка программы
Скачать программу нужно на сайте автора: https://netpeaksoftware.com/ru/spider.
Установка простая и быстрая. Язык выбираем русский. После открытия программы нужно пройти регистрацию. Это тоже бесплатно. После регистрации вы получите на указанный почтовый ящик ключ авторизации. Вводим ключ и работаем.
- Вписываем URL исследуемого сайта. Жмем старт;
- После анализа манипулируем кнопками и смотрим анализ по нужному параметру;
- Фильтры результатов анализа достаточно разнообразны и понятны. Жмете на кнопки, списки перестраиваются;
- Что приятно, есть визуальная раскраска результатов. Удобно;
- Показ дублей страниц заказываем справа внизу. Дубли показываются по повторяющемуся тексту и показывают URL, где дубли присутствуют;
- Результаты анализа можно сохранить файлом Excel. В отличае от программы XENU повторно открыть файл в программе нельзя.
4) Configurable Accept-Language Header
Google introduced local-aware crawl configurations earlier this year for pages believed to adapt content served, based on the request’s language and perceived location.
This essentially means Googlebot can crawl from different IP addresses around the world and with an Accept-Language HTTP header in the request. Hence, like Googlebot, there are scenarios where you may wish to supply this header to crawl locale-adaptive content, with various language and region pairs. You can already use the proxy configuration to change your IP as well.
You can find the new ‘Accept-Language’ configuration under ‘Configuration > HTTP Header > Accept-Language’.
We have some common presets covered, but the combinations are huge, so there is a custom option available which you can just set to any value required.
4) AJAX Crawling
I’ve been asked quite a few times when we will support crawling of JavaScript frameworks such as AngularJS. While we don’t execute JavaScript, we will crawl a site which adheres to the Google AJAX crawling scheme.
You don’t need to do anything special to crawl AJAX websites, you can just crawl them as normal. We will fetch the ugly version and map it to the pretty version, just like Google.
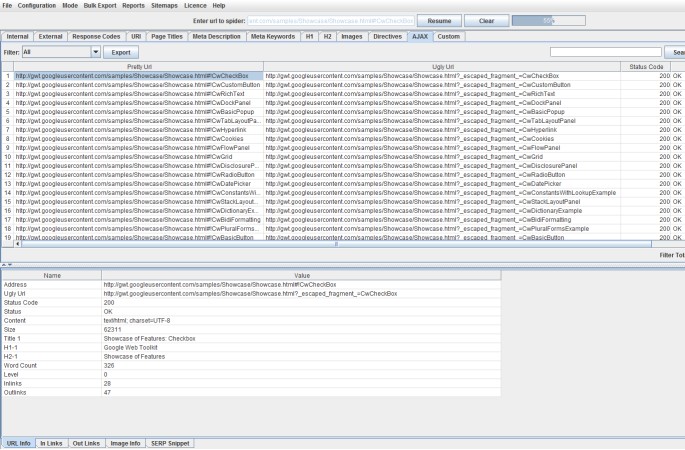
You can view this all under the ‘AJAX’ tab obviously.
There’s also a ‘with hash fragment’ and ‘without hash fragment’ filters for this tab. This can be useful to identify AJAX pages which only use the meta fragment tag and hence require Google to double crawl (to crawl the page, see the tag and then fetch the ugly version) which can put extra load on your servers.
What Is SEO?
Search Engine Optimisation (SEO) is the practice of increasing the number and quality of visitors to a website by improving rankings in the algorithmic search engine results.
Research shows that websites on the first page of Google receive almost 95% of clicks, and studies show that results that appear higher up the page receive an increased click through rate (CTR), and more traffic.
The algorithmic (‘natural’, ‘organic’, or ‘free’) search results are those that appear directly below the top pay-per-click adverts in Google, as highlighted below.
There are also various other listings that can appear in the Google search results, such as map listings, videos, the knowledge graph and more. SEO can include improving visibility in these result sets as well.
5) Improved UX Bits
We’ve found some new users could get confused between the ‘Enter URL to spider’ bar at the top, and the ‘search’ bar on the side. The size of the ‘search’ bar had grown, and the main URL bar was possibly a little too subtle.
So we have adjusted sizing, colour, text and included an icon to make it clearer where to put your URL.
If that doesn’t work, then we’ve got another concept ready and waiting for trial.
The ‘Image Details’ tab now displays a preview of the image, alongside its associated alt text. This makes image auditing much easier!
You can highlight cells in the higher and lower windows, and the SEO Spider will display a ‘Selected Cells’ count.
The lower windows now have filters and a search, to help find URLs and data more efficiently.
Site visualisations now have an improved zoom, and the tree graph nodes spacing can be much closer together to view a site in its entirety. So pretty.
Oh, and in the ‘View Source’ tab, you can now click ‘Show Differences’ and it will perform a diff between the raw and rendered HTML.
1) Near Duplicate Content
You can now discover near-duplicate pages, not just exact duplicates. We’ve introduced a new ‘Content‘ tab, which includes filters for both ‘Near Duplicates’ and ‘Exact Duplicates’.
While there isn’t a duplicate content penalty, having similar pages can cause cannibalisation issues and crawling and indexing inefficiencies. Very similar pages should be minimised and high similarity could be a sign of low-quality pages, which haven’t received much love – or just shouldn’t be separate pages in the first place.
For ‘Near Duplicates’, the SEO Spider will show you the closest similarity match %, as well as the number of near-duplicates for each URL. The ‘Exact Duplicates’ filter uses the same algorithmic check for identifying identical pages that was previously named ‘Duplicate’ under the ‘URL’ tab.
The new ‘Near Duplicates’ detection uses a minhash algorithm, which allows you to configure a near-duplicate similarity threshold, which is set at 90% by default. This can be configured via ‘Config > Content > Duplicates’.
Semantic elements such as the nav and footer are automatically excluded from the content analysis, but you can refine it further by excluding or including HTML elements, classes and IDs. This can help focus the analysis on the main content area, avoiding known boilerplate text. It can also be used to provide a more accurate word count.
Near duplicates requires post crawl analysis to be populated, and more detail on the duplicates can be seen in the new ‘Duplicate Details’ lower tab. This displays every near-duplicate URL identified, and their similarity match.
Clicking on a ‘Near Duplicate Address’ in the ‘Duplicate Details’ tab will display the near duplicate content discovered between the pages, and perform a diff to highlight the differences.
The near-duplicate content threshold and content area used in the analysis can both be updated post-crawl, and crawl analysis can be re-run to refine the results, without the need for re-crawling.
The ‘Content’ tab also includes a ‘Low Content Pages’ filter, which identifies pages with less than 200 words using the improved word count. This can be adjusted to your preferences under ‘Config > Spider > Preferences’ as there obviously isn’t a one-size-fits-all measure for minimum word count in SEO.
Read our ‘How To Check For Duplicate Content‘ tutorial for more.
Regex Examples
Jump to a specific Regex extraction example:
Google Analytics and Tag Manager IDs
To extract the Google Analytics ID from a page the expression needed would be –
For Google Tag Manager (GTM) it would be –
The data extracted is –
Structured Data
If the structured data is implemented in the JSON-LD format, regular expressions rather than XPath or CSS Selectors must be used:
To extract everything in the JSON-LD script tag, you could use –
Email Addresses
The following will return any alpha numeric string, that contains an @ in the middle:
The following expression will bring back fewer false positives, as it requires at least a single period in the second half of the string:
That’s it for now, but I’ll add to this list over time with more examples, for each method of extraction.
As always, you can pop us through any questions or queries to our support.